 04.Hystrix熔断
04.Hystrix熔断
# 01.背景介绍
# 1.1 服务雪崩
- 分布式系统环境下,服务间类似依赖非常常见,一个业务调用通常依赖多个基础服务

- 但是如果其中一个服务崩坏掉会出现什么样的情况呢?如下图
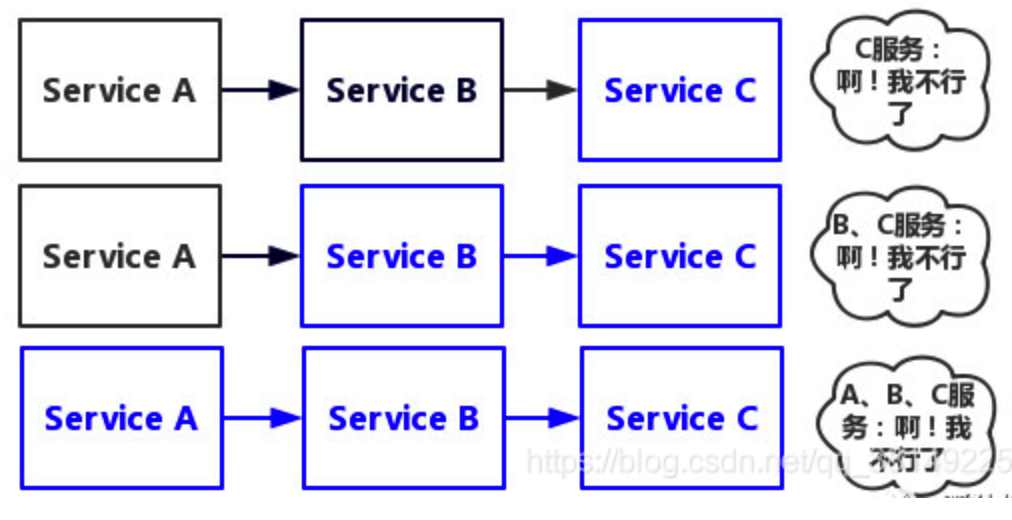
So,简单地讲,一个服务失败,导致整条链路的服务都失败的情形,我们称之为服务雪崩。
- 当Service A的流量波动很大,流量经常会突然性增加!那么在这种情况下,就算Service A能扛得住请求,Service B和Service C未必能扛得住这突发的请求。
- 此时,如果Service C因为抗不住请求,变得不可用。
- 那么Service B的请求也会阻塞,慢慢耗尽Service B的线程资源,Service B就会变得不可用。
- 紧接着,Service A也会不可用。
# 1.2 引起雪崩的原因
原因大致有四
- 1、硬件故障;
- 2、程序Bug;
- 3、缓存击穿(用户大量访问缓存中没有的键值,导致大量请求查询数据库,使数据库压力过大);
- 4、用户大量请求;
服务雪崩的三个阶段
- 第一阶段: 服务不可用;
- 第二阶段:调用端重试加大流量(用户重试/代码逻辑重试);
- 第三阶段:服务调用者不可用(同步等待造成的资源耗尽);
# 1.3 解决雪崩的方案
1) 应用扩容(扩大服务器承受力)- 加机器
- 升级硬件
2)流量控制(超出限定流量,返回类似重试页面让用户稍后再试)- 限流
- 关闭重试
3) 缓存- 将用户可能访问的数据大量的放入缓存中,减少访问数据库的请求。
4)服务降级- 服务接口拒绝服务
- 页面拒绝服务
- 延迟持久化
- 随机拒绝服务
5) 服务熔断- 如果对服务降级和服务熔断的概念模糊点此了解 关于服务熔断和服务降级的详解
# 02.服务熔断与服务降级
# 2.1 什么是服务熔断
- 当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性
- 不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用
# 2.2 服务熔断的原理
当远程服务被调用时,断路器将监视这个调用,如调用时间太长,断路器将会介入并中断调用。
此外,断路器将监视所有对远程资源的调用,如对某一个远程资源的调用失败次数足够多
那么断路器会出现并采取快速失败,阻止将来调用此远程资源的请求.
断路器模式的状态图
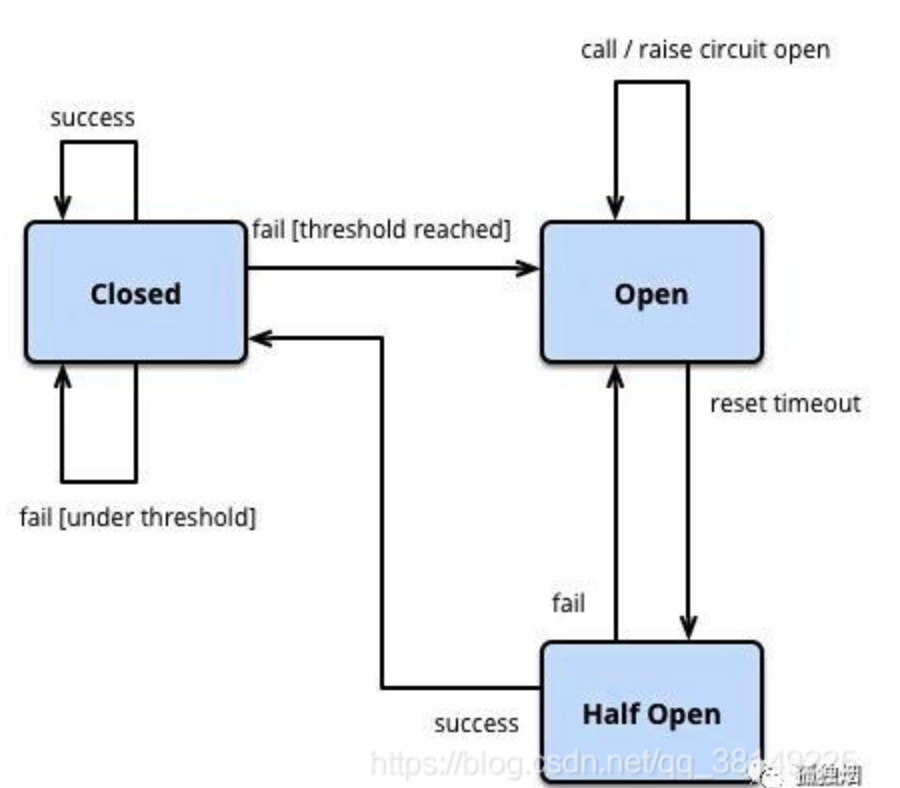
- 最开始处于closed状态,一旦检测到错误到达一定阈值,便转为open状态;
- 这时候会有个 reset timeout,到了这个时间了,会转移到half open状态,尝试放行一部分请求到后端
- 一旦检测成功便回归到closed状态,即恢复服务
# 2.3 服务降级
服务熔断可视为降级方式的一种!
一、当下游的服务因为某种原因响应过慢,下游服务主动停掉一些不太重要的业务,释放出服务器资源,增加响应速度!
二、当下游的服务因为某种原因不可用,上游主动调用本地的一些降级逻辑,避免卡顿,迅速返回给用户!
在实际的项目中,采用以下的方式来完成降级工作
- 梳理出核心业务流程和非核心业务流程。
- 然后在非核心业务流程上加上开关,一旦发现系统扛不住,关掉开关,结束这些次要流程。
- 一个微服务下肯定有很多功能,那自己区分出主要功能和次要功能。
- 然后次要功能加上开关,需要降级的时候,把次要功能关了吧!
- 降低一致性了,即将核心业务流程的同步改异步,将强一致性改最终一致性。
# 03.Hystrix
# 3.1 Hystrix简介
Hystrix是由Netflix创建一个类库。
在微服务的分布式环境中,系统存在许多服务依赖。在高并发访问下,这些依赖的稳定性与否对系统的影响非常大,
但是依赖有很多不可控问题:如网络连接缓慢,资源繁忙,暂时不可用,服务脱机等。
Hystrix可以通过添加延迟容错和容错逻辑来帮助我们控制这些分布式服务之间的交互。
Hystrix通过隔离服务之间的接入点,
阻止它们之间的级联故障,并提供备用选项,从而提高系统的整体弹性。断路器就是能够在发生问题的时候将请求断开,类似于保险丝,当电压过高的时候自动熔断。这也就是断路器的熔断机制。
设计目标
1. 对来自依赖的延迟和故障进行防护和控制——这些依赖通常都是通过网络访问的
2. 阻止故障的连锁反应
3. 快速失败并迅速恢复
4. 回退并优雅降级
5. 提供近实时的监控与告警
1
2
3
4
5
2
3
4
5
设计原则
1. 防止任何单独的依赖耗尽资源(线程)
2. 过载立即切断并快速失败,防止排队
3. 尽可能提供回退以保护用户免受故障
4. 使用隔离技术(例如隔板,泳道和断路器模式)来限制任何一个依赖的影响
5. 通过近实时的指标,监控和告警,确保故障被及时发现
6. 通过动态修改配置属性,确保故障及时恢复
7. 防止整个依赖客户端执行失败,而不仅仅是网络通信
1
2
3
4
5
6
7
2
3
4
5
6
7
# 3.2 服务提供方降级
场景假设1( 服务提供方报错) :
- 在服务提供端中因为访问不到数据库中的数据(比如数据不存在,或是数据库压力过大,查询请求队列中)
- 在这种情况下,服务提供方这边如何实现服务降级,以防止服务雪崩.
在 ProductController中加入断路逻辑
@RequestMapping("/get/{id}")
@HystrixCommand(fallbackMethod="errorCallBack") //模仿没有这个数据时,服务降级
public Object get(@PathVariable("id") long id){
Product p=this.productService.findById(id);
if( p==null){
throw new RuntimeException("查无此产品");
}
return p;
}
//指定一个降级的方法
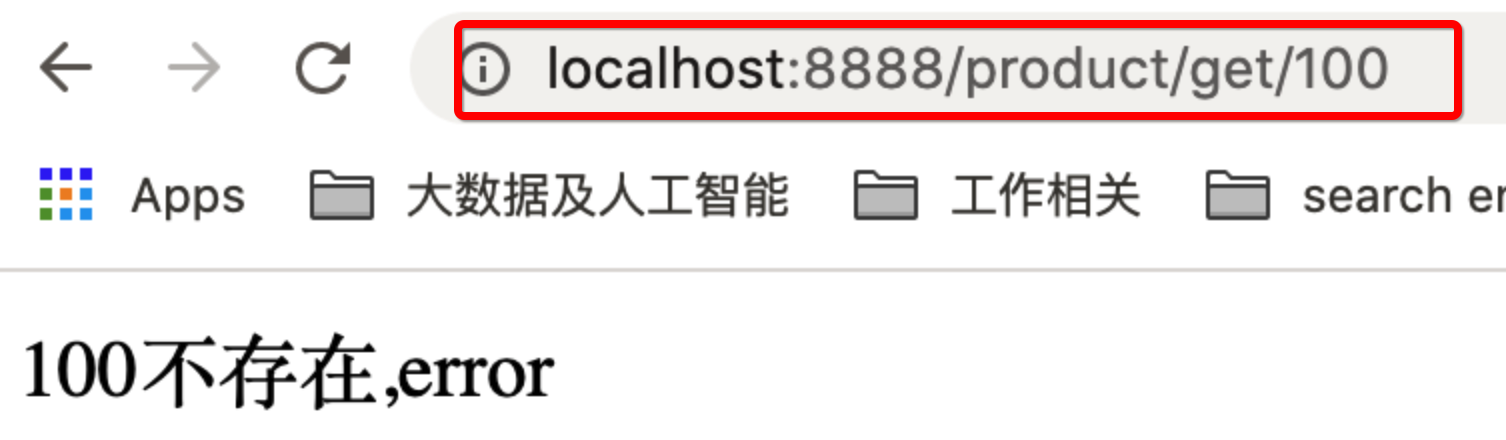
public Object errorCallBack( @PathVariable("id") long id ){
return id+"不存在,error";
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
- 启动服务后测试
# 3.3 服务消费方降级
场景假设2:
- 因为网络抖动,或服务端维护导致的服务暂时不可用,此时是客户端联接不到服务器
- 因为feign有重试机制,这样会导致系统长时间不响应,那么在这种情况上如何通过 feign+hystrix 在服务的消费方实现服务熔断(回退机制)呢?
1)建立一个包 fallback- 用于存回退处理类 IProductClientServiceFallbackFactory,这个类有出现请求异常时的处理
package com.yc.springcloud2.fallback;
import com.yc.springcloud2.bean.Product;
import com.yc.springcloud2.service.IProductClientService;
import feign.hystrix.FallbackFactory;
import java.util.List;
@Component //必须被spring 托管
public class IProductClientServiceFallbackFactory implements FallbackFactory<IProductClientService> {
@Override
public IProductClientService create(Throwable throwable) {
//这里提供请求方法出问题时回退处理机制
return new IProductClientService(){
@Override
public Product getProduct(long id) {
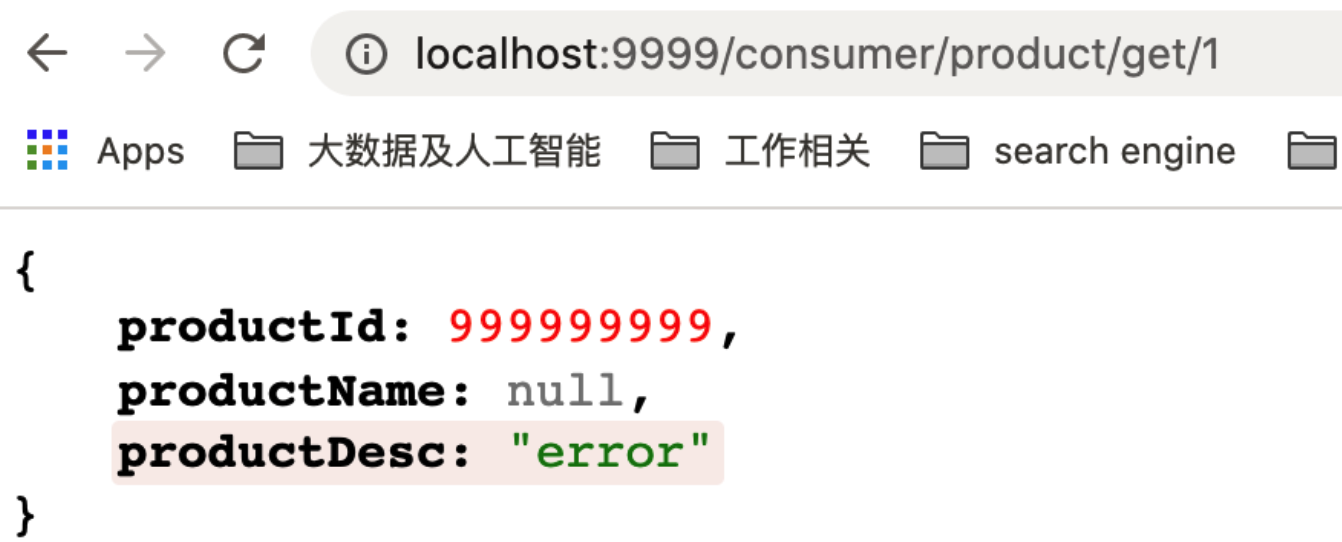
Product p=new Product();
p.setProductId(999999999L);
p.setProductDesc("error");
return p;
}
@Override
public List<Product> listProduct() {
return null;
}
@Override
public boolean addPorduct(Product product) {
return false;
}
};
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2)在业务接口上加入 fallbackFactory属性指定异常处理类
@FeignClient(name="MICROSERVICE-PROVIDER-PRODUCT",
configuration = FeignClientConfig.class,
fallbackFactory = IProductClientServiceFallbackFactory.class) // 配置要按自定义的类FeignClientConfig
public interface IProductClientService {
1
2
3
4
2
3
4
3)启动 microservice-consumer-feign客户端进行测试, 在测试时,尝试关闭生产端,看它是否回退
上次更新: 2024/3/13 15:35:10