 02.Eureka注册中心
02.Eureka注册中心
# 01.注册中心原理
# 1.1 为什么需要注册中心
在RPC服务和微服务诞生的时候,就已经有了注册中心的需求了。
在最初的架构体系中,集群的概念还不那么流行,且机器数量也比较少
此时直接使用DNS+Nginx就可以满足几乎所有RESTful服务的发现,相关的注册信息直接配置在Nginx。但是随着微服务的流行与流量的激增,机器规模逐渐变大,并且机器会有频繁的上下线行为
这种时候需要
运维手动地去维护这个配置信息是一个很麻烦的操作。所以开发者们开始希望有这么一个东西,它能维护一个服务列表,哪个机器上线了,哪个机器宕机了
这些信息都会
自动更新到服务列表上,客户端拿到这个列表,直接进行服务调用即,这个就是注册中心
# 1.2 注册中心原理
注册中心主要涉及到三大角色
- 服务提供者
- 服务消费者
- 注册中心
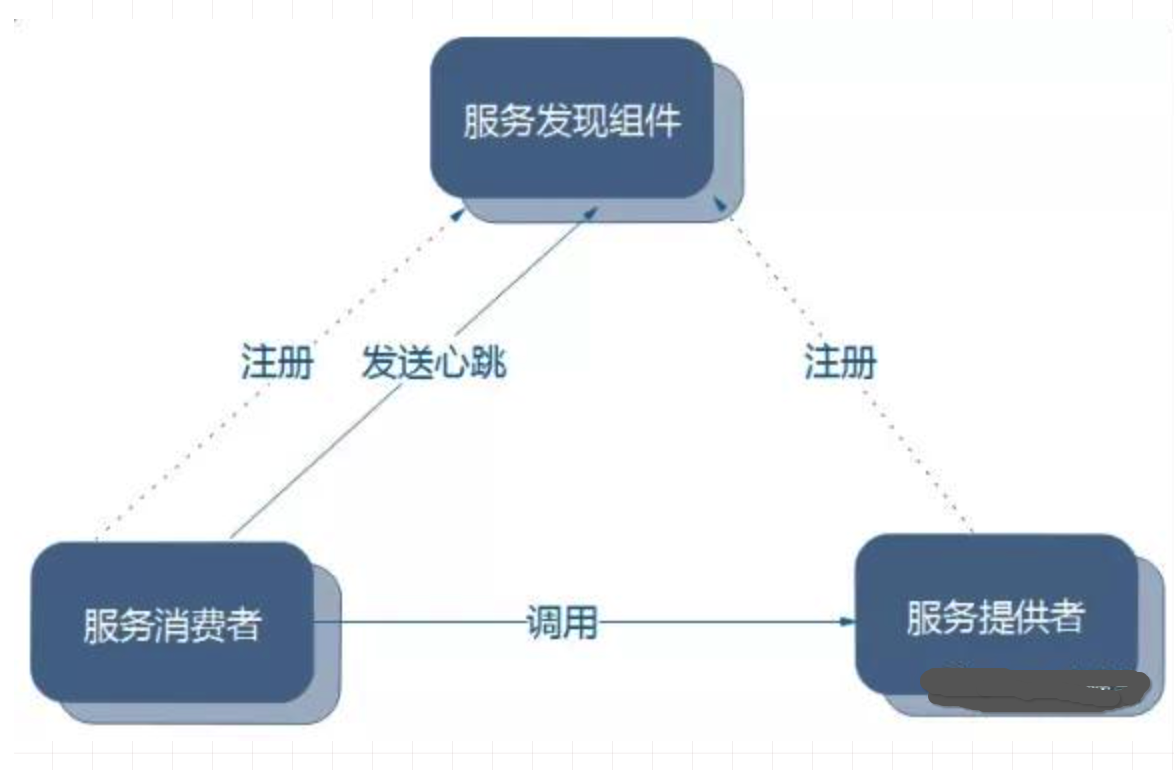
它们之间的关系大致如下
- 各个微服务在启动时,将自己的网络地址等信息注册到注册中心,注册中心存储这些数据。
- 服务消费者从注册中心查询服务提供者的地址,并通过该地址调用服务提供者的接口。
- 各个微服务与注册中心使用一定机制(例如心跳)通信。如果注册中心与某微服务长时间无法通信,就会注销该实例。
- 微服务网络地址发送变化(例如实例增加或IP变动等)时,会重新注册到注册中心。
- 这样,服务消费者就无需人工修改提供者的网络地址了。
注册中心的架构图如下
# 1.3 注册中心功能
1)服务注册表- 服务注册表是注册中心的核心,它用来记录各个微服务的信息,例如微服务的名称、IP、端口等。
- 服务注册表提供查询API和管理API,查询API用于查询可用的微服务实例,管理API用于服务的注册与注销
2)服务注册与发现- 服务注册是指微服务在启动时,将自己的信息注册到注册中心的过程。
- 服务发现是指查询可用的微服务列表及网络地址的机制。
3)服务检查- 注册中心使用一定的机制定时检测已注册的服务,如发现某实例长时间无法访问,就会从服务注册表移除该实例。
# 02.Eureka注册中心
# 2.1 Eureka图解
- 第一:服务注册
- user和product两个微服务,在启动时将自己的 名称、IP、端口等注册到 Eureka服务端
- 第二:服务发现
- user微服务要访问产品微服务,会请求Eureka服务端,Eureka返回 user微服务注册的 ip:端口 列表
- user微服务根据负载均衡策略选择其中一个 ip:端口 来访问 product产品微服务
- 第三:服务检查
- 在应用启动后,将会向Eureka Server发送心跳,默认周期为30秒
- 如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,Eureka Server将会从服务注册表中把这个服务节点移除(默认90秒)

# 2.2 Eureka介绍
- Eureka是Netflix开发的服务发现框架,本身是一个基于REST的服务,主要用于定位运行在AWS域中的中间层服务,以达到负载均衡和中间层服务故障转移的目的。
- SpringCloud将它集成在其子项目spring-cloud-netflix中,以实现SpringCloud的服务发现功能。
- Eureka重要概念
- Register(服务注册):把自己的IP和端口注册给Eureka。
- Renew(服务续约):发送心跳包,每30秒发送一次。告诉Eureka自己还活着。
- Cancel(服务下线):当provider关闭时会向Eureka发送消息,把自己从服务列表中删除。防止consumer调用到不存在的服务。
- Get Registry(获取服务注册列表):获取其他服务列表。
- Replicate(集群中数据同步):eureka集群中的数据复制与同步。
- Make Remote Call(远程调用):完成服务的远程调用。
# 2.3 Eureka组价功能
Eureka包含两个组件:Eureka Server和Eureka Client。
Eureka Server
- Eureka Server提供服务注册服务,各个节点启动后,会在Eureka Server中进行注册
- 这样Eureka Server中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到。
Eureka Client
- Eureka Client是一个java客户端,用于简化与Eureka Server的交互
- 客户端同时也具备一个内置的、使用轮询(round-robin)负载算法的负载均衡器。
- 在应用启动后,将会向Eureka Server发送心跳,默认周期为30秒,如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳
- Eureka Server将会从服务注册表中把这个服务节点移除(默认90秒)。
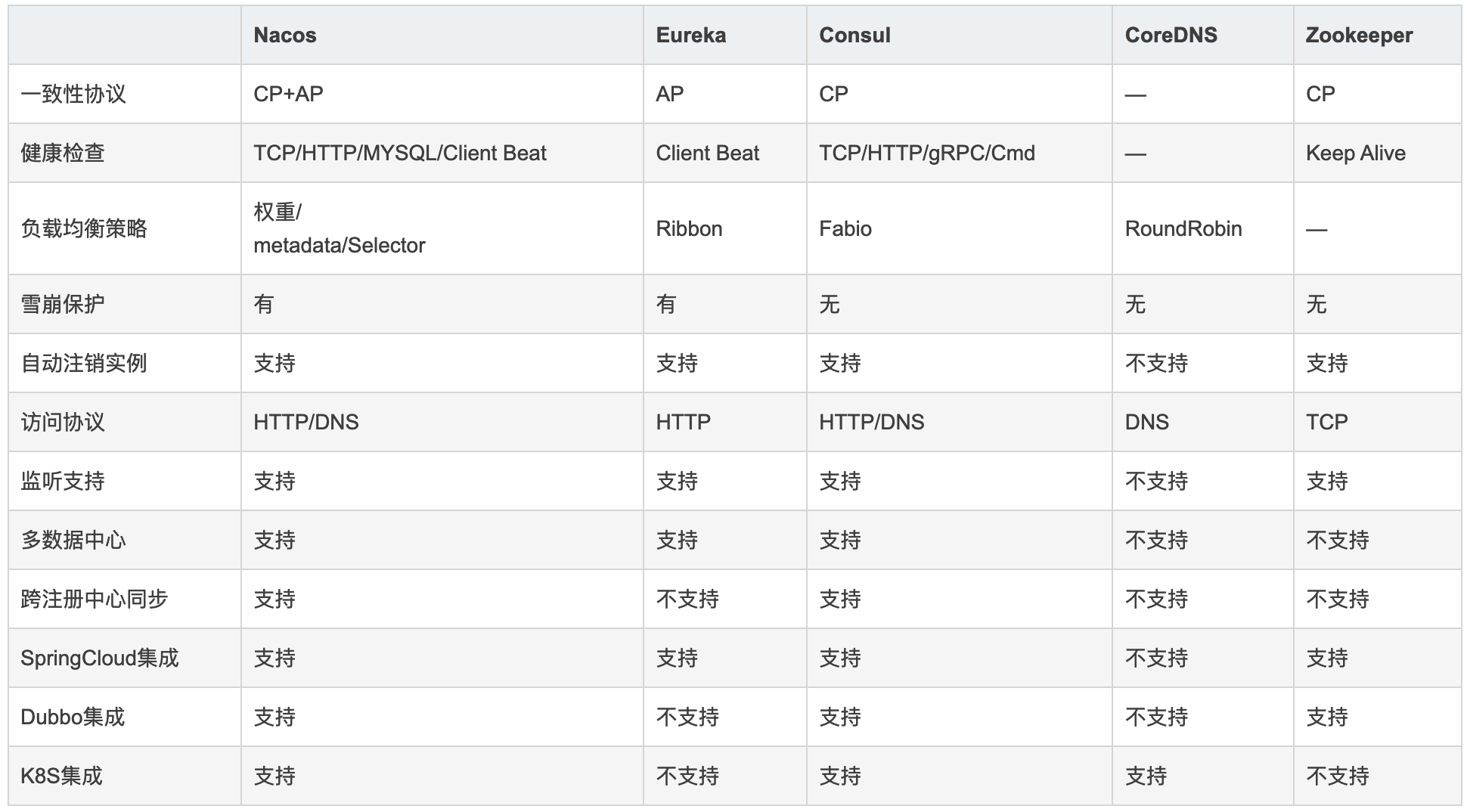
# 03.常用注册中心比较
#  3.0 CAP理论
3.0 CAP理论
C(Consistency)这里指的是强一致性
保证在一定时间内,集群中的各个节点会达到较强的一致性,同时,为了达到这一点,一般会牺牲一点响应时间。- 而放弃C也不意味着放弃一致性,而是放弃强一致性,允许系统内有一定的数据不一致情况的存在
A (Avalibility):可用性
- 意味着系统一直处于可用状态,个别节点的故障不会影响整个服务的运作
P(Partition Tolerance):分区容忍性
- 当系统出现网络分区等情况时,依然能对外提供服务。
- 想到达到这一点,一般来说会把数据复制到多个分区里,来提高分区容忍性。这个一般是不会被抛弃的
# 3.1 Zookeeper
特点:
- 1)牺牲可用性,保证一致性
- 2)主从模式,无配置管理
Apache Zookeeper所选择的是CP,也就是放弃了高可用性。
为了达到C,Zookeeper采用的是自己的ZAB协议。
总得来说,Zookeeper集群在进行消息同步的时候,必须有一半以上结点完成了同步才会返回;
而当Master结点挂了或者集群中有过半的结点不能工作了,此时就会触发故障恢复,重新进行Master选举。
在这个过程中,整个Zookeeper集群无法对外提供服务,从而失去了A(可用性)
牺牲服务可用性、保证数据一致性
- 对于大多数的分布式环境来说,特别是数据储存的环境,数据一致性是非常重要的标准。
- 但对于服务发现来说,其实并没有那么严格。
- 就算一个注册中心没有及时获取到实时的服务实例状态,直接把服务列表(可能存在错误)发给客户端,也不会导致灾难性的错误。
- 因为对于客户端来说会有重试机制,少数的实例无法访问不会导致大问题。
# 3.2 Eureka
特点:
- 1)牺牲一致性,保证可用性
- 2)无主从模式,无配置管理
Spring Cloud Eureka所选择的是AP,放弃了强一致性。
从使用角度来看,Eureka的特点就是使用Java语言来开发的,并且也是Spring Cloud的子项目
所以可以直接通过引入jar包的方式来集成Eureka,这点非常方便
而在架构上,Eureka集群采用的是去中心化结构,也就是说Eureka集群中的各个结点都是平等的,
没有主从的概念。通过互相注册的方式来进行消息同步和保证高可用。
并且一个Eureka Server结点挂掉了,还有其他同等的结点来提供服务,并不会引发服务的中断。
保证可用性,牺牲强一致性
但同样的也会带来一定的不一致性。但是之前也说了,在服务注册这种场景,一致性的要求其实并没有很高
另外,Eureka还有一个自我保护机制,用来应对网络问题导致的服务不可用,从而能更进一步地保证可用性。
# 3.3 Consul
特点:
- 1)牺牲可用性,保证一致性
- 2)主从模式,有配置管理
Consul是HashiCorp公司推出的一个开源工具。
它和Eureka一个区别就似乎,
Consul是用Go语言编写的,所以无法像Eureka那样直接引入jar包就能集成,它还需要去服务器中进行额外的安装。Consul的功能相比于Eureka来说也更加强大,因为除了注册中心的功能之外,
Consul还能起到配置中心的作用。而Eureka只能当注册中心,想搞配置中心的话,还得搭配Spring Cloud Config+Spring Cloud Bus。
牺牲服务可用性、保证数据一致性
- Consul它保证的是CP,使用raft协议,要求必须有过半的结点都写入成功才算是注册成功了
- 并且它也有Master和Follower的概念,在Master挂掉后,也需要自己内部进行新一轮Master选举,在此期间,Consul服务不可用
# 3.4 Nacos
特点:
- 1)强一致性和强可用性,可以自己选择
- 2)无主从模式,有配置中心
Nacos是阿里巴巴旗下的开源项目,在2018年开源,是Spring Cloud Alibaba的子项目。
Nacos一大特性是即支持CP,也支持AP,可以根据需要灵活选择。
Nacos除了注册中心之外,也能充当配置中心的作用。
且配置中心可以按照namespace,group等维度来进行数据隔离,来达到不同环境之间配置隔离的功能。
另外值得一提的是,Nacos作为配置中心的持久化机制可以依赖于Mysql来完成(默认依赖于内置数据库)。
只需要将Nacos目录下的sql脚本放到mysql中执行(会生成11个表),然后在nacos配置文件里面配一下mysql的账号密码即可。
这样使用mysql作为数据源的方式相比于nacos内置数据库来说更容易管理