 01.docker原理
01.docker原理
# 01.namespace
# 0、简介
Namespace(
资源隔离)- Namespace是将内核的
全局资源做封装,使得每个Namespace都有一份独立的资源 - 因此不同的进程在各自的Namespace内对同一种资源的使用不会互相干扰
- Namespace是将内核的
Cgroup(
资源限制)- Cgroup是内核提供的一种资源隔离的机制,可以实现
对进程所使用的cpu、内存物理资源、及网络带宽等进行限制 - 还可以通过分配的CPU时间片数量及磁盘IO宽带大小控制任务运行的优先级
- Cgroup是内核提供的一种资源隔离的机制,可以实现
# 1、namespace介绍
- Namespace 是 Linux 提供的一种
内核级别的资源隔离机制 - 它允许不同进程在同一主机中互相隔离并使用相同的资源名称
- 命名空间通过创建独立的资源视图,使每个进程只感知它所属命名空间内的资源
- Linux 内核支持六种命名空间,分别是
网络、进程、挂载、UTS、IPC、用户- Network Namespace:将网络设备、路由表等隔离
- PID Namespace:使进程ID(PID)在不同的命名空间里相互独立
- Mount Namespace:为文件系统挂载点提供隔离
- UTS Namespace:允许隔离主机名和域名
- IPC Namespace:隔离进程间通信资源
- User Namespace:隔离用户和组ID
- Docker 借助这些命名空间来实现容器的资源隔离
- 使得每个容器都有自己独立的进程、网络栈等,从而实现轻量级虚拟化
# 2、namespace实现原理
# 1)struct nsproxy结构体
- 每个进程都与特定的命名空间相关联
- Linux 内核通过在进程描述符中添加
nsproxy结构体来管理命名空间 nsproxy负责管理进程所属的多个命名空间- 使得一个进程可以同时隶属于不同类型的命名空间,如 PID、网络、挂载等
- 每种命名空间类型对应一个结构体
- 如
pid_namespace用于管理进程ID隔离,mnt_namespace用于管理挂载点隔离等
- 如
struct task_struct {
...
/* namespaces */
struct nsproxy *nsproxy;
...
}
struct nsproxy {
atomic_t count;
struct pid_namespace *pid_ns;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct user_namespace *user_ns;
struct net *net_ns;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 2) struct pid_namespace 结构
pid_namespace是 PID 命名空间的核心结构,用于管理进程 ID- 其设计支持多级嵌套命名空间,并确保每个命名空间中的 PID 相互独立
- 关键字段(树中每个节点包含这些信息):
kref: 引用计数,表示有多少进程正在使用该命名空间pidmap: 位图,用于快速查找空闲的 PIDlast_pid: 记录最后分配的 PIDlevel: 命名空间的层级,用于标识嵌套关系parent: 父级命名空间,支持多级嵌套
struct pid_namespace {
struct kref kref;
struct pidmap pidmap[PIDMAP_ENTRIES];
int last_pid;
struct task_struct *child_reaper;
struct kmem_cache *pid_cachep;
unsigned int level;
struct pid_namespace *parent;
#ifdef CONFIG_PROC_FS
struct vfsmount *proc_mnt;
#endif
};
2
3
4
5
6
7
8
9
10
11
12
- 由于
pid命名空间是分层的,也就是说新创建一个pid命名空间时会记录父级pid命名空间到parent字段中 - 所以随着
pid命名空间的创建,在内核中会形成一颗pid命名空间的树- 第0层的
pid命名空间是init进程所在的命名空间 - 如果一个进程所在的
pid命名空间为N,那么其在0 ~ N 层pid命名空间都有一个唯一的pid号 - 也就是说
高层pid命名空间的进程对低层pid命名空间的进程是可见的 - 但是
低层pid命名空间的进程对高层pid命名空间的进程是不可见的
- 第0层的
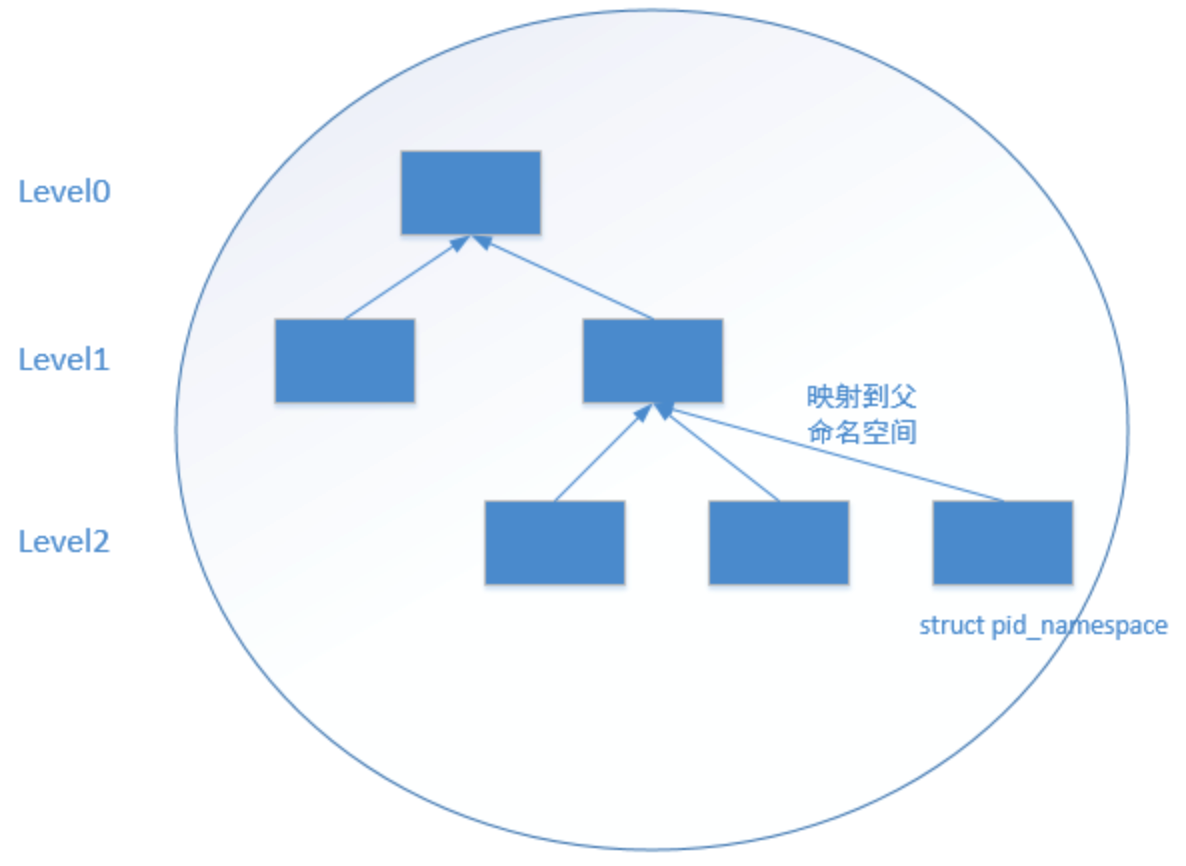
# 3、namespace结构拆解
这里以
pid_namespace(进程ID)的树形结构推演namespace每个容器中的进程在容器内部拥有自己的 PID 空间,与宿主机中的 PID 独立
然而,宿主机可以查看容器内部的所有进程,因为宿主机的 PID 命名空间是容器的父级命名空间
举例说明
宿主机上有一个进程
docker daemon,PID 为1001,它启动了两个容器container1和container2container1 内的第一个进程是容器内部的
init进程,PID 为 1该进程在宿主机上的 PID 是 2001container2 内的第一个进程也是
init进程,PID 为 1,宿主机上对应的 PID 为 3001
那么对应的 pid namespance结构如下
宿主机 pid_namespace (level 0, last_pid = 3001) # 宿主机命名空间(level 0)
│
├── docker daemon (PID 1001, 宿主机内)
├── container1 pid_namespace (level 1, parent = 宿主机, last_pid = 1) # container1 的命名空间(level 1)
│ └── init (PID 1 in container1, 宿主机 PID = 2001)
│
└── container2 pid_namespace (level 1, parent = 宿主机, last_pid = 1) # container2 的命名空间(level 1)
└── init (PID 1 in container2, 宿主机 PID = 3001)
2
3
4
5
6
7
8
- 宿主机的命名空间(level 0)中包含了
docker daemon进程以及容器中的所有进程在宿主机的 PID 映射 - 每个容器都有自己的
pid_namespace,在这个命名空间中,init进程的 PID 是 1,并且这个 PID 与宿主机中的进程无关 - 宿主机能够看到容器内部的所有进程,但容器无法看到宿主机或其他容器的进程
- 通过这种结构,
docker daemon的作用变得清晰- 它位于宿主机的命名空间中,负责管理容器,并与容器的
pid_namespace进行关联
- 它位于宿主机的命名空间中,负责管理容器,并与容器的
# 02.CGroup
# 1、CGroup 概述
- CGroup(Control Group)是 Linux 内核用于对进程进行资源限制和管理的功能
- 它允许将进程分组,并对每个组的 CPU、内存、网络等资源进行限制、监控和隔离
- Docker 使用 CGroup 实现容器的资源限制
- 主要功能:
- 资源限制:控制进程组能够使用的 CPU、内存、磁盘等资源的上限
- 优先级控制:为不同的进程组设置优先级,如为某组分配更多 CPU 份额
- 资源使用统计:记录进程组使用的 CPU、内存等资源情况
- 资源隔离:将不同进程组在资源上相互隔离,避免干扰
- 进程组管理:支持冻结和恢复某个进程组的执行状态
# 2、CGroup 提供的功能
资源限制(Resource Limiting):
- 比如,
memory子系统可以为某个进程组设定内存使用上限,一旦超出就会触发 OOM(内存不足)
- 比如,
优先级控制(Prioritization):
cpu子系统可以为不同进程组分配不同的 CPU 份额
资源计量(Accounting):
cpuacct子系统记录进程组使用的 CPU 时间,便于统计和监控
进程隔离(Isolation):
ns子系统可以让不同进程组使用独立的命名空间,达到资源隔离的目的
控制功能(Control):
freezer子系统允许将某个进程组挂起或恢复
# 3、CGroup 相关核心概念
任务(Task):
- 在 CGroup 中,任务就是系统中的一个进程
控制组(Control Group):
- 是按照某种标准划分的一组进程,CGroup 通过控制组来管理资源,限制或监控某个控制组的资源使用
层级(Hierarchy):
- 控制组可以形成树状层级结构,子控制组继承父控制组的属性,子控制组可以有独立的资源限制
子系统(Subsystem):
每个子系统对应一个资源控制器,如
cpu子系统用于控制 CPU 时间,memory子系统用于控制内存使用子系统附加到层级树上时,会对树中的所有控制组生效
# 03.Docker实现本质
- Docker 利用 命名空间(Namespace) 和 控制组(CGroup) 实现了
容器的隔离与资源管理
# 0、容器运行要素
- 容器(如 Docker)之所以能在一个宿主机上运行多个实例,依赖于 Linux 的三大核心机制
| 机制 | 作用 | 解决问题 |
|---|---|---|
| Namespace | 资源隔离 | 保证每个容器“以为”自己独占系统 |
| Cgroup | 资源限制/调度 | 控制资源使用上限和调度公平性 |
| Filesystem (chroot + overlayfs) | 文件隔离 | 提供只属于容器的文件系统视图 |
# 1、命名空间应用
- 命名空间(Namespace)在 Docker 中的应用
- Docker 使用命名空间为每个容器提供了一个隔离的资源视图
- 使得容器看起来像是一个独立的操作系统环境
# 1)PID(进程隔离)
作用:
隔离进程 ID,使得容器内的进程与其他容器或宿主机的进程分开- 每个容器都有自己的进程编号空间,容器中的进程从 PID 1 开始(通常是容器内的
init进程)
例子:
宿主机上可能有多个容器,每个容器中的
PID 1都是独立的- 容器 A 中有一个进程,它的 PID 是 1
- 容器 B 中也有一个进程,它的 PID 也是 1
- 宿主机上可能还有其他进程,它们有不同的 PID
由于使用了 PID 命名空间,容器 A 和容器 B 都认为它们的 PID 1 是系统的第一个进程
而看不到宿主机或其他容器中的进程
# 2)Network(网络隔离)
- 作用:
- 隔离网络资源,每个容器都有自己的网络设备(如虚拟网卡)、IP 地址、路由表等
- 这使得容器之间的网络环境相互独立,除非显式连接
- 例子:
- 每个容器都有自己的虚拟网卡和独立的 IP 地址
- 容器 A 的 IP 地址可能是
172.17.0.2 - 容器 B 的 IP 地址可能是
172.17.0.3
- 容器 A 的 IP 地址可能是
- 宿主机上的网络和容器 A、容器 B 之间是隔离的
- 除非通过 Docker 提供的网络接口或桥接网络显式地连接
- 每个容器都有自己的虚拟网卡和独立的 IP 地址
# 3)Mount(文件系统隔离)
- 作用:
- 每个容器有自己独立的文件系统视图,可以挂载独立的文件系统或只访问特定的目录
- 宿主机和其他容器的文件系统是相互隔离的,除非使用卷(volumes)进行数据共享
- 例子:
- 容器 A 中看到的文件系统是特定镜像中的内容,而不会看到宿主机或其他容器的文件
- 比如,宿主机的
/var/www/html目录不会自动出现在容器中 - 除非通过 Docker 的
-v参数将该目录挂载到容器的某个路径
# 4)User(用户隔离)
- 作用:
- 实现用户和组的隔离,容器可以有独立的用户 ID 和组 ID
- 宿主机上的 root 用户和容器中的 root 用户不等同
- 例子:
- 容器中的 root 用户拥有对容器内部所有文件的权限
- 但在宿主机上,该用户并不拥有实际的 root 权限,增强了安全性
# 5)IPC(进程间通信隔离)
- 作用:隔离容器间的进程间通信资源(如信号量、消息队列、共享内存等)
- 例子:
- 容器 A 和容器 B 都有各自的 IPC 资源
- 容器 A 的进程无法访问容器 B 的共享内存或消息队列,除非明确设置共享通信
# 6)UTS(域名隔离)
- 作用:
- 为每个容器隔离主机名和域名
- 容器可以有自己独立的主机名,而不会影响其他容器或宿主机
- 例子:
- 容器 A 的主机名可以是
containerA,容器 B 的主机名可以是containerB - 而宿主机的主机名可能是
host123,三者互不影响
- 容器 A 的主机名可以是
# 2、CGroup 应用
- Docker 通过 CGroup 控制容器的资源使用情况
- 确保每个容器只消耗指定的 CPU、内存等资源
- 避免单个容器过度占用系统资源,影响其他容器或宿主机
# 1)CPU 资源控制
作用:Docker 可以使用 CGroup 的
cpu子系统来限制容器使用的 CPU 时间,防止某个容器占用过多的 CPU 资源例子:
当创建容器时,可以指定容器使用的 CPU 份额:
docker run --cpu-shares=512 ubuntu1上述命令启动了一个 Ubuntu 容器,并限制其 CPU 使用份额为 512
默认值为 1024,因此该容器的 CPU 份额为默认容器的 50%
# 2)内存 资源控制
作用:
- 通过 CGroup 的
memory子系统,Docker 可以限制容器使用的内存 - 如果容器的内存使用超过设定的限制,CGroup 会触发 OOM(Out of Memory)错误并终止容器
- 通过 CGroup 的
例子:
限制容器的内存使用为 256MB
docker run -m 256m ubuntu1这意味着容器内的所有进程共享 256MB 的内存,如果超过这个限制,容器将会被停止
# 3)I/O 资源控制
作用:
- CGroup 还可以控制容器的块设备 I/O 使用
- 防止某些容器对磁盘或存储设备的过度使用,从而影响其他容器的性能
例子:
限制容器的 I/O 带宽:
docker run --device-write-bps /dev/sda:1mb ubuntu1该命令限制了容器对
/dev/sda设备的写入速度为 1MB/秒
# 4)网络带宽 控制
作用:Docker 也可以通过 CGroup 的
net_cls和net_prio子系统来限制和优先化容器使用的网络带宽例子:
限制容器的网络上传速率:
docker run --netem rate 1mbit ubuntu1这个命令限制容器的网络上传速率为 1 Mbit/s,防止某个容器占用太多网络带宽