 01.排序算法
01.排序算法
# 01.LowB三人组
# 1、冒泡
- **原理:**拿自己与上面一个比较,如果上面一个比自己小就将自己和上面一个调换位置,依次再与上面一个比较
- 第一轮结束后最上面那个一定是最大的数
python版
import random
def bubble_sort(li):
for i in range(len(li) - 1):
exchange = False
for j in range(len(li) - i -1): #内层for循环执行一次,选出一个最大值,将可以调换位置的数调整
if li[j] > li[j + 1]:
li[j],li[j+1] = li[j+1],li[j]
exchange = True
if not exchange: # 如果上一趟没有发生交换就证明已经排序完成
break
data = list(range(100))
random.shuffle(data) #将有序列表打乱
bubble_sort(data)
print(data)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
golang版
package main
import "fmt"
func main() {
nums := []int{3,5,4,1,6,2}
ret := bubble_sort(nums)
fmt.Println(ret)
}
func bubble_sort(nums []int) []int {
for i:=0; i<len(nums); i++ {
// 内层for循环执行一次,选出一个最大值,将可以调换位置的数调整
for j := 0; j < len(nums) - i - 1; j++ {
if nums[j] > nums[j+1] {
nums[j], nums[j+1] = nums[j+1], nums[j]
}
}
}
return nums
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 2、选择
- 1、先假定第一个是最小的,依次与其他数比,如果其他数中有比第一个数小就假定这个更小的最小
- 2、再比,第一轮就可以找到最小的那个放到0号位置,然后在假定1号位置数最小与剩下比较,再找到第二小的数放到第1号位置
import random
def select_sort(li):
for i in range(len(li) - 1):
min_loc = i #开始先假设0号位置的值最小
for j in range(i+1, len(li)): #循环无序区,依次比较,小于min_loc就暂定他的下标最小
if li[j] < li[min_loc]: #所以内层for循环每执行一次就选出一个小值
min_loc = j
li[i], li[min_loc] = li[min_loc],li[i]
li = [1,5,2,6,3,7,4,8,9,0]
select_sort(li)
print(li) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
# 3、插入
- 1、列表被分为有序区和无序区两个部分,最初有序区只有一个元素
- 2、每次从无序区选择一个元素,插入到有序区的位置,直到无序区变空
import random
def insert_sort(li):
for i in range(1, len(li)):
tmp = li[i] #tmp是无序区取出的一个数
j = i - 1 #li[j]是有序区最大的那个数
while j >= 0 and li[j] > tmp:
# li[j]是有序区最大的数,tmp是无序区取出的一个数,tmp从有序区最大的那个数开始比
# 小就调换位置,直到找到有序区中值不大于tmp的结束
li[j+1]=li[j] #将有序区最右边的数向右移一个位置
j = j - 1
li[j + 1] = tmp #将tmp放到以前有序区最大数的位置,再依次与前一个数比较
data = list(range(100))
random.shuffle(data) #将有序列表打乱
insert_sort(data)
print(data)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 02.快排
# 1、快排-递归
**注:**快排代码实现(类似于二叉树 递归调用)----右手左手一个慢动作,左手右手一个慢动作重播
空间复杂度 O(1)
class Solution:
def quickSort(self, nums):
def partition(low, high):
p = nums[low] # 选择最左边的数作为基准
l, r = low, high
while l < r:
while l < r and nums[r] >= p:
r -= 1
nums[l] = nums[r] # 右侧较小值填充左侧空位
while l < r and nums[l] <= p:
l += 1
nums[r] = nums[l] # 左侧较大值填充右侧空位
nums[l] = p # l == r, p 的最终位置确定
return l # 返回 p 的最终索引
def quick_sort(low, high):
# 递归结束条件是 low >= high,数组长度 ≤ 1,无需再拆分排序
if low < high:
idx = partition(low, high) # 分区索引
quick_sort(low, idx - 1) # 递归排序左侧部分
quick_sort(idx + 1, high) # 递归排序右侧部分
quick_sort(0, len(nums) - 1)
return nums
print(Solution().quickSort([3, 2, 1, 5, 6, 4])) # 输出: [1, 2, 3, 4, 5, 6]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 2、快排-简单
- 空间复杂度高(
O(N)):需要开辟新的列表存储
def quick(list):
if len(list) < 2:
return list
tmp = list[0] # 临时变量 可以取随机值
left = [x for x in list[1:] if x <= tmp] # 左列表
right = [x for x in list[1:] if x > tmp] # 右列表
return quick(left) + [tmp] + quick(right)
li = [4,3,7,5,8,2]
print quick(li) # [2, 3, 4, 5, 7, 8]
#### 对[4,3,7,5,8,2]排序
'''
[3, 2] + [4] + [7, 5, 8] # tmp = [4]
[2] + [3] + [4] + [7, 5, 8] # tmp = [3] 此时对[3, 2]这个列表进行排序
[2] + [3] + [4] + [5] + [7] + [8] # tmp = [7] 此时对[7, 5, 8]这个列表进行排序
'''
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 3、快排-非递归
def quick_sort(arr):
# 使用栈来模拟递归调用,栈中存储的是需要排序的子数组的起始和结束索引
stack = [(0, len(arr) - 1)]
# 当栈不为空时,继续处理
while stack:
# 从栈顶取出一个子数组的起始和结束索引
low, high = stack.pop()
# 如果当前子数组的长度小于2,则无需排序
if low >= high:
continue
# 初始化指针
l, r = low, high
# 选择第一个元素作为基准值
pivot = arr[l]
# 开始进行 partition 操作
while l < r:
# 从右向左移动,寻找第一个小于基准值的元素
while l < r and arr[r] >= pivot:
r -= 1
if l < r:
arr[l] = arr[r]
# 从左向右移动,寻找第一个大于或等于基准值的元素
while l < r and arr[l] < pivot:
l += 1
if l < r:
arr[r] = arr[l]
# 将基准值放置在最终位置
arr[l] = pivot
# 将子数组的左右两部分的索引范围分别压入栈中
stack.append((low, l - 1)) # 左边部分
stack.append((l + 1, high)) # 右边部分
if __name__ == "__main__":
arr = [3, 5, 4, 1, 6, 2]
quick_sort(arr)
print(arr) # 输出: [1, 2, 3, 4, 5, 6]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# 4、快排分析
- 快排代码的第一句便是选取基准点,此后数据的移动根据这个基准点的大小进行调整
- 如果基准点选取的不好,将会导致快排的效率低下
- 经过测试,普通的快排算法针对
- (1)近乎有序的数列;
- (2)含有大量重复数据的数列;
- 这两种情况时效率将会变得非常低,针对这些情况,经过适当的优化可以使快排达到很高的效率。
# 5、三数取中优化
- 对于一个近乎有序的数列,当直接使用第一个元素作为基准点的时候,将会导致下图的情况
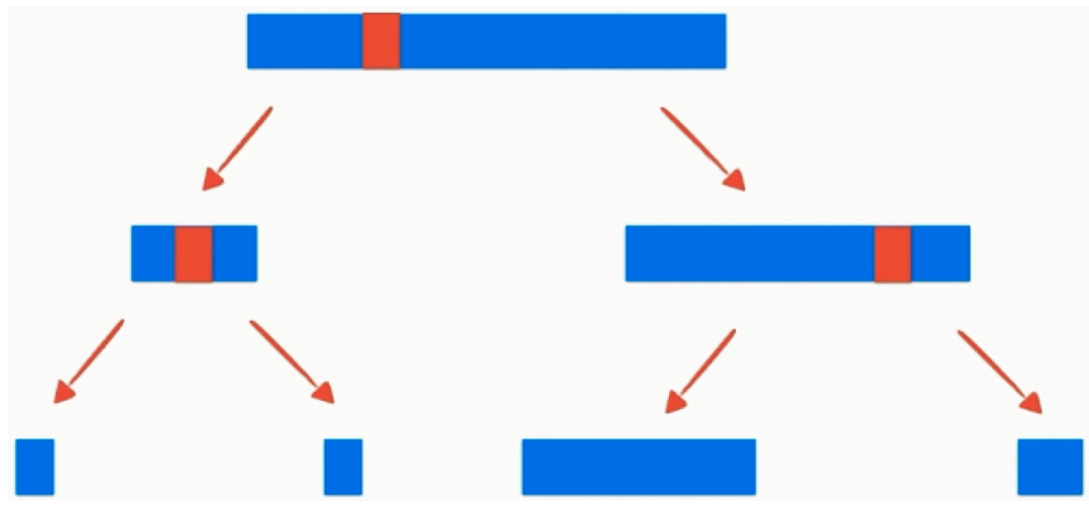
- 三数取中法:
- 选取基准点之前我们可以拿出数列中间位置元素的值,将它和首尾的元素进行比较
- 之后将这三个数中的中间大的数交换到数列首位的位置
- 之后将这个数作为基准点,尽量减小之后的分区后左右两边的区间长度之差。
# 6、有大量重复元素的情况
比如随机生成一个含有15万个数据的数组,范围是从0~10
那么数组中将含有非常多的重复数据,对这个数组使用上述的快排排序时,时间几乎又是回到了O(n^2)的级别
针对这种情况,需要对分区操作做适当的修改
思路是将小于基准点的数全部放到左边,大于基准点的数全部放到右边
# 03.堆排
# 1、堆的定义
1、堆中某个节点的值总是不大于或不小于其父节点的值;
2、堆总是一棵完全二叉树
3、完全二叉树定义:
1)若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数 2)第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
4、完全二叉树特性
1)一个高度为h的完全二叉树最多有 2n -1 个节点
2)根为 i 号节点,左孩子 为 2i、 右孩子为 2i+1,父亲节点 (i – 1) / 2
3)一个满二叉树 第 m层节点个数 等于 2m-1 个
4)推倒一个h层的满二叉树为何 有 2h -1 个节点

# 2、调长定义
定义:节点的左右子树都是堆但自己不是堆

# 3、构造堆
- 构造堆:
从最后一个有孩子的父亲开始
#! /usr/bin/env python
# -*- coding: utf-8 -*-
def sift(data, low, high):
''' 构造堆 堆定义:堆中某节点的值总是不大于或不小于父节点的值
:param data: 传入的待排序的列表
:param low: 需要进行排序的那个小堆的根对应的号
:param high: 需要进行排序那个小堆最大的那个号
:return:
'''
root = low # root最开始创建堆时是最后一个有孩子的父亲对应根的号
child = 2 * root + 1 # child子堆左孩子对应的号
tmp = data[root] # tmp是子堆中原本根的值(拿出最高领导)
while child <= high: # 只要没到子堆的最后(每次向下找一层) #孩子在堆里
if child + 1 <= high and data[child] < data[child + 1]: # 如果有右孩纸,且比左孩子大
child += 1
if tmp < data[child]: # 如果孩子还比子堆原有根的值tmp大,就将孩子放到子堆的根
data[root] = data[child] # 孩子成为子堆的根
root = child # 孩子成为新父亲(向下再找一层)
child = 2 * root + 1 # 新孩子 (此时如果child<=high证明还有孩,继续找)
else:
break # 如果能干就跳出循环就会流出一个空位
data[root] = tmp # 最高领导放到父亲位置
def heap_sort(data):
'''调整堆'''
n = len(data)
# n//2-1 就是最后一个有孩子的父亲那个子堆根的位置
for i in range(n // 2 - 1, -1, -1): #开始位置,结束位置, 步长 这个for循环构建堆
# for循环输出的是: (n // 2 - 1 ) ~ 0 之间的数
sift(data, i , n-1) # i是子堆的根,n-1是堆中最后一个元素
data = [20,50,20,60,70,10,80,30,40]
heap_sort(data)
print(data) # [80, 70, 20, 60, 50, 10, 20, 30, 40]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
- 构造堆原理
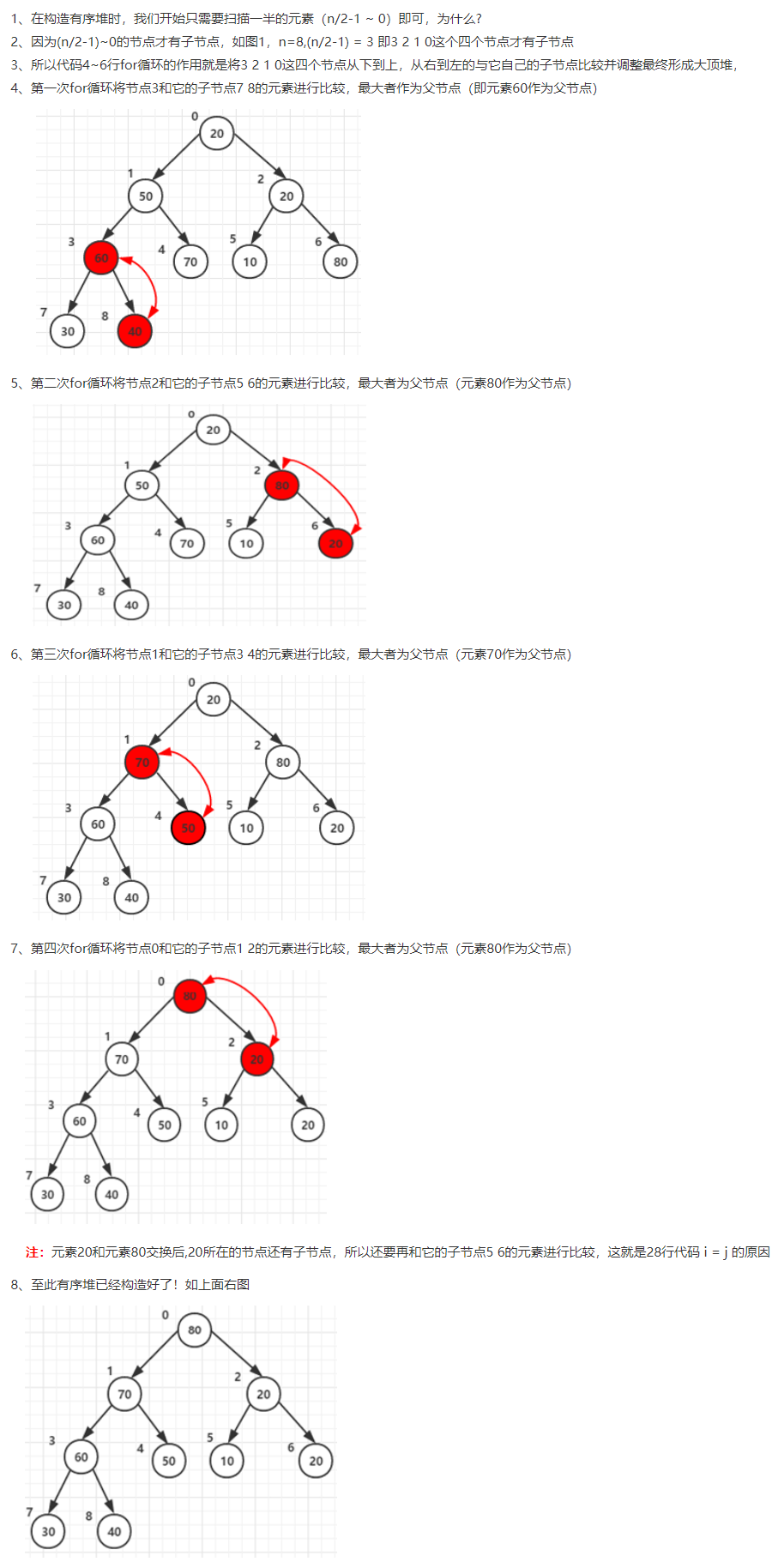
# 4、调整堆
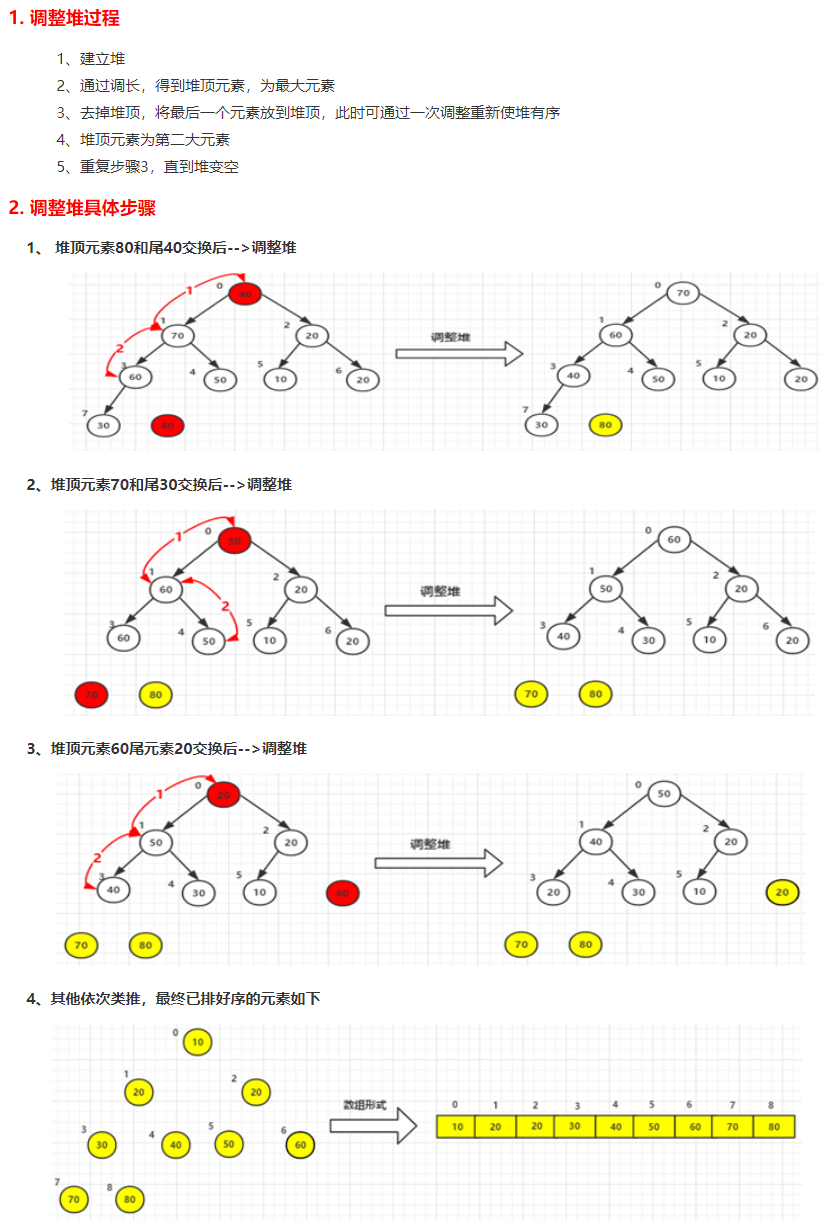
# 5、堆排序代码
# !/usr/bin/env python
# -*- coding:utf-8 -*-
import random
def sift(data, low, high):
''' 构造堆 堆定义:堆中某节点的值总是不大于或不小于父节点的值
:param data: 传入的待排序的列表
:param low: 需要进行排序的那个小堆的根对应的号
:param high: 需要进行排序那个小堆最大的那个号
:return:
'''
root = low # root最开始创建堆时是最后一个有孩子的父亲对应根的号
child = 2 * root + 1 # child子堆左孩子对应的号
tmp = data[root] # tmp是子堆中原本根的值(拿出最高领导)
while child <= high: # 只要没到子堆的最后(每次向下找一层) #孩子在堆里
if child + 1 <= high and data[child] < data[child + 1]: # 如果有右孩纸,且比左孩子大
child += 1
if tmp < data[child]: # 如果孩子还比子堆原有根的值tmp大,就将孩子放到子堆的根
data[root] = data[child] # 孩子成为子堆的根
root = child # 孩子成为新父亲(向下再找一层)
child = 2 * root + 1 # 新孩子 (此时如果child<=high证明还有孩,继续找)
else:
break # 如果能干就跳出循环就会流出一个空位
data[root] = tmp # 最高领导放到父亲位置
def heap_sort(data):
'''调整堆'''
n = len(data)
''' n//2-1 就是最后一个有孩子的父亲那个子堆根的位置 '''
for i in range(n // 2 - 1, -1, -1): # 开始位置,结束位置, 步长 这个for循环构建堆
# for循环输出的是: (n // 2 - 1 ) ~ 0 之间的数
sift(data, i, n - 1) # i是子堆的根,n-1是堆中最后一个元素
# 堆建好了,后下面就是挨个出数
for i in range(n - 1, -1, -1): # i指向堆的最后 这个for循环出数然后,调长调整堆
# for循环输出的是 : n-1 ~ 0之间所有的数,n-1就是这个堆最后那个数的位置
data[0], data[i] = data[i], data[0] # 将堆的第一个和最后一个值调换位置(将最大数放到最后)
sift(data, 0, i - 1) # 将出数后的部分重新构建堆(调长)
data = list(range(100))
random.shuffle(data) # 将有序列表打乱
heap_sort(data)
print(data)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 6、建堆复杂度
过程时间:O(n) 公式推倒
参考博客:https://www.cnblogs.com/GHzz/p/9635161.html
说明:建堆时间复杂度指初始化堆需要调整父节点和子节点顺序次数
''' 假设高度为:k '''
#### 1、推倒第i层的总时间:s = 2^( i - 1 ) * ( k - i )
# 说明:如果在最差的条件下,就是比较次数后还要交换;因为这个是常数,所以提出来后可以忽略;
'''
1. 2^( i - 1):表示该层上有多少个元素
2. ( k - i):表示子树上要下调比较的次数:第一层节点需要调整(h-1)次,最下层非叶子节点需要调整1次。
3. 推倒
倒数第1层下调次数:s = 2^( i - 1 ) * 0
倒数第2层下调次数:s = 2^( i - 1 ) * 1
倒数第3层下调次数:s = 2^( i - 1 ) * 2
倒数第i层下调次数:s = 2^( i - 1 ) * ( k - i )
'''
#### 2、一次新建堆总时间:S = n - longn -1 # 根据1中公式带人推倒
# S = 2^(k-2) * 1 + 2^(k-3)*2.....+2*(k-2)+2^(0)*(k-1) ===> 因为叶子层不用交换,所以i从 k-1 开始到 1;
'''
S = 2^(k-2) * 1 + 2^(k-3)*2.....+2*(k-2)+2^(0)*(k-1) # 等式左右乘上2,然后和原来的等式相减,就变成了:
S = 2^(k - 1) + 2^(k - 2) + 2^(k - 3) ..... + 2 - (k-1)
S = 2^k -k -1 # 又因为k为完全二叉树的深度,所以
(2^(k-1)) <= n < (2^k - 1 ) # 两边同时对2取对数,简单可得
k = logn # 实际计算得到应该是 log(n+1) < k <= logn
综上所述得到:S = n - longn -1,所以时间复杂度为:O(n)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 04.归并排序
# 1、归并原理图
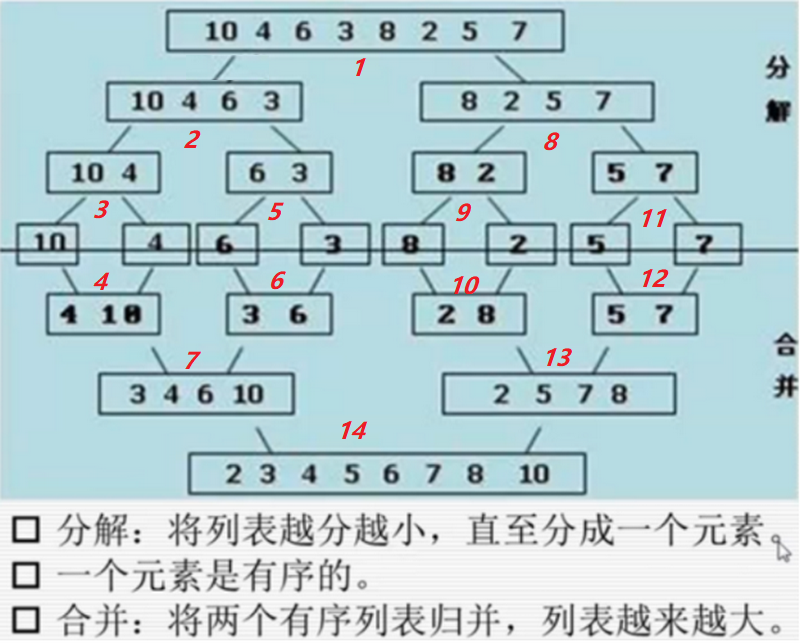
# 2、归并排序
def mergesort(arr):
# 如果数组长度小于2,直接返回数组
if len(arr) < 2:
return arr
# 计算中间位置,将数组分为左右两部分
mid = len(arr) // 2
left_half = mergesort(arr[:mid])
right_half = mergesort(arr[mid:])
# 合并排序后的左右两部分
return merge(left_half, right_half)
def merge(left, right):
result = []
i = j = 0
# 合并两个有序数组
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
# 添加剩余的左半部分元素
result.extend(left[i:])
# 添加剩余的右半部分元素
result.extend(right[j:])
return result
# 示例使用
arr = [10, 4, 6, 3, 8, 2, 5, 7]
sorted_arr = mergesort(arr)
print(sorted_arr) # 输出: [2, 3, 4, 5, 6, 7, 8, 10]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 3、合并步骤解析
- i指针指向头部,j指针指向mid+1中间位置
- tmp存放 i和j指针比较的有序值
- 下图为最后一次比较,让其有序的步骤
def merge(li,low,mid,high):
'''
:param li: 列表
:param low: 第一个元素
:param mid: 列表中间
:param high: 最后一个元素
:return:
'''
i = low # i从列表第一个元素开始
j = mid + 1 # j从中间值加一开始
tmp = []
# 使用i,j 两个指针,分别从列表开头和中间位置比较,谁小就把谁放进去
while i<= mid and j <=high:
if li[i] < li[j]:
tmp.append(li[i])
i += 1
else:
tmp.append(li[j])
j+=1
# 如果左序列还有数据,把左序列剩下的数据添加到后面
while i <= mid:
tmp.append(li[i])
i += 1
# 如果右序列还有数据,把右序列剩下的数据添加到后面
while j<= high:
tmp.append(li[j])
j = j + 1
# 替换原始列表中从 low到high之间的数据为当前已经有序的tmp数组
li[low:high+1] = tmp
li = [3,4,6,10, 2,5,7,8]
# merge(li,low,mid,high)
merge(li, 0, 3, 7)
print(li) # [2, 3, 4, 5, 6, 7, 8, 10]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 10.二分查找
# 1、python
class Solution:
def search(self, nums, target):
low = 0
high = len(nums) - 1
while low <= high:
mid = (low + high) // 2
if nums[mid] == target:
return mid
elif nums[mid] < target:
low = mid + 1
else:
high = mid - 1
return -1
print( Solution().search([-1,0,3,5,9,12], 9) ) # 返回结果是: 4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 2、golang
package main
import "fmt"
func bin_search(arr []int, finddata int) int {
low := 0
high := len(arr) - 1
for low <= high {
mid := (low + high) / 2
if arr[mid] > finddata {
high = mid - 1
} else if arr[mid] < finddata {
low = mid + 1
} else {
return mid
}
}
return -1
}
func main() {
arr := []int{1,3,4,5,6,7,8,9}
id := bin_search(arr, 4)
if id != -1 {
fmt.Println(id, arr[id]) // 2 4
} else {
fmt.Println("没有找到数据")
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 99.时间复杂度
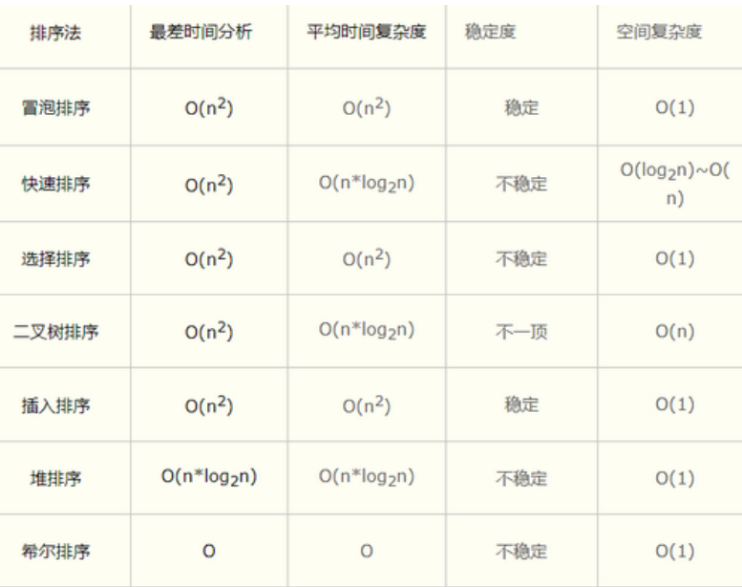
# 1、各种算法比较
- 2层for循环都是 O(n²)
- log(n):每次循环减半(二分查找)
- 快排:nlog(n)
# 2、算法不稳定定义
**定义:**在排序之前,有两个数相等,但是在排序结束之后,它们两个有可能改变顺序.
**说明:**在一个待排序队列中,A和B相等,且A排在B的前面,而排序之后,A排在了B的后面.这个时候,我们说这种算法是不稳定的.
# 3、不稳定的几种算法
1)快排为什么不稳定
- 3 2 2 4 经过第一次快排后结果:2 2 3 4 (第3号位置的2第一次排序后跑到第1号位置了)
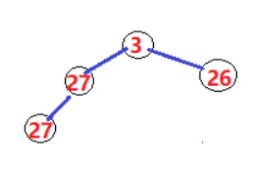
2)堆排序为什么不稳定
- 如果堆顶3先输出,则,第三层的27(最后一个27)跑到堆顶,然后堆稳定,继续输出堆顶,是刚才那个27
- 这样说明后面的27先于第二个位置的27输出,不稳定
- 3)选择排序为什么不稳定
- 5 8 5 2 9 第一次假定1号位置的5最小,但是实际最小的是4号位置的2
- 第一次排序后为:2 8 5 5 9 以前1号位置的5跑到3号位置5的后面了
上次更新: 2025/4/29 17:38:19