 09.RabbitMQ集群
09.RabbitMQ集群
# 01.RabbitMQ各种模式说明
# 1、普通集群模式
队列元数据在所有节点间同步,但消息数据存储在主节点
消费者从非主节点消费时,会通过内部通信从主节点转发消息,增加了延迟
容错能力较弱,队列主节点宕机时消息可能丢失
# 2、镜像队列集群模式
# 1)镜像队列 特点
队列的
元数据和消息数据在多个节点间完全同步如果
主节点宕机,从节点会自动提升为主节点,提供高可用性镜像队列的局限性- 在网络正常的情况下,主节点会立即确认写入,而
不等到所有从节点都完成同步 - 这可能会导致 数据丢失,特别是在网络故障发生时,未同步的从节点无法及时接收到消息
- 在网络正常的情况下,主节点会立即确认写入,而
选举机制如果主节点宕机,剩余的镜像副本会选举一个新的主节点
选举过程基于 RabbitMQ 内部的队列元数据(metadata)机制
谁拥有最新的同步数据,谁会被选为新的主节点
# 2)脑裂导致服务不可用
分区策略配置ignore(默认): 不解决脑裂问题,允许分区继续独立运行,但可能导致服务不可用pause_minority(推荐):暂停少数派分区的服务,只有多数派继续工作autoheal:自动在分区恢复后进行合并,但可能丢失少数派的数据。
为什么镜像队列脑裂后可能无法选举新主节点?- 镜像队列的多数派形成与仲裁队列的行为不同, 不会主动判断哪个分区是“多数派”
- 如果脑裂导致
原主节点失联,集群元数据无法更新(原因镜像队列不等待同步) 剩余节点因缺少最新的元数据无法继续服务
# 3、仲裁队列集群模式
# 1)仲裁队列 特点
Raft 协议确保所有的写操作必须在多数节点确认之后才会提交,从而保证数据一致性写入性能较低,因为每次写入需要多数节点确认
# 2)脑裂选举机制
在发生脑裂时,只有
多数节点可以继续工作并维持队列的正常操作少数节点会停止接受写操作,直到与多数派同步数据极端情况下,仲裁队列也可能不可用
- 如果少数节点上有一些未同步的数据,剔除它们意味着这些未同步的数据就会丢失
- 因为这份数据可能在多数节点形成的新集群中不满足半数以上的同步
# 02.镜像集群原理
# 1、镜像队列服务提供方式
镜像模式会主动将各node内的数据同步到其他节点
保证集群内各主机数据一致性,集群之间会自动同步数据
对节点数量没有要求,两个或者三个都可以
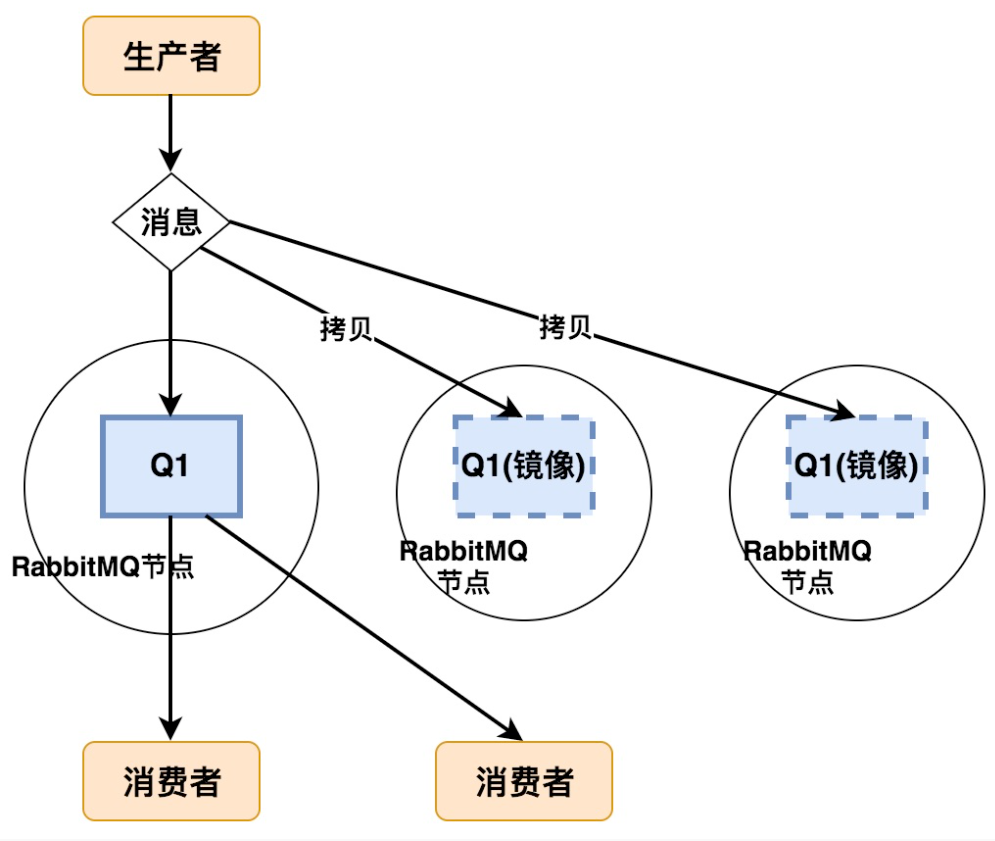
# 2、关于node节点
- queue有master节点和slave节点
- 要强调的是,
在RabbitMQ中master和slave是针对一个queue而言的 - 而不是一个node作为所有queue的master,其它node作为slave
一个queue第一次创建的node为它的master节点,其它node为slave节点
# 3、获取数据方法
- 镜像队列中,只有
master对外提供服务,slave节点仅作为备份 - 当
master不可用时,选出一个slave成为新的master - 客户端请求打到
master:直接返回消息,并通过GM协议同步队列状态到所有slave - 客户端请求打到
slave:请求会被重定向到master,master返回消息并同步队列状态到slave - GM协议保证状态同步的原子性,避免同一消息被多个客户端重复消费
# 4、RabbitMQ集群处理新增节点
- 新节点加入后
不会同步历史数据,仅复制其加入后新增的消息 - 当
master退出集群,RabbitMQ从最早已同步的slave节点中选举新master
# 5、镜像队列注意点
镜像队列不能作为负载均衡使用,因为每个声明和消息操作都要在所有节点复制一遍- ha-mode参数和durable declare对exclusive队列都不生效,因为exclusive队列是连接独占的,当连接断开,队列自动删除
- 所以实际上这两个参数对exclusive队列没有意义
每当一个节点加入或者重新加入(例如从网络分区中恢复回来)镜像队列,之前保存的队列内容会被清空- 对于镜像队列,客户端basic.publish操作会同步到所有节点;
- 而其他操作则是通过master中转,再由master将操作作用于salve
- 比如一个basic.get操作,假如客户端与slave建立了TCP连接,首先是slave将basic.get请求发送至master
- 由master备好数据,返回至slave,投递给消费者
# 03.镜像集群搭建
# 1、软件介质
| 软件 | 版本 | 备注 |
|---|---|---|
| rabbitmq | 3.8.8 | 需要安装对应的erlang版本 |
| erlang | 23.x | rabbitmq对应erlang版本 (opens new window) |
# 2、主机资源
| 主机名 | 操作系统 | IP | 备注 |
|---|---|---|---|
| rabbitmq1 | centos7.4 | 192.168.1.1 | 磁盘节点,管理节点 |
| rabbitmq2 | centos7.4 | 192.168.1.2 | 内存节点 |
| rabbitmq3 | centos7.4 | 192.168.1.3 | 内存节点 |
# 3、hosts设置
[root@k8s-node2 aaa]# vim /etc/hosts
192.168.1.1 rabbitmq1
192.168.1.2 rabbitmq2
192.168.1.3 rabbitmq3
1
2
3
4
2
3
4
# 4、分别在以上三台主机上执行
# 1)erlang安装
# 下载erlang软件包源
wget https://packages.erlang-solutions.com/erlang-solutions-1.0-1.noarch.rpm
sudo yum install epel-release -y
# 安装erlang软件包源
sudo rpm -Uvh erlang-solutions-1.0-1.noarch.rpm
# 安装erlang环境
sudo yum install erlang -y
1
2
3
4
5
6
7
2
3
4
5
6
7
- 验证
[root@rabbitmq1 ~]# erl
Erlang/OTP 23 [erts-11.1] [source] [64-bit] [smp:8:8] [ds:8:8:10] [async-threads:1] [hipe]
Eshell V11.1 (abort with ^G)
1
2
3
2
3
# 2)rabbitmq安装
# 下载介质源
wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.8.8/rabbitmq-server-3.8.8-1.el7.noarch.rpm
# 安装介质源
yum install -y rabbitmq-server-3.8.8-1.el7.noarch.rpm
# 打开开启动
systemctl enable rabbitmq-server
# 启动服务
systemctl start rabbitmq-server
# 查看服务状态
systemctl status rabbitmq-server
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
- 验证
[root@rabbitmq1 ~]$ systemctl status rabbitmq-server.service
● rabbitmq-server.service - RabbitMQ broker
Loaded: loaded (/usr/lib/systemd/system/rabbitmq-server.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2020-12-05 15:34:50 UTC; 13h ago
Main PID: 11663 (beam.smp)
Status: "Initialized"
CGroup: /system.slice/rabbitmq-server.service
├─11663 /usr/lib64/erlang/erts-11.1/bin/beam.smp -W w -K true -A 128 -MBas ageffcbf -MHas ageffcbf -MBlmbcs 512 -MHlmbcs 512 -MMmcs 30 -P 1048576 -t 5000000 -stbt db -zdbbl 128000 -- -root ...
├─11844 erl_child_setup 32768
├─11918 inet_gethost 4
└─11919 inet_gethost 4
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 5、创建集群
- 将rabbitmq1作为群集的管理节点
# 1)配置集群基础环境
- copy erlang集群文件到rabbitmq2、rabbitmq3的
/var/lib/rabbitmq/目录中 - 将重启
systemctl restart rabbitmq-serverrabbitmq2、rabbitmq3的服务
# 查看erlang分布式集群文件
[root@rabbitmq1 ~]# ls -al /var/lib/rabbitmq
total 8
drwxr-xr-x 3 rabbitmq rabbitmq 42 Oct 30 21:47 .
drwxr-xr-x. 27 root root 4096 Oct 30 21:20 ..
-r-------- 1 rabbitmq rabbitmq 20 Oct 30 00:00 .erlang.cookie
drwxr-x--- 4 rabbitmq rabbitmq 135 Oct 30 21:47 mnesia
# 查看.erlang.cookie内容
[root@rabbitmq1 rabbitmq]# cat .erlang.cookie
SFWVLUCDUUVPIVRJDWTE[root@rabbitmq1 rabbitmq]#
# copy .erlang.cookie 文件到其它主机对应的目录中
[root@rabbitmq1 rabbitmq]# scp .erlang.cookie root@rabbitmq2:/var/lib/rabbitmq/
root@rabbitmq2's password:
.erlang.cookie 100% 20 27.0KB/s 00:00
[root@rabbitmq1 rabbitmq]# scp .erlang.cookie root@rabbitmq3:/var/lib/rabbitmq/
root@rabbitmq3's password:
.erlang.cookie 100% 20 36.7KB/s 00:00s
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 2)将节点加入集群中
- 将rabbitmq2、rabbitmq3加入群集
# 在rabbitmq1上看群集的状态
[root@rabbitmq1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbitmq1 ...
Basics
Cluster name: rabbit@rabbitmq1
Disk Nodes
rabbit@rabbitmq1
Running Nodes
rabbit@rabbitmq1
Versions
rabbit@rabbitmq1: RabbitMQ 3.8.8 on Erlang 23.1
Maintenance status
Node: rabbit@rabbitmq1, status: not under maintenance
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@rabbitmq1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@rabbitmq1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@rabbitmq1, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Feature flags
Flag: drop_unroutable_metric, state: disabled
Flag: empty_basic_get_metric, state: disabled
Flag: implicit_default_bindings, state: enabled
Flag: maintenance_mode_status, state: enabled
Flag: quorum_queue, state: enabled
Flag: virtual_host_metadata, state: enabled
# 在rabbitmq2操作加入群集
# 1.停止rabbitmq2上的服务
[root@rabbitmq2 ~]# rabbitmqctl stop_app
Stopping rabbit application on node rabbit@rabbitmq2 ...
# 2.停止rabbitmq2上的服务
[root@rabbitmq2 ~]# rabbitmqctl reset
Resetting node rabbit@rabbitmq2 ...
# 2.将rabbitmq2加入集群,--ram是以内存方式加入
[root@rabbitmq2 ~]# rabbitmqctl join_cluster --ram rabbit@rabbitmq1
Clustering node rabbit@rabbitmq2 with rabbit@rabbitmq1
# 3.启动rabbitmq2上的服务
[root@rabbitmq2 ~]# rabbitmqctl start_app
Starting node rabbit@rabbitmq2 ...
# rabbitmq3以同样的方式加入即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
- 验证:
# 查看群集状态
[root@rabbitmq1 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbitmq1 ...
Basics
Cluster name: rabbit@rabbitmq1
Disk Nodes
rabbit@rabbitmq1
RAM Nodes
rabbit@rabbitmq2
rabbit@rabbitmq3
Running Nodes
rabbit@rabbitmq1
rabbit@rabbitmq2
rabbit@rabbitmq3
Versions
rabbit@rabbitmq1: RabbitMQ 3.8.9 on Erlang 21.3.8.18
rabbit@rabbitmq2: RabbitMQ 3.8.9 on Erlang 21.3.8.18
rabbit@rabbitmq3: RabbitMQ 3.8.9 on Erlang 21.3.8.18
Maintenance status
Node: rabbit@rabbitmq1, status: not under maintenance
Node: rabbit@rabbitmq2, status: not under maintenance
Node: rabbit@rabbitmq3, status: not under maintenance
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@rabbitmq1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@rabbitmq1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@rabbitmq1, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@rabbitmq2, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@rabbitmq2, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@rabbitmq2, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@rabbitmq3, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@rabbitmq3, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@rabbitmq3, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 3)将集群设为镜像模式
在我们使用 rabbitmq 作为消息服务时,在服务负载不是很大的情况下
一般我们只需要一个 rabbitmq 节点便能为我们提供服务
可这难免会发生单点故障,要解决这个问题,我们便需要配置 rabbitmq 的集群和镜像
镜像模式参数
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: exchanges或queue的匹配模式(正则表达式)
Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params:ha-mode模式需要用到的参数
ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manualautomatic:新增加节点自动同步全量数据manual: 新增节点只同步新增数据,全量数据需要手工同步
Priority:可选参数,policy的优先级
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
- 设置示例
# 所有队列exchangess 或者 queue都为镜像模式
[root@rabbitmq1 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
Setting policy "ha-all" for pattern "^" to "{"ha-mode":"all"}" with priority "0" for vhost "/" ...
# 对队列名称以“queue_”开头的所有队列进行镜像,并在集群的两个节点上完成进行,policy的设置命令为:
[root@rabbitmq1 ~]# rabbitmqctl set_policy --priority 0 --apply-to queues mirror_queue "^queue_" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
1
2
3
4
5
6
2
3
4
5
6
上次更新: 2024/12/19 17:28:11