 07.MLOps
07.MLOps
# 00.MLOps概述
- DevOps 的 CI/CD 只管
代码的生命周期,MLOps 的 CI/CD/CT 要同时管理代码、数据、模型的完整生命周期CI是集成代码和训练流程CD是部署模型服务CT是用新数据自动训练模型- 这三者共同支撑模型从
训练、评估、到上线,并具备持续演进能力
MLOps主要包括下面五部分
模块 工程团队职责(后端方向) 数据闭环 构建任务调度 + 存储索引 + 标注分发 + 元数据追踪系统,实现数据自动回流 模型训练 训练任务编排、GPU资源调度、训练状态监控与容错控制 模型评测 模型评估任务调度、指标系统、可视化对比平台的开发 模型部署 模型打包上线、服务封装、CI/CD 自动发布、灰度部署与监控 自动化闭环 构建自动触发策略、数据反馈识别系统,实现 CT/CD 全自动
# 0、MLOps闭环
CI:train.py → 生成 ocr_model.pt
↓
CD:app.py + ocr_model.pt → Docker 镜像 + /predict 接口
2
3
4

# 1、CI
- CI 的本质是流程验证 + 最小可行产物验证(MVP for model)

① CI 的输入(代码仓库)repo/ ├── train.py # 模型训练脚本 ├── model.py # 模型结构 ├── dataset.py # 数据加载 ├── preprocess.py # 数据预处理 ├── requirements.txt # 依赖说明 ├── tests/ # 单元测试代码 ├── sample_data/ # 小规模样本数据 └── .github/workflows/ci.yml # GitHub Actions CI 配置1
2
3
4
5
6
7
8
9
② CI 过程(典型 5 步)步骤 动作 举例 安装依赖 安装 Python 环境 pip install -r requirements.txt 代码测试 跑单元测试 pytest tests/ 构建模型 执行训练脚本 python train.py --epochs 1 --data ./sample_data 模型评估 输出评估指标 Accuracy=87.5%,Loss=0.34 存储产物 输出模型权重和日志 outputs/ocr_model.pt,logs/train.log
③ CI 最终输出类型 示例文件 说明 模型参数 ocr_model.pt训练得到的权重文件 指标日志 logs/metrics.jsonacc、loss、F1 训练日志 logs/train.log每轮训练过程 环境镜像(可选) Docker 镜像 可部署的训练环境 可视化(可选) TensorBoard 日志 用于查看 loss/acc 曲线
# 2、CD
目标:模型训练完成后,自动产出模型服务,并完成部署或注册
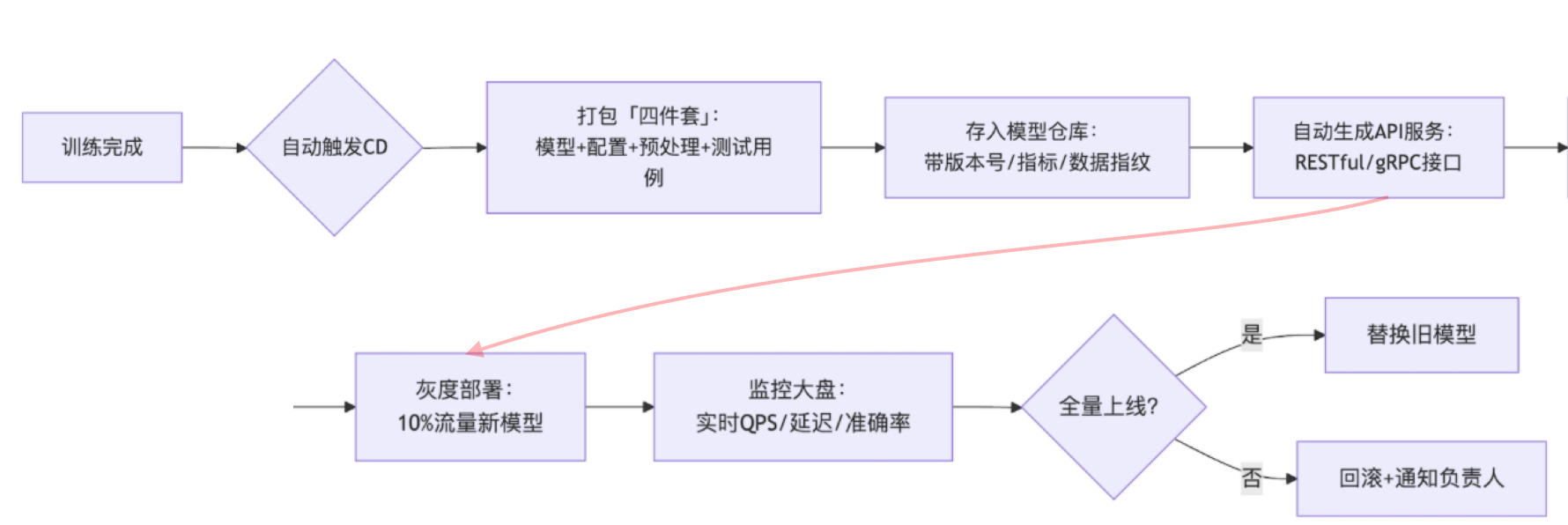
① CD 的输入 = CI 的输出模型产物(模型权重 + 环境依赖 + 指标)inputs/ ├── ocr_model.pt # 模型文件 ├── app.py # 推理服务入口(Flask/FastAPI) ├── requirements.txt # 服务依赖 ├── Dockerfile # 镜像构建配置 ├── config.yaml # 模型路径、阈值、设备等参数 └── test_request.json # 验证推理结果的样例数据1
2
3
4
5
6
7
② CD 的流程(以容器部署为例)步骤 动作 举例 构建镜像 把模型、服务代码、依赖打包 Docker build -t ocr-service:v1 . 单元测试 用样例输入测试推理接口 调用 /predict接口,验证输出正确发布服务 将容器部署到线上环境 push 到 K8s、SageMaker、阿里PAI等 配置路由 设置网关/API 接入地址 配置 Nginx 或 API 网关映射 健康检查 启动后探测服务状态 readiness/liveness probes,返回 200 OK 通知上线 发布日志、钉钉通知、版本变更说明 通知运维、业务方
③ CD 的产物类型 示例 说明 在线服务 POST /predict输入图片,返回识别结果 服务镜像 ocr-service:v1存储在镜像仓库 部署实例 pod: ocr-service-xxx运行在 K8s 或云平台 API 文档 swagger.json / Postman 给前端调用的说明文档 监控配置 Prometheus / Grafana 实时监控模型接口 QPS、延迟、错误率等
# 3、CT
- 标:发现模型性能下降或样式新增时,自动 retrain + 上线

① CT 的输入 = CD 的监控反馈 + 新数据inputs/ ├── monitoring_alerts.json # 触发条件(如准确率↓10%) ├── new_data/ # 新增/修正的数据 │ ├── low_confidence/ # 模型低置信度样本 │ └── human_corrected/ # 人工修正标签 ├── baseline_model/ # 当前线上模型(来自CD) │ ├── model.pt │ └── config.yaml └── retrain_policy.yaml # 重训练策略(增量/全量)1
2
3
4
5
6
7
8
9
② CT 的核心流程步骤 关键动作 技术实现示例 触发条件判断 检查监控指标是否满足阈值(如准确率连续3天下降) if accuracy_drop > 0.1: trigger_retrain()数据预处理 对新增数据做增强/去噪/标注校验 使用Albumentations做图像增强 增量训练 基于baseline模型微调(而非从头训练) model.load_weights(); model.fit()版本对抗测试 新旧模型在A/B测试集上对比 p=0.02 (新模型显著优于旧模型)自动审核 验证指标提升且无回归问题 通过后才允许进入CD流程
③ CT 的输出 = 下一代模型的输入outputs/ ├── retrained_model/ # 新模型候选 │ ├── model_v2.pt # 权重文件 │ └── eval_report.pdf # 对比评估结果 ├── updated_dataset/ # 版本化数据集 └── trigger_cd_flag # 自动触发CD流程的信号1
2
3
4
5
6
# 4、数据闭环
# 01.数据闭环
- 标注 → 训练 → 推理 → 评测 → 挑选错误样本 → 回流标注
- 工程团队负责构建数据闭环平台,支撑 数据回流 → 数据存储 → 清洗质检 → 标注分发 等自动化流程
# 1、数据采集
业务员通过企业内的 Web Portal 上传多张保单扫描件(.jpg / .pdf)
文件切片上传(使用 tus 或 S3 multipart),带断点续传
文件 hash(SHA256)查重(避免重复上传)
将文件保存到 MinIO,并返回 UUID 文件 ID
生成元数据(上传时间、上传人、业务类型等)存入
upload_metadata表(如 Postgres)异步推送 metadata 到 Kafka
{ "file_id": "uuid-123", "type": "image", "uploader_id": "user_001", "timestamp": "2025-06-12T14:35:22", "status": "uploaded" }1
2
3
4
5
6
7
# 2、数据流管理
数据流管理(Kafka → Redis → 标注)
Kafka 传的是“上传事件”,格式例如
这是一个通用上传事件,你不能直接让标注系统消费它
它不知道
- 要做什么类型的任务?优先级如何?
- 当前是否已被标注过?是不是要过滤掉?
{ "file_id": "uuid-123", "type": "image", "uploader_id": "user_001", "timestamp": "2025-06-12T14:35:22", "status": "uploaded" }1
2
3
4
5
6
7
Redis 中存什么数据
Kafka 消费端处理后,把真正要执行的任务「加工」后丢进 Redis,比如
Redis 列表键名:
task_queue:image_labeling每个元素是一条待标注任务,数据格式如下
- 用 Redis
List存顺序任务 - 用
SortedSet存带优先级的任务(score=priority) - 用
Hash存任务状态(task_id → 状态)
- 用 Redis
{ "task_id": "task-789", "file_id": "uuid-123", "label_type": "保单字段抽取", "priority": 3, "retry": 0, "status": "pending", "created_at": "2025-06-12T14:36:01" }1
2
3
4
5
6
7
8
9
# 3、数据存储与索引
MinIO 保存原图:
minio://raw_data/uuid-123.jpgMongoDB 记录元信息文档
{ "file_id": "uuid-123", "uploader": "user_001", "upload_time": "2025-06-12T14:35:22", "type": "image", "status": "awaiting_label", "tags": ["保单", "扫描件"] }1
2
3
4
5
6
7
8
Elasticsearch 构建索引,用于全文模糊搜索,如搜索“身份证图片”、“人寿保险保单”等
# 4、数据清洗服务
清洗脚本(Airflow任务)触发,对
uuid-123进行自动化预处理- 图片太模糊则标记为
quality_check_fail - 图片 resize → 统一为 1024x1024 → 转为 PNG
- 自动生成 待标注模版(如区域框标注所需标记字段)
- 清洗结果写入
clean_metadata表,并更新 Kafka 状态
- 图片太模糊则标记为
类别 工具 / 库 作用说明 调度执行 Airflow (opens new window) 定时清洗 DAG 任务,分发任务并管理依赖 图像处理 OpenCV,Pillow模糊检测、格式转换、裁剪、resize 对象存储访问 boto3,minio下载 MinIO / S3 文件数据 质量检测模型 skimage,scipy,opencv清晰度评估、异常图像识别 结构化模版生成 自定义规则 + layout model(如 LayoutLM) 基于图像生成字段区域预标注草图 数据库 Postgres / TiDB 存储清洗结构化结果
# 5、标注调度系统
调度服务拉 Redis 中
image_labeling任务调用标注平台 Label Studio API,分配任务
POST /api/tasks { "file_url": "https://minio.xxx/uuid-123.png", "label_type": "字段抽取", "fields": ["姓名", "身份证号", "生效时间", "保险金额"], "priority": "high", "assigned_to": "expert_group_a" }1
2
3
4
5
6
7
8调度服务职责
从 Redis 中拉取任务(Kafka → Redis 解耦后端消费)
将任务派发给标注平台(如 Label Studio)API
指定标注类型(字段抽取、分类、OCR等)
可基于优先级、业务类型分发到不同组(如
expert_group_a)
Label Studio 标注平台做了什么?
前端展示图像 + 配置的字段 schema
人工在页面上 框选文字区域,填写字段(比如:保单号、姓名)
保存任务后,通过 Webhook 回调后端接口,写入数据库(如 Postgres)
回流机制
- 标注完成后,数据进入 clean + labeled 阶段,进入训练闭环(MLOps流程)
预标注(Auto Pre-labeling)
- 在人工标注前,先通过模型自动预测字段框
- 自训练 OCR 模型(如 PP-OCRv3, LayoutLM, TrOCR)
# 6)数据追踪系统
为什么需要数据追踪?
我的某个模型出问题了,它是基于哪些标注数据训练的?
某个文件改了标注,那以前基于旧标注训练的模型怎么办?
标注员标错数据,怎么追查是谁改的、什么时候改的?
清洗策略升级了,哪些数据是旧清洗逻辑处理的?
目标 对应模块设计 实际意义 模型可追溯性 used_in_model+model_id哪些数据训练了哪个模型 数据版本管理 version字段支持标注/清洗多版本迭代 标注质量监控 label_status字段 +audit_log人工校验记录、低质量识别 审计与责任归属 audit_log表出错可查人、时间、操作内容 数据闭环追踪 全流程 log 实现数据 - 标注 - 训练全链条追踪
举个完整流程示意
文件
uuid-123上传清洗后生成
v1版本 → 写入clean_metadata人工标注完成 → 标注状态改为
verified标注完成后,进入训练数据集
模型
model_001使用了该文件 →used_in_model = true所有这些事件都写入
audit_log
- 据追踪系统包含两个核心表
一、数据版本元数据表(追踪状态 + 使用记录)
作用: 这个表能回答:“当前这份文件被标注了几次、哪一版被用来训练、训练的是哪个模型?
字段 含义 file_id原始文件唯一标识,如 uuid-123version当前数据标注版本,如 v1、v2,用于标注更新或清洗策略变化时追踪label_status当前数据是否被人工验证,如 verified、auto_labeled、pendingused_in_model当前版本是否被用于训练,如 true/falsemodel_id使用该版本训练的模型ID,可用于回溯
二、audit_log(审计日志表)—— 记录每一次操作
这个日志表能回答:“是谁、在什么时间、对哪份文件做了什么操作?
{ "actor": "labeler_02", // 谁做的 "action": "confirm_label", // 做了什么(提交、修改、删除等) "timestamp": "2025-06-12T15:23:00", "file_id": "uuid-123" // 针对哪个文件 }1
2
3
4
5
6actor action file_id extra_info clean_jobresize_imageuuid-123{ "size": "1024x1024" }labeler_02confirm_labeluuid-123{ "field": "身份证号" }trainer_01used_in_modeluuid-123{ "model_id": "model_001" }
# 7、主动学习反馈
- 让
模型自己判断哪些样本不确定或错误,然后请人来标注,从而优先学习最有价值的样本
① 一张新上传的保单图 uuid-998被模型抽取后,发现结果不完整模型判断为低置信度(例如内部设定的
threshold = 0.6){ "姓名": null, "生效日期": "98-12-00", "保险金额": "30万" }1
2
3
4
5
② 记录错误日志(用于回流判断)系统将该次预测失败的上下文、评分、异常字段等信息写入日志
存入
model_inference_log表或日志服务,可视化平台实时看出问题样本趋势{ "file_id": "uuid-998", "confidence_score": 0.42, "error": "字段缺失", "status": "fail", "model_version": "v3.2.1", "timestamp": "2025-06-12T16:22:10" }1
2
3
4
5
6
7
8
③ 模型服务生成“回流任务(满足以下条件的预测会生成回流任务)条件项 示例 confidence_score < 0.6模型自己不确定 字段缺失/格式异常出生日期格式不合规、身份证号为空 关键字段为空姓名为 NULL OCR输出乱码比例过高字符错位等 生成任务结构如下,并发送到 Kafka 的
relabel_topic{ "file_id": "uuid-998", "model_version": "v3.2.1", "reason": "置信度过低", "fields": ["姓名", "生效日期"], "timestamp": "2025-06-12T16:22:11" }1
2
3
4
5
6
7
④ 调度系统处理回流任务Kafka 消费
relabel_topic调用 Redis 任务队列
task_queue:image_relabel然后调用标注平台 API,生成 补标任务,分配给专家组
- 人工重新填补字段
- 完成后 Webhook 通知平台,更新数据库,写入
label_version = v2
POST /api/tasks { "file_url": "https://minio.xxx/uuid-998.png", "label_type": "字段抽取", "fields": ["姓名", "生效日期"], "reason": "模型置信度低", "assigned_to": "expert_group" }1
2
3
4
5
6
7
8
# 02.模型训练模块
- 工程团队负责训练任务的分发、追踪、日志采集与状态监控,实现 训练任务编排、资源分配与失败容错
# 1、训练任务调度
详细调度,见
10.任务调度模块用户(或 MLOps 工程平台)通过 Web 控台提交训练请求,填写训练配置文件
job_name: ocr-v3.0 image: myregistry.com/ocr-trainer:latest dataset: invoice-clean-2025Q1 resources: gpu: 2 memory: 32Gi entrypoint: python train.py --epochs 30 --lr 1e-41
2
3
4
5
6
7后端将其编排为 Kubernetes Job(或 Volcano Job)并提交至 GPU 节点池
- Scheduler 会考虑 GPU 资源亲和性(如使用 NVIDIA MIG 分片)避免资源浪费
- 使用 Ray 时,可按 task 粒度并行训练子任务,如超参搜索
数据集挂载服务
后端服务识别
dataset: invoice-clean-2025Q1,从 MinIO / OSS 获取数据集的元信息(如 shards 列表、预处理参数)系统在容器启动阶段
- 自动从对象存储拉取
.tar.gz或分片数据 - 解压后挂载至训练容器
/data目录
- 自动从对象存储拉取
使用 cache 策略避免多任务重复下载(如 PersistentVolumeClaim + 数据卷绑定)
# 2、多版本训练配置管理
- 工程交付:训练任务参数化 + 模板化配置系统
模型平台维护通用训练模板,如
ocr-template.yaml用户只需提供差异参数(学习率、轮次、模型路径),系统自动合并模板生成实际任务配置
# auto-generated merged config for job-uuid-998 model: type: "pytorch" backbone: "resnet50" pretrained: true training: lr: 0.0005 # 被用户覆盖 batch_size: 8 # 被用户覆盖 epochs: 50 optimizer: "adam" data: train_path: "/mnt/datasets/policy/train" # 用户覆盖 val_path: "/mnt/datasets/policy/val" num_classes: 12 output: save_dir: "/mnt/models/policy-model-v2.0" # 用户覆盖 log_level: "INFO"1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
模板版本号与任务 UUID 绑定,支持版本追踪与 CI/CD trace
{ "job_id": "uuid-998", "template_used": "ocr-template.yaml@v2.1", "merged_config_path": "/mnt/configs/generated/job-uuid-998.yaml", "commit_sha": "a97cb21", # 当前平台代码/镜像版本 "triggered_by": "admin", "submit_time": "2025-06-12T11:05:22" }1
2
3
4
5
6
7
8
# 3、模型产物管理
- 工程交付:产物打包 + 上传服务,接入 MLflow / OSS 模型仓库
训练完成后,容器会将以下文件归档为产物目录
/outputs/ - model.bin - tokenizer.json - metrics.json - config.yaml1
2
3
4
5系统将产物 zip 上传至模型仓库(如 MLflow)
产物绑定:
- job_id
- dataset_id
- 模型版本号
ocr-v3.0 - 评估指标
元信息写入数据库,支持 UI / API 查询
训练完成后,会生成一批关键文件(模型权重、配置、指标等),称为产物(Artifacts)
假设你训练了一个 OCR 模型,命名为
ocr-v3.0,用于识别保单上的字段/outputs/ 目录内容
/outputs/ ├── model.bin # OCR 模型主文件(PyTorch) ├── tokenizer.json # 支持字段识别的字典文件 ├── metrics.json # {"f1": 0.92, "precision": 0.91, "recall": 0.90} ├── config.yaml # 完整配置(合并模板后的 YAML)1
2
3
4
5
在 MLflow UI 中就能清晰看到所有模型产物与评估指标,便于比较与回滚
import mlflow with mlflow.start_run(run_name="ocr-v3.0") as run: mlflow.log_artifact("outputs/model.bin") mlflow.log_artifact("outputs/tokenizer.json") mlflow.log_artifact("outputs/metrics.json") mlflow.log_artifact("outputs/config.yaml") mlflow.log_params({ "job_id": "998", "dataset_id": "456", "version": "ocr-v3.0", "template": "ocr-template-v2.1" }) mlflow.log_metrics({ "f1": 0.92, "precision": 0.91, "recall": 0.90 })1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
元信息写入数据库(支持查询)
字段 示例值 model_idocr-v3.0job_id998dataset_id456metrics{"f1": 0.92}artifact_urlmlflow://runs/abc123hasha21fe17e...create_time2025-06-12 11:22:01
# 4、错误恢复机制
- 工程交付:断点续训 / 自动重试机制
① 自动重启失败任务spec: backoffLimit: 3 # 最多失败重试 3 次 template: spec: restartPolicy: OnFailure # 节点/程序出错自动重启容器1
2
3
4
5
② 自动保存断点:checkpoint.pth(你训练脚本中加入)保存间隔:如每 N epoch
保存在 PVC 或 NAS 上,确保重启后还能访问
# 每 N epoch 保存断点 torch.save({ 'epoch': current_epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), }, "/checkpoints/checkpoint.pth")1
2
3
4
5
6
③ 容器重启后自动恢复训练脚本启动时先判断,从中断的位置 自动继续训练,无需人工干预
if os.path.exists("/checkpoints/checkpoint.pth"): checkpoint = torch.load("/checkpoints/checkpoint.pth") model.load_state_dict(checkpoint["model_state_dict"]) optimizer.load_state_dict(checkpoint["optimizer_state_dict"]) start_epoch = checkpoint["epoch"] + 1 else: start_epoch = 01
2
3
4
5
6
7
# 03.模型评测模块
- 提供一个支持多任务评测、自动打分、可配置评价指标的服务平台,供算法使用并进行评测版本管理
某 NLP 团队正在对三个模型版本
ocr-v2.5、ocr-v3.0、ocr-exp-newloss进行评测,目标是
- 使用统一测试集
invoice-test-2025Q1,评估字段抽取精度(Exact Match)、召回率(Recall)、OCR 候选文本的 BLEU 分数- 自动生成评测结果 Dashboard 与对比报告,供业务验收与版本上线参考
# 1、模型加载接口
- 工程交付:标准模型服务接口,封装 HuggingFace / ONNX / PyTorch 推理能力
业务场景:
- OCR 团队新训练出一个
invoice-v2.4模型(用 PyTorch) - 法务团队的模型
contract-analyzer-v3.1是 ONNX 格式 - 客服的智能问答模型是 HuggingFace 的
bert-qa-v1.5
- OCR 团队新训练出一个
设计一个统一模型服务标准POST /inference -> 输入数据 → 输出模型预测(JSON 格式)1
FastAPI 实现一个最小模型服务用户请求 JSON: {"image_url": "xxx"}
Flask 接收 POST 请求
预处理模块:下载图片、转换为张量、PyTorch 模型执行推理
后处理:转为 list JSON 格式化
app = Flask(__name__) model = torch.jit.load("model.pt") # 预加载模型权重 def preprocess(image_url): response = requests.get(image_url) img = Image.open(BytesIO(response.content)).convert("RGB") # 这里你根据模型需求进行 resize、normalize 等操作 return torch.tensor(...).unsqueeze(0) @app.route("/inference", methods=["POST"]) def inference(): data = request.json input_tensor = preprocess(data["image_url"]) output = model(input_tensor) # 假设输出是字段字典 return jsonify({ "status": "ok", "result": output.tolist() })1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Flask vs vLLM(适用场景对比)对比点 Flask 自建服务 vLLM / Triton / TorchServe 部署复杂度 低,快速上手 高,需要显卡、调度、容器管理 推理性能 低,单线程或简单多进程 高,GPU 并发、异步处理 适用模型 小模型 / CV模型 大语言模型(LLM)、多轮对话 扩展能力 差,需自研并发、路由等 完善,具备批处理、多模型管理等 企业生产 不推荐 推荐
# 2、评测指标模块
- 验证模型是否能准确识别图像中的目标区域(位置+字段标签+值),衡量模型泛化能力
评测流程① 模型推理对测试集中的每张图进行预测
得到:每个检测框的位置、字段类别、字段值、置信度
② 与标注数据对比- 将模型预测结果(pred.json)与人工标注(gt.json)进行字段级逐一比对
- 依据 IoU 和字段名称进行匹配,比较字段值是否完全一致(可容忍空格/符号误差)
- IoU 是否达标(> 0.5 通常认为匹配)
- 类型(字段名)是否一致
- 值是否完全一致(支持容错匹配,如空格、数字格式)
③ 计算指标判断预测对错,构建 confusion matrix(TP、FP、FN)
TP(预测出字段A,且位置+值都正确)
FP(预测出字段A,但实际上没有这个字段)
FN(标注有字段A,模型漏掉了)
统计 Precision / Recall / mAP
Precision 高:模型“不轻易出手”,但一出手就对
Recall 高:模型尽可能多地抓住所有目标,即使多预测一些错的
F1 高:说明模型既不瞎猜,也不会漏检,综合表现好
指标 公式 意义 Precision(精确率) TP / (TP + FP)模型预测的正例中,有多少是真的 Recall(召回率) TP / (TP + FN)所有真正的正例中,有多少被模型抓到 F1 Score 2 * (P * R) / (P + R)Precision 和 Recall 的调和平均,用于不均衡数据时更合理
# 3、结果持久化 + 可视化
结果持久化 + 可视化:构建“模型评测趋势图”
用户诉求:业务方想看到
“新模型真的变好了么?”
“上个月比这个月表现如何?”
“为什么这个样本预测错了?”
评测结果结构:
{ "model_version": "ocr-v2.4", "metric": "EM", "score": 0.923, "dataset": "invoice-test-2025", "timestamp": "2025-06-10" }1
2
3
4
5
6
7使用 PostgreSQL 存储评测元数据,ClickHouse 存储大规模得分记录(适合做聚合分析)。
前端展示方式
- 折线图:同一模型多版本对比趋势
- 雷达图:多个指标对比
- 样本 diff:高亮显示预测错的字段,供人工 review
# 4、模型对比报告生成
- 新模型必须经过评估对比,证明“有提升且不回退”,老板才能拍板上线
评分指标对比示例指标项 ocr-v2.5ocr-v3.0差值 高亮备注 字段级召回率 Recall 91.2% 94.6% +3.4% 提升明显 字段级精度 Precision 93.0% 93.3% +0.3% 小幅提升 坐标框 IOU ≥ 0.8 比例 85.5% 89.1% +3.6% 定位更精确 图片级漏识率 6.7% 3.9% -2.8% 漏识显著降低 平均识别耗时(1080P 图) 1.26s 1.45s +0.19s ⚠️ 有延迟增加(待评估)
报告生成形式/compare_reports/ └── ocr-v3.0_vs_ocr-v2.5/ ├── summary_metrics.html ├── samples_diff.html ├── report.pdf └── metadata.json1
2
3
4
5
6
导出的 PDF 报告内容(可下载)- 封面:模型名称、评测人、评测时间、对比对象、摘要指标
- 内容页:
- 指标对比图(条形图)
- 表格汇总(高亮变差项)
- 典型错样截图(前后版本对比)
- 总结建议(是否推荐上线)
- 页脚:版本号、Job ID、数据集 ID、评测 UUID
# 04.模型部署(CI/CD)
- 构建标准化、容器化的模型部署流程,实现模型的服务上线、灰度发布、版本回滚等全流程
| 模块 | 工程交付内容 |
|---|---|
| 模型服务封装 | 使用 FastAPI/BentoML/Triton 封装统一 API 服务 |
| 自动部署流水线 | CI/CD 流程:训练产物打包 → Docker 镜像构建 → 镜像推送 → K8s 部署 |
| 灰度发布控制器 | Argo Rollouts / Flagger 实现灰度 / A/B Test 发布 |
| 服务健康监控 | Prometheus + Grafana 实现请求延迟、错误率、QPS 等监控 |
| 日志与回溯 | 接入 OpenTelemetry / ELK 进行链路追踪与异常告警 |
| 自动回滚机制 | 发布失败时回滚上一个可用模型服务(蓝绿部署 / Canary) |
- 模型接口统一性(输入输出结构、版本号、调用协议)
- 模型部署的 SLA/高可用保障(多副本 + 弹性伸缩)
- 安全机制(API 权限、流量管控、内容过滤)
# 1、模型服务封装
模型服务封装:构建统一 API 层
场景:OCR/NLP/分类等模型五花八门,接口各异,调用方很难集成
技术方案:统一定义模型服务输入输出协议
- 输出统一带
status,result,error_code
POST /predict { "inputs": [...], "model_version": "xxx" }1
2
3
4
5- 输出统一带
支持三种封装方式:
- FastAPI:适合轻量 HTTP 接口部署
- BentoML:支持打包为 bundle,可部署为服务、Lambda、容器
- Triton:适合多模型 GPU 服务,支持并发推理 + ONNX/TF/PyTorch 等框架
自动生成 OpenAPI 文档,便于调用方自检和联调
# 2、自动部署CD
- 按部署目标和资源需求,主流技术可分为三类
| 技术方案 | 核心技术 | 适用场景 | 企业案例 |
|---|---|---|---|
| 轻量本地化 | Ollama、LM Studio | 个人测试、隐私敏感场景 | 教育演示 |
| 高性能推理 | vLLM | 高并发API服务、生产环境 | 电商客服 |
| 分布式容器化 | Kubernetes + Docker + NVIDIA NIM | 大模型多节点部署、弹性扩缩 | 千亿级模型 |
自动部署流水线:训练 → 镜像 → 上线
场景:模型训练完后需要手动部署,版本号混乱。
技术方案(CI/CD流程):使用 GitLab CI + ArgoCD 实现自动化流程
graph LR
训练产物 -->|产出模型.pt| 模型打包模块
模型打包模块 -->|构建 Docker 镜像| CI 构建
CI 构建 -->|推送 Harbor| 镜像仓库
镜像仓库 --> CD --> K8s 部署
2
3
4
5
- 自动生成版本信息(如
ocr-v3.2-commit-abc123-timestamp) - 模型服务配置注入 ConfigMap → Helm 模板化部署
- 整体部署耗时 < 2 分钟,支持并发多模型自动部署
# 3、灰度发布控制器
灰度发布控制器:模型迭代更安全
场景:新模型直接全量上线风险大,希望逐步放量或并行对比
使用 Argo Rollouts + Istio 实现以下策略
- Canary 发布:10% 流量 → 30% → 100%
- A/B Test:基于用户特征/请求参数分流
- 蓝绿部署:两个完整版本服务并行,选择切换时间点
配置自动指标门控策略(如 p95 延迟 < 200ms,错误率 < 1%)
# 4、服务健康监控
服务健康监控:可观测性 + SLA 保障
场景:无法实时了解模型是否稳定、是否超时、是否异常。
Prometheus + Grafana:
- 接入模型推理的耗时、QPS、错误率、CPU/GPU 占用等
- 支持 per-model version 级别的监控
设置 SLA 门限报警,如:
- 错误率持续 > 5% 触发告警
- CPU 占用 > 80% 持续 3min 自动弹性扩容
# 5、日志与回溯
日志与回溯:线上问题定位保障
OpenTelemetry 链路追踪:从调用入口 → 模型服务 →下游调用全链路追踪
日志归档接入 ELK(或 Loki + Grafana):
- 按模型版本、trace_id 索引
- 可查询某个请求链路中模型的预测耗时、错误栈
- 结合 Sentry 实现异常堆栈上报
# 6、自动回滚机制
自动回滚机制:防止“翻车”
新模型一上线就出现错误或指标恶化,希望自动恢复
灰度失败时,自动触发 Argo Rollouts 回滚到上一版本
保存每次上线的完整配置,支持一键 Rollback
支持 GitOps 方式版本回滚:代码版本就是部署状态
# 05.闭环自动触发
- 构建「数据反馈 → 自动训练 → 自动部署 → 回流再训练」的自动化闭环链路
| 阶段 | 模块 | 举例说明 |
|---|---|---|
| 数据反馈 | 数据触发器服务 | 用户上传一张异形发票,模型识别出的“金额字段为空” → 属于低置信度 → 自动记录该图片 ID |
| 数据反馈 | 数据标注平台 | 每晚系统收集低置信度数据(如 daily 500 张),自动分发给外包标注员进行金额字段回填 |
| 自动训练 | 流水线编排器 | 每周日晚运行 train_invoice_model.yaml 训练 DAG,步骤:加载新数据 → 清洗 → 训练 → 评估 → 上传产物 |
| 自动部署 | 评估触发器 + CI/CD | 新模型的 OCR 字段识别准确率从 92.3% 提升到 94.7%,通过阈值 → 自动打包 → 推送镜像 → K8s 灰度上线 |
| 再回流 | 线上反馈处理器 | 上线后实时监控错识票据(用户纠错行为 + 标签反馈)→ 自动收集 → 入库 → 下一轮训练 |
# 10.任务调度
- 自动化、智能化地管理训练与推理任务中的计算资源(主要是GPU)
- 确保资源利用最大化,同时保障任务时效与公平
- 用户通过 Mage 平台提交一个模型训练任务,指定需要使用 GPU 资源
- 平台将该任务调度到合适的 GPU 节点上执行,并确保资源合理分配、故障可恢复、任务可监控
# 1、任务定义提交阶段
用户在前端或 CLI 提交任务时,平台将任务参数转化为 Kubernetes Job / CRD 资源
与 CPU 任务不同,GPU 任务必须设置
nvidia.com/gpu且
调度器会自动识别这些字段触发GPU-aware 调度路径
apiVersion: batch/v1
kind: Job
metadata:
name: train-task-abc123
namespace: ml-training
spec:
template:
spec:
containers:
- name: train
image: mage-registry/model-train:v1.0
resources:
limits:
nvidia.com/gpu: 2 # 必须显式声明 GPU 数量
cpu: "4"
memory: "16Gi"
restartPolicy: Never
tolerations: # 支持带 GPU 污点的节点调度
- key: "gpu"
operator: "Exists"
effect: "NoSchedule"
nodeSelector: # 或 node affinity 限定 GPU 类型
accelerator: "nvidia-a100"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 2、调度器调度阶段
- GPU 任务不能走默认的 K8s 调度器(
default-scheduler)路径 - 平台通常会使用自定义调度器插件,如
- Volcano (opens new window)(支持 gang scheduling、抢占、优先级队列)
- 或自研调度器插件(拦截并调度 GPU Pod)
调度流程如下
① 调度器接收 Pending GPU Pod② 过滤器阶段(Filter)- 资源是否满足:GPU 数量是否足够(包括显存)
- 污点/容忍度是否匹配(如节点打了
gpu=NoSchedule) - GPU 类型是否匹配(A100/V100/T4 等)
③ 优先级排序(Score)- 节点剩余资源率(prefer pack or spread)
- GPU Fragmentation(是否产生 GPU 零碎分配)
- 历史失败率(避免分配到 flaky 节点)
④ 抢占检查(Preemption)- 若所有节点资源不足,是否可以抢占低优先级任务释放资源
- 会在被抢占任务 Pod 上打上
deletionTimestamp,然后调度新任务
⑤ 绑定阶段(Bind)- 将 Pod 与目标 Node 绑定,并正式调度执行
# 3、节点执行准备
GPU Pod 调度成功后,节点上的 kubelet 启动容器
必须预先部署 NVIDIA Device Plugin (opens new window)
- 该插件通过共享内存
/var/lib/kubelet/device-plugins/与 kubelet 通信 - 注册
nvidia.com/gpu资源,并将 GPU 分配挂载到容器
- 该插件通过共享内存
若使用的是 containerd,则还需要
nvidia-container-runtime平台通常会抽象为「GPU Node 镜像准备就绪」状态,统一管理驱动版本、CUDA等依赖
# 4、自动回收与抢占逻辑
自动回收机制训练任务完成后,Job Controller 自动清理 Pod、PVC、挂载资源
GPU利用率 <10%、持续15分钟无stdout → 触发资源回收(需双确认)
推理服务长时间无QPS → 卸载容器或缩容副本
抢占策略(自研或基于 Volcano)高优任务提交 → 查询是否存在可抢占任务
- 判断是否满足抢占条件:
- 被抢任务优先级低、运行时间短、非关键任务
被抢占任务触发 graceful termination(写入日志 + graceful shutdown)
# 5、go-client调用
- 在平台后端(Golang),你们可能是通过
client-go编排 + 补充调度元信息
job := &batchv1.Job{
ObjectMeta: metav1.ObjectMeta{
Name: "train-job-001",
Namespace: "ml-training",
},
Spec: batchv1.JobSpec{
Template: corev1.PodTemplateSpec{
Spec: corev1.PodSpec{
Containers: []corev1.Container{{
Name: "train",
Image: "myimage:v1",
Resources: corev1.ResourceRequirements{
Limits: corev1.ResourceList{
"nvidia.com/gpu": resource.MustParse("2"),
"cpu": resource.MustParse("4"),
"memory": resource.MustParse("16Gi"),
},
},
}},
RestartPolicy: corev1.RestartPolicyNever,
Tolerations: []corev1.Toleration{{
Key: "gpu",
Operator: corev1.TolerationOpExists,
Effect: corev1.TaintEffectNoSchedule,
}},
NodeSelector: map[string]string{
"accelerator": "nvidia-a100",
},
},
},
},
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 6、调度前置服务
client-go是 单集群访问客户端,它一次只能连接一个 Kubernetes API Server- 平台支持多个 GPU 集群(如 A100 集群、V100 集群、跨机房集群),每个集群的 GPU 资源、节点状态都不同
- 因此,在
client-go发起 Job 创建前,平台必须先决策:调度到哪个集群、哪个 namespace
核心思路
- 在任务提交阶段,引入一个统一的调度前置服务(Multi-cluster GPU Dispatcher)
根据资源/策略/用户权限等进行智能选址
资源采集器(GPU集群状态聚合器)
各个集群部署资源上报组件(如 Metrics Server、Prometheus Exporter、Node Exporter)
周期性(如每 10 秒)汇总各集群的 GPU 总量、剩余量、当前负载、GPU类型、任务排队情况
将数据汇总到中央调度前置服务中,存入 Redis 或内部内存缓存
调度前置逻辑(Dispatcher)
平台在任务提交时,不直接使用 client-go 发请求,而是走调度前置服务
维度 决策逻辑示例 GPU 类型匹配 只考虑具备指定 GPU 型号的集群 GPU 利用率 优先调度到当前剩余最多的集群 排队时延预测 估算 job 启动时间,避免盲目排队 节点亲和性 若有镜像缓存、数据分布,优先靠近调度 用户权限 校验该用户是否具备目标集群权限 灰度实验策略 可动态打标:某类模型优先跑新集群
多集群 client-go 实例管理
- Dispatcher 拥有每个集群的 KubeConfig,通过动态切换
rest.Config实例来访问目标集群
- Dispatcher 拥有每个集群的 KubeConfig,通过动态切换
Namespace 映射和租户隔离
- 每个 GPU 集群预先创建对应的 namespace,如
ns-dev,ns-prod - 调度策略根据任务环境自动分配
- 训练任务 →
training-ns - 推理任务 →
serving-ns
- 训练任务 →
- 也支持一套租户规则
- 用户 ID
u123→ 所属 namespace 映射规则
- 用户 ID
- 每个 GPU 集群预先创建对应的 namespace,如
支持调度失败回退重试
- 如果 Dispatcher 调度到 A 集群,但任务因资源不足或抢占失败长时间排队,可加入自动 failover
- 任务状态中心定时检查排队任务状态
- 若 10 分钟未调度成功 → 回滚任务 → 重调度 B 集群
- 可结合任务重入幂等机制,保证任务不会重复执行