 02.Map原理 ✅重要原理
02.Map原理 ✅重要原理
Go语言的map底层是哈希表,通过哈希函数将键映射到对应的bucket中。
map的扩容通常在两个场景下触发:装载因子超过6.5和溢出bucket数量过多。
扩容时,bucket数量翻倍,旧数据逐步迁移到新bucket。
哈希表使用链表法解决哈希冲突,通过key的哈希值低位确定所属bucket,哈希值高位用于桶内定位key。
扩容过程中,新bucket的元素被重新分配,查找操作时优先查询新bucket,并逐步迁移旧数据。
# 01.map简介
# 1、map底层浅析
- 笼统的来说,
go的map底层是一个hash表,通过键值对进行映射 - 哈希查找表一般会存在“碰撞”的问题,就是说不同的 key 被哈希到了同一个 bucket
- 一般有两种应对方法:
链表法和开放地址法链表法将一个 bucket 实现成一个链表,落在同一个 bucket 中的 key 都会插入这个链表开放地址法则是碰撞发生后,通过一定的规律,在数组的后面挑选“空位”,用来放置新的 key
# 2、Hash函数
- 哈希函数会
将传入的key值进行哈希运算,得到一个唯一的值 - go语言把生成的哈希值一分为二,比如一个key经过哈希函数,生成的哈希值为:
8423452987653321,go语言会这它拆分为84234529,和87653321 - 那么,前半部分就叫做高位哈希值,后半部分就叫做低位哈希值
- 低位哈希值:
确定数据存在哪个bucket(桶)- 将
哈希值的低8位与桶的数量取模就可以决定数据应该被分配到哪个桶
- 将
- 高位哈希值:
确定当前的bucket(桶)有没有所存储的数据的- 桶内部会根据
哈希值的高8位来进一步确定key 在桶内的具体位置 - 每个桶内部最多有 8 个位置(槽位),这些槽位是根据哈希值的高 8 位来决定的
- 查找时,首先通过比较高 8 位哈希值过滤掉大部分不相关的 key
- 如果高 8 位不同,则跳过该槽位;如果相同,继续进行完整的 key 比较
- 桶内部会根据
# 3、Map举例
在 Go 的
map实现中,哈希值是对键进行计算后得到的一个 64 位的整数假设我们有三个键(实际是64位)Key1的哈希值:00011011 10101100 11010101 ...Key2的哈希值:00011011 00101111 11110010 ...Key3的哈希值:10100111 01010101 01100010 ...
假设
map目前包含 16 个,则每个桶的位置可以通过哈希值的低 4 位来计算假设
Key1和Key2的哈希值低四位是 0101,则Key1和Key2都会存储在桶5中假设
桶 5中存储的高八位是[00011011, 00011011, ...]系统会找到与
00011011匹配的条目,然后进一步比较槽位中的完整键Key1高八位可以在不需要比较完整键的情况下,快速筛除大部分不匹配的键
# 02.map结构
# 0、map结构图
- map的内存模型中,其实总共就
三种结构,hmap,bmap,mapextra hmap表示整个map,bmap表示hmap中的一个桶,map底层其实是由很多个桶组成的mapextra表示所有的溢出桶,之所以还要重新的指向,目的是为了用于gc,避免gc时扫描整个map

# 1、hmap 哈希表
hmap是整个 map 的核心数据结构,它表示了一个完整的哈希表hmap中包含一些关键字段:buckets:指向实际存储键值对的存储桶数组(buckets array)
count:当前存储在 map 中的键值对数量
hash0:哈希种子,用于防止哈希冲突攻击
overflow:存储发生溢出时的溢出桶
extra:指向
mapextra结构,用来存放垃圾回收(GC)相关的信息
hmap中的 buckets 是指向一个包含多个桶(bucket)的数组,而这些桶负责实际存储键值对
type hmap struct {
count int // map的大小, len()取值
flags uint8 // map状态标识
B uint8 // 可以最多容纳 6.5 * 2 ^ B 个元素,6.5为装载因子即:map长度=6.5*2^B
// B可以理解为buckets已扩容的次数
noverflow uint16 // 溢出buckets的数量
hash0 uint32 // hash 种子
buckets unsafe.Pointer //指向最大2^B个Buckets数组的指针. count==0时为nil.
oldbuckets unsafe.Pointer //指向扩容之前的buckets数组,并且容量是现在一半.不增长就为nil
nevacuate uintptr //搬迁进度,小于nevacuate的已经搬迁
extra *mapextra //可选字段,额外信息
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 2、bmap 存储桶
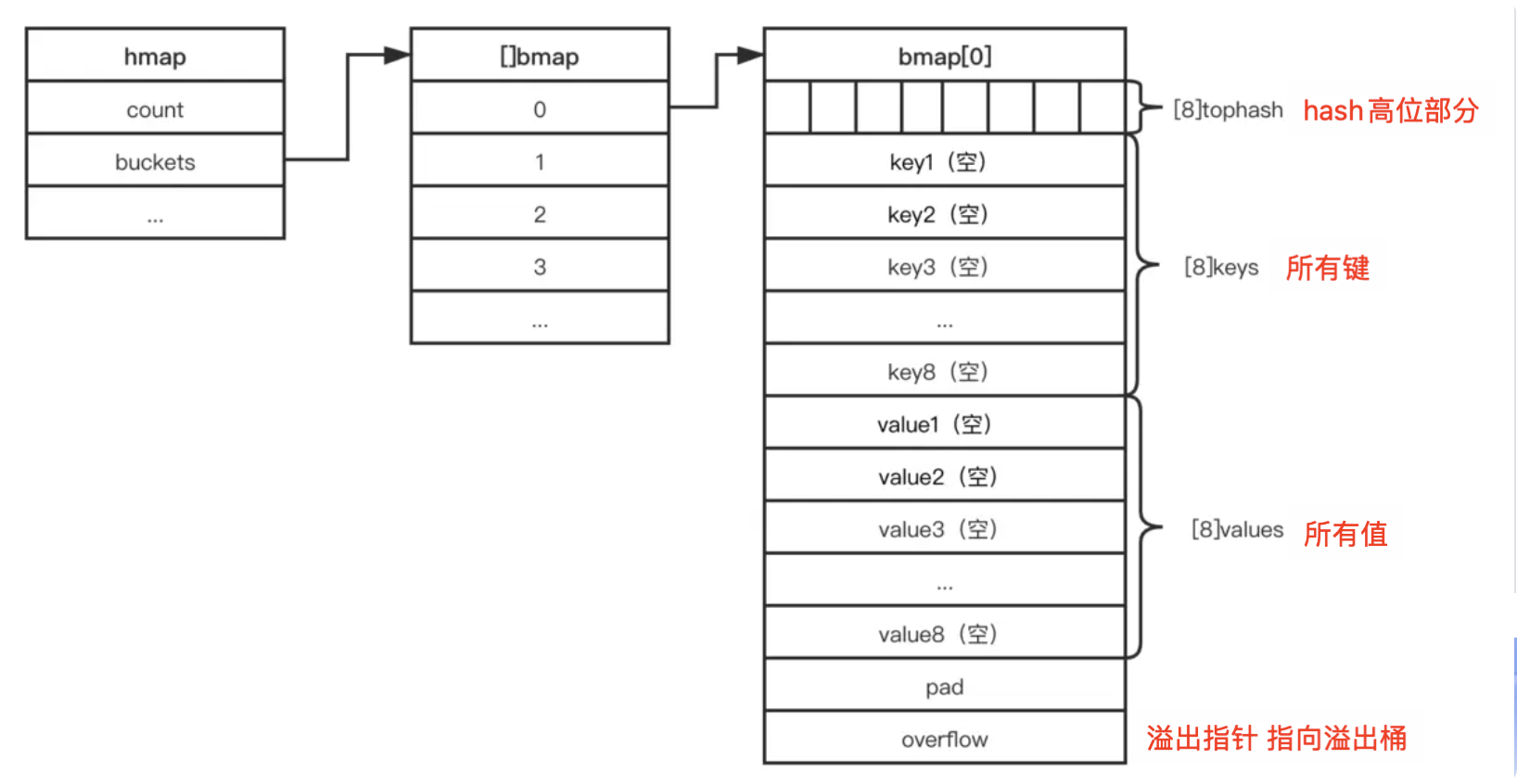
bmap表示hmap中的一个桶,每个桶里面会最多装 8 个 key每个
bmap结构包含以下几个主要部分:tophash:存储与桶内元素对应的
哈希值的高位部分,用于快速定位哈希冲突keys:存储桶中所有的键(key)
values:存储桶中所有的值(value)
在
bmap结构中,keys 和 values 是分开存储的,也就是所有键存放在一个区域,所有值存放在另一个区域
type bmap struct { //原始结构体
tophash [bucketCnt]uint8
}
type bmap struct { //编译期间会给它加料,动态地创建一个新的结构
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
2
3
4
5
6
7
8
9
10
11
如果一个桶的 8 个槽位都已满,并且还有新的 key 要插入,则需要以下几种策略
- 溢出桶(overflow bucket):
- 如果某个桶的槽位满了,哈希表会分配一个新的溢出桶,并将额外的 key-value 对存储在新的溢出桶中
- 扩容:
- 当哈希表内的 key 数量增加到一定程度时,哈希表会进行全局扩容
# 3、mapextra 结构
溢出桶(Overflow Buckets)
- 当某个桶 (
bmap) 中存储的键值对数量超过了其容量时,会产生溢出- 这时,map 会为这个桶分配一个溢出桶(overflow bucket),该溢出桶
用于继续存储多余的键值对- 溢出桶的设计可以视为 Go 语言中处理哈希冲突的一种方式——拉链法(chaining),通过将多个桶串联在一起
溢出桶不会存放在主桶数组中,而是放在mapextra结构中
mapextra结构专门用于存放所有的溢出桶,mapextra中存放了指向溢出桶的头指针,这样溢出桶可以形成一个链表因为当 GC 执行时,如果溢出桶与主桶数组放在一起,那么整个 map 都需要被扫描,这会增加 GC 的负担
但通过
mapextra单独存放溢出桶,GC 只需要扫描溢出桶的部分,这样可以提高垃圾回收的效率查找时溢出桶的遍历:
- 当查找某个 key 时,哈希表
首先在对应的主桶中查找 - 如果
主桶中的槽位中找不到对应的 key,且主桶已满(即发生溢出) - 哈希表会顺着主桶的**
溢出指针**,依次遍历所有的溢出桶 - 每个主桶的**
溢出指针**指向自己对应的溢出桶位置
- 当查找某个 key 时,哈希表
# 03.map增删改查原理
# 1、查找
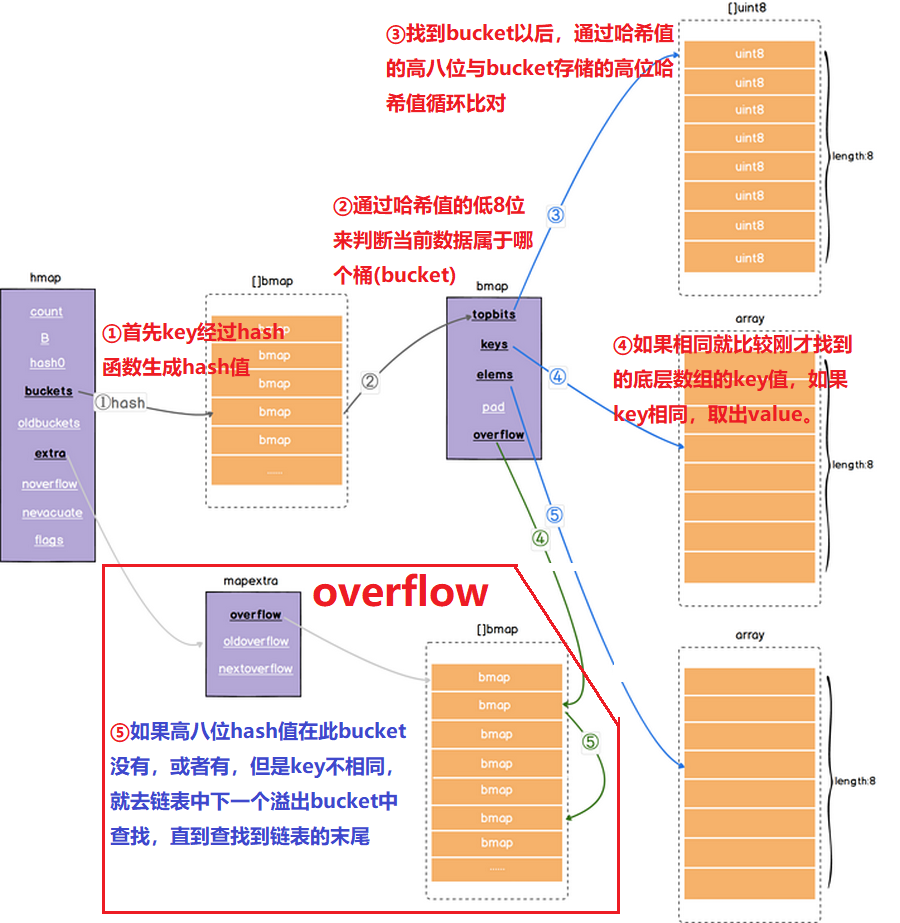
查找或者操作map时,首先key经过hash函数生成hash值,
通过哈希值的低8位来判断当前数据属于哪个桶(bucket)找到bucket以后,通过
哈希值的高八位与bucket存储的高位哈希值循环比对如果
相同就比较刚才找到的底层数组的key值,如果key相同,取出value如果高八位hash值在此bucket没有,或者有,但是key不相同,就
去链表中下一个溢出bucket中查找,直到查找到链表的末尾碰撞冲突:
- 如果不同的key定位到了统一bucket或者生成了同一hash,就产生冲突
- go是通过链表法来解决冲突的
- 比如一个高八位的hash值和已经存入的hash值相同,并且此bucket存的8个键值对已经满了,或者后面已经挂了好几个bucket了
- 那么这时候要存这个值就先比对key,key肯定不相同啊,那就从此位置一直沿着链表往后找,找到一个空位置,存入它
- 所以这种情况,两个相同的hash值高8位是存在不同bucket中的
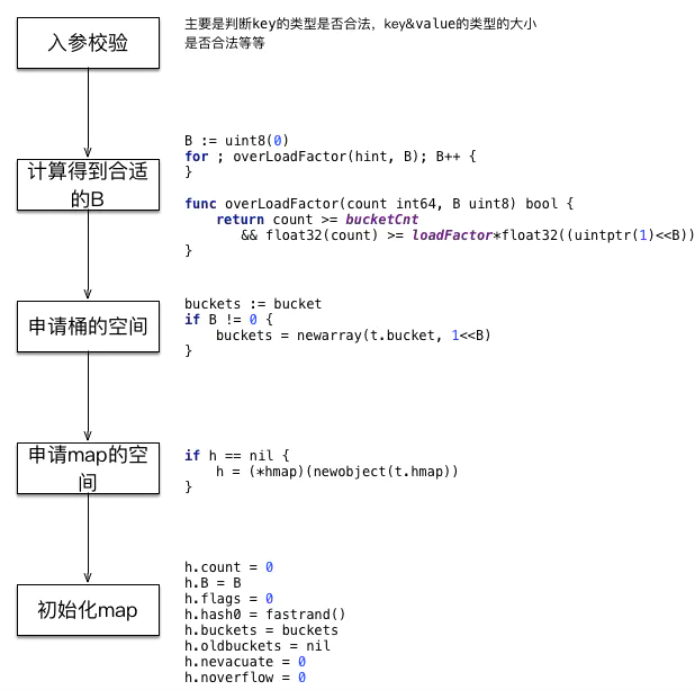
# 2、创建
- map的创建比较简单,在参数校验之后,需要
找到合适的B来申请桶的内存空间 - 接着便是
创建hmap这个结构,以及对它的初始化
# 3、删除
- 删除某个key的操作与分配类似,由于hashmap的存储结构是数组+链表
- 所以真正删除key仅仅是将对应的slot设置为empty,并没有减少内存
# 04.map扩容策略是什么
# 1、map简述
- 随着向 map 中添加的 key 越来越多,key 发生碰撞的概率也越来越大
- bucket 中的 8 个 cell 会被逐渐塞满,查找、插入、删除 key 的效率也会越来越低
- Go 语言采用一个 bucket 里装载 8 个 key,定位到某个 bucket 后,还需要再定位到具体的 key,这实际上又用了时间换空间
# 2、触发 map 扩容的时机
在向 map 插入新 key 的时候,会进行条件检测,符合下面这 2 个条件,就会触发扩容
1)
装载因子超过阈值,源码里定义的阈值是 6.5装载因子
loadFactor := count /(2^B)count 就是 map 的元素个数,2^B 表示 bucket 数量
2)overflow 的 bucket 数量过多
当 B 小于 15,如果overflow 的 bucket 数量超过 2^B;(也就是bucket 总数 2^B 小于 2^15 时)当 B >= 15,如果overflow 的 bucket 数量超过 2^15(也就是bucket 总数 2^B 大于等于 2^15)
# 1)装载因子大于6.5
我们知道,每个 bucket 有 8 个空位,在没有溢出,且所有的桶都装满了的情况下,装载因子算出来的结果是 8
因此当装载因子超过 6.5 时,表明很多 bucket 都快要装满了,查找效率和插入效率都变低了在这个时候进行扩容是有必要的
对于条件 1,扩容方案元素太多,而 bucket 数量太少,很简单:将 B 加 1,bucket 最大数量(2^B)直接变成原来 bucket 数量的 2 倍- 注意,这时候元素都在老 bucket 里,还没迁移到新的 bucket 来
- 而且,新 bucket 只是最大数量变为原来最大数量(2^B)的 2 倍(2^B * 2)
数据迁移
- 当元素写入时,哈希表使用新的桶数量来计算 key 的存放位置
- 如果该 key 应该存放在某个新 bucket 中,则直接存储在新 bucket 中
- 如果该 key 仍然属于旧 bucket,则可能还会存放在旧 bucket 中
查询操作
- 执行
查询、插入或删除操作时,哈希表会优先从新 bucket 中进行查找 - 如果数据仍在旧 bucket 中,则会查找旧 bucket 并将其迁移到新 bucket 中
- 执行
# 2)overflow数量过多
- 造成原因是,刚开始有大量数据,但是后面都删除了,导致没有触发1条件
对于条件 2,扩容方案- 其实
元素没那么多,但是 overflow bucket 数特别多,说明很多 bucket 都没装满 - 解决办法就是
开辟一个新 bucket 空间,将老 bucket 中的元素移动到新 bucket,使得同一个 bucket 中的 key 排列地更紧密
- 其实
# 05.map值无法地址取值
# 5.1 map指针取地址报错问题
- 当通过key获取到value时,这个value是不可寻址的,因为map 会进行动静扩容
- 当进行扩大后,map的value就会进行内存迁徙,其地址发生变化,所以无奈对这个value进行寻址
package main
type UserInfo struct {
UserName string `json:"user_name"`
}
func main() {
user := make(map[string]UserInfo)
user["0001"] = UserInfo{
UserName: "jack",
}
// 因为map会进行动静扩容,当进行扩大后,map的value就会进行内存迁徙,其地址发生变化
// 所以 user["0001"] 返回值不是固定的地址,所以无法获取地址
p1 := &user["0001"] // Cannot take the address of 'user["0001"]'
// 如果非要获取地址可以先赋值给一个变量
u := user["0001"]
p2 := &u
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 5.2 map使用指针value
package main
import "fmt"
type UserInfo struct {
UserName string `json:"user_name"`
}
func main() {
user := make(map[string]*UserInfo)
user["0001"] = &UserInfo{
UserName: "jack",
}
// 上面是指针 *UserInfo 才能这样操作,否则报错
user["0001"].UserName = "tom"
fmt.Println(user["0001"])
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17