 09.SQL执行过程 ✅常识原理
09.SQL执行过程 ✅常识原理
MySQL 分为三层结构:
- 客户端层 处理网络连接和授权认证
- 服务层负责查询解析、优化、缓存以及存储过程、视图等
- 存储层用于数据存储和引擎的交互
存储引擎层和文件系统交互,支持插件式引擎,如 MyISAM 和 InnoDB。
查询时,MySQL先进行 SQL 解析,再由优化器选择执行路径,最后通过存储引擎获取数据,结果返回客户端并可能缓存。
# 01.MySQL体系架构
# 0、MySQL架构图
- 第一层:
客户端层(处理网络连接)- 连接处理、
授权认证、安全等功能均在这一层处理
- 连接处理、
- 第二层:
服务层查询解析、分析、优化、缓存、内置函数(比如:时间、数学、加密等函数)- 所有的跨存储引擎的功能也在这一层实现:存储过程、触发器、视图等
- 第三层:
存储层- 负责MySQL中的数据存储和提取,和Linux下的文件系统类似,每种
存储引擎都有其优势和劣势 - 中间的服务层通过API与存储引擎通信,这些API接口屏蔽了不同存储引擎间的差异
- 负责MySQL中的数据存储和提取,和Linux下的文件系统类似,每种
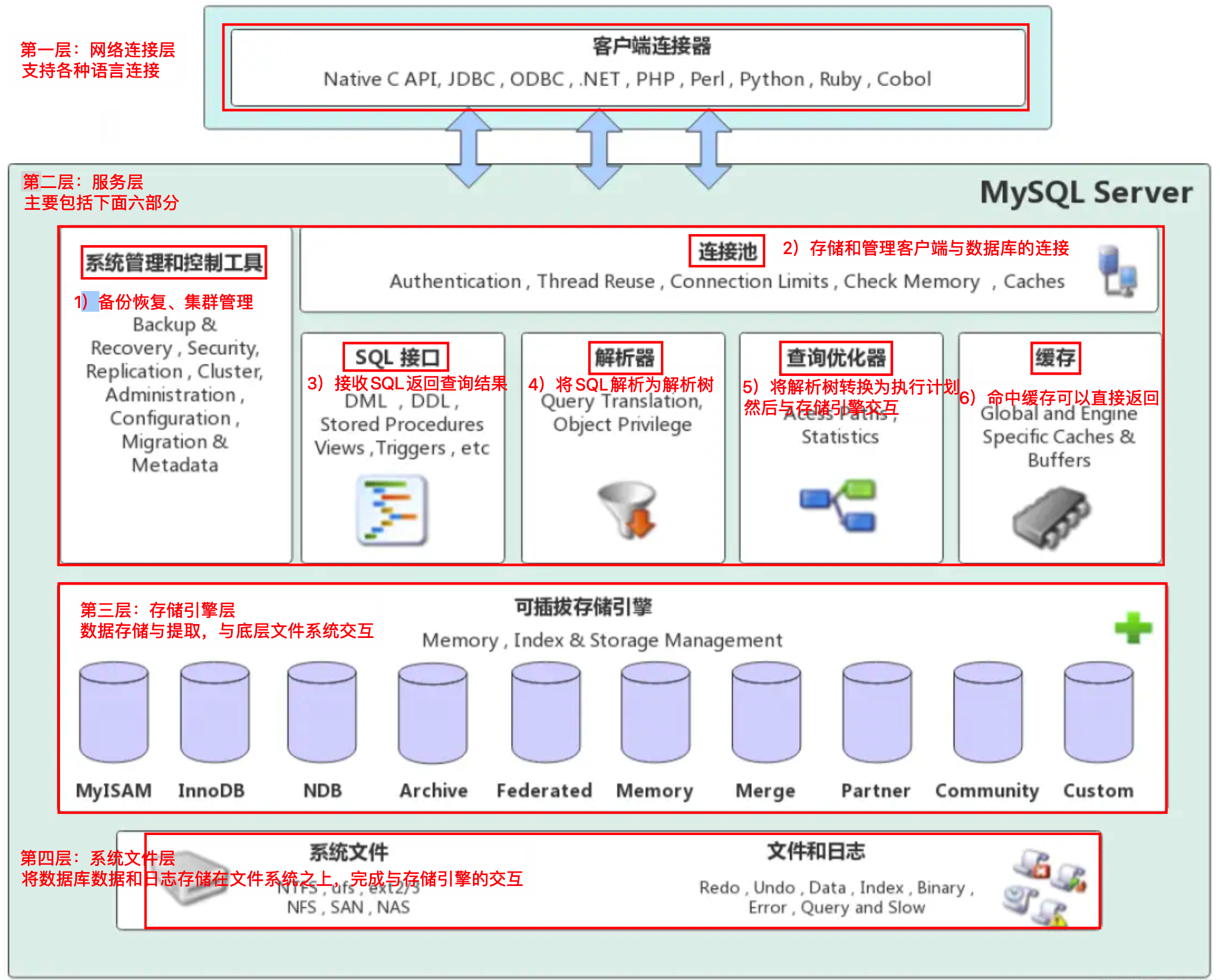
# 1、网络连接层
- 客户端连接器(Client Connectors):提供与MySQL服务器建立的支持
- 例如常见的 Java、C、Python、.NET等,它们通过各自API技术与MySQL建立 连接
# 2、服务层
服务层是MySQL Server的核心,主要包含系统管理和控制工具、连接池、SQL接口、解析器、查询优 化器和缓存六个部分
1)系统管理和控制工具(Management Services & Utilities)- 例如备份恢复、安全管理、集群管理等
2)连接池(Connection Pool)- 负责存储和管理客户端与数据库的连接,一个线程负责管理一个连接。
3)SQL接口(SQL Interface)- 用于接受客户端发送的各种SQL命令,并且返回用户需要查询的结果
- 比如DML、DDL、存储过程、视图、触发器等
4)解析器(Parser)- 负责将请求的SQL解析生成一个"解析树"
- 然后根据一些MySQL规则进一步检查解析树是否合法
5)查询优化器(Optimizer)- 当“解析树”通过解析器语法检查后,将交由优化器将其转化成执行计划,然后与存储引擎交互
6)缓存(Cache&Buffer)- 如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据
# 3、存储引擎层
- 存储引擎负责MySQL中数据的存储与提取,与底层系统文件进行交互
- MySQL存储引擎是插件式的,服务器中的查询执行引擎通过接口与存储引擎进行通信,接口屏蔽了不同存储引擎之间的差异
- 现在有很多种存储引擎,各有各的特点,
最常见的是MyISAM和InnoDB
# 4、系统文件层
该层负责将数据库的数据和日志存储在文件系统之上,并完成与存储引擎的交互,是文件的物理存储层
主要包含日志文件,数据文件,配置文件,pid 文件,socket 文件等
- 日志文件 :
- 错误日志(Error log): 默认开启,show variables like '%log_error%' 进入MySQL查看存放位置
- 通用查询日志(General query log):查看命令:show variables like '%general%';
- 二进制日志(binary log): 俗称binlog,记录更改操作,发生时间、执行时长
- show variables like '%log_bin%'; //是否开启
- show variables like '%binlog%'; //参数查看
- show binary logs;//查看日志文件
- 慢查询日志(Slow query log): 记录所有执行时间超时的查询SQL,默认是10秒。生产环境必选配置
- show variables like '%slow_query%'; //是否开启
- show variables like '%long_query_time%'; //时长
- 配置文件 : 用于存放MySQL所有的配置信息文件,比如my.cnf、my.ini等。
- 数据文件 : 日常都是 InnoDB,重点了解后三个文件作用
- db.opt 文件:记录这个库的默认使用的字符集和校验规则。
- frm 文件:存储与表相关的元数据(meta)信息,包括表结构的定义信息等,每一张表都会有一个frm 文件。
- MYD 文件:MyISAM 存储引擎专用,存放 MyISAM 表的数据(data),每一张表都会有一个.MYD 文件。
- MYI 文件:MyISAM 存储引擎专用,存放 MyISAM 表的索引相关信息,每一张 MyISAM 表对应一个 .MYI 文件。
- ibd文件和 IBDATA 文件:存放 InnoDB 的数据文件(包括索引)。
- ibdata1 文件:系统表空间数据文件,存储表元数据、Undo日志等 。
- ib_logfile0、ib_logfile1 文件:Redo log 日志文件。
# 02.MySQL运行机制
# 0、MySQL查询过程
MySQL整个查询执行过程,总的来说分为6个步骤
- 1)客户端
发送一条SQL查询请求到服务器。 - 2)服务器首先进行
SQL解析- 包括词法分析和语法分析,确认SQL语句的语法是否正确,并将SQL语句转换为数据库可以理解的形式
- 3)优化器
查询优化- 优化器接下来进行查询优化,选择最佳的查询路径
- 包括选择哪些索引进行查询,使用何种查询方法(全表扫描、索引扫描等),如何进行表连接等
- 4)执行器
从存储引擎中获取数据- 优化器将优化后的查询计划交给
执行器 - 执行器根据优化器给出的查询计划
从存储引擎中获取数据
- 优化器将优化后的查询计划交给
- 5)存储
引擎将数据返回给执行器,执行器对数据进行排序、分组、聚合等操作 - 6)
执行器将最后的查询结果返回给客户端
注:这个过程中,还可能涉及到
权限的检查、事务的处理、缓存的利用等操作
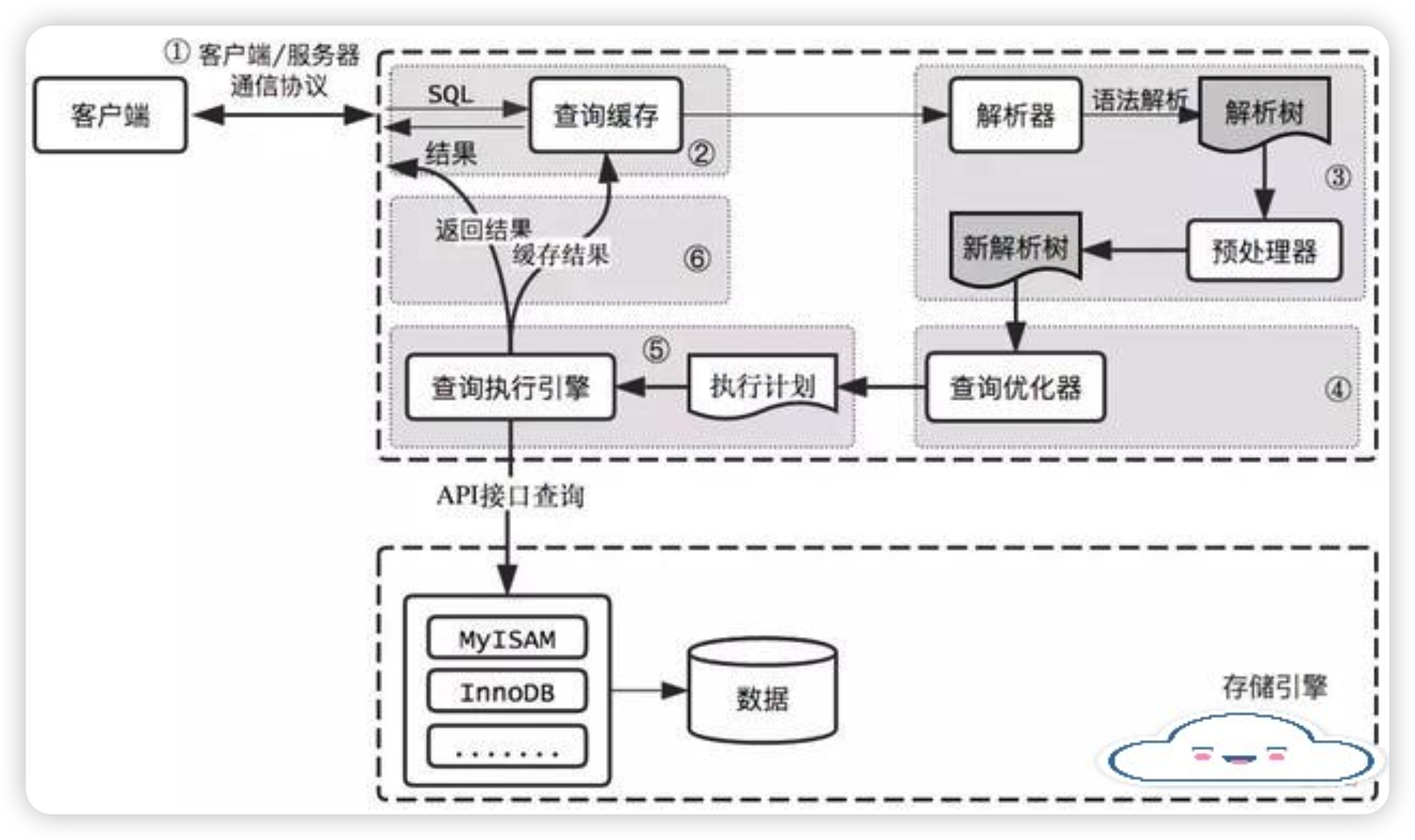
# 1、 建立连接
- MySQL客户端/服务端通信协议是
半双工的 - 在任一时刻,要么是服务器向客户端发送数据,要么是客户端向服务器发送数据
- 所以我们无法也无须将一个消息切成小块独立发送,也没有办法进行流量控制
- 客户端用一个
单独的数据包将查询请求发送给服务器,如果查询太大服务端会抛出异常 - 服务器响应客户端数据可以很大,客户端必须要接收整个结果,而不是几条结果
减小通信间数据包的大小和数量是一个非常好的习惯- 这也是查询中尽量避免使用
SELECT *以及加上LIMIT限制的原因之一
# 2、查询缓存
缓存作用如果查询缓存是打开的,那么MySQL会检查这个查询语句
是否命中查询缓存中的数据如果当前查询恰好命中查询缓存,再检查一次用户权限后
直接返回缓存中的结果这种情况下,
查询不会被解析,也不会生成执行计划,更不会执行
缓存数据格式- MySQL将
缓存存放在一个引用表(不要理解成table,可以认为是类似于HashMap的数据结构) - 这个哈希值通过查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息计算得来
- 所以两个查询在
任何字符上的不同(例如:空格、注释),都会导致缓存不会命中
- MySQL将
那些类型数据不会缓存- 如果查询中包含任何
用户自定义函数、存储函数、用户变量、临时表、MySQL库中的系统表,其查询结果都不会被缓存 - 比如函数NOW()或者CURRENT_DATE()会因为不同的查询时间,返回不同的查询结果
- 总之查询语句会因为
不同的用户而返回不同的结果,这种查询都不会缓存
- 如果查询中包含任何
缓存失效- 如果这些
表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效 - 在
任何的写操作时,MySQL必须将对应表的所有缓存都设置为失效
- 如果这些
缓存使用建议注:不要轻易打开查询缓存,特别是写密集型应用- 任何的查询语句在开始之前
都必须经过检查,即使这条SQL语句永远不会命中缓存 - 如果查询结果
可以被缓存,那么执行完成后,会将结果存入缓存,也会带来额外的系统消耗 - 用多个小表代替一个大表,注意不要过度设计
批量插入代替循环单条插入- 合理控制缓存空间大小,一般来说其大小设置为几十兆比较合适
- 可以通过SQL_CACHE和SQL_NO_CACHE来控制某个查询语句是否需要进行缓存
# 3、解析器SQL
- MySQL通过关键字将SQL语句进行解析,并
生成一颗对应的解析树 - 这个过程解析器主要通过
语法规则来验证和解析 - 比如SQL中是否
使用了错误的关键字或者关键字的顺序是否正确等等 预处理则会根据MySQL规则进一步检查解析树是否合法- 比如检查要查询的
数据表和数据列是否存在等等
# 4、优化SQL (查询优化器)
根据“解析树”生成最优的执行计划
MySQL使用很多优化策略生成最优的执行计划,可以分为两类
静态优化(编译时优化)
动态优化(运行时优化)
- 等价变换策略:
- 5=5 and a>5 改成 a > 5
- a < b and a=5 改成b>5 and a=5
- 基于联合索引,调整条件位置等
- 优化count、min、max等函数
- InnoDB引擎min函数只需要找索引最左边
- InnoDB引擎max函数只需要找索引最右边
- MyISAM引擎count(*),不需要计算,直接返回
- 提前终止查询
- 使用了limit查询,获取limit所需的数据,就不在继续遍历后面数据
- in的优化:
- MySQL对in查询,会先进行排序,再采用二分法查找数据
- 比如where id in (2,1,3),变成 in (1,2,3)
# 5、查询执行引擎
- 在完成解析和优化阶段以后,MySQL会生成对应的
执行计划,查询执行引擎根据执行计划给出的指令逐步执行得出结果 - 整个执行过程的大部分操作均是通过
调用存储引擎实现的接口来完成,这些接口被称为handler API - MySQL在查询优化阶段就为
每一张表创建了一个handler实例 - 优化器可以根据这些实例的接口
来获取表的相关信息,包括表的所有列名、索引统计信息等 - 存储引擎接口提供了非常丰富的功能,但其底层仅有几十个接口,这些接口
像搭积木一样完成了一次查询的大部分操作
# 6、返回结果给客户端
查询执行的最后一个阶段就是将结果返回给客户端
即使查询不到数据,MySQL仍然会返回这个查询的相关信息,比如该查询影响到的行数以及执行时间等等
如果查询缓存被打开且这个查询可以被缓存,MySQL也会将结果存放到缓存中
结果集返回客户端是一个增量且逐步返回的过程
- 有可能MySQL在生成第一条结果时,就开始向客户端逐步返回结果集了
- 这样服务端就无须存储太多结果而消耗过多内存,也可以让客户端第一时间获得返回结果
# 03.查询分析
select * from tb_student A where A.age='18' and A.name=' 张三 ';
1
- 1)鉴权&查询缓存
- 先检查该语句是否有权限,如果没有权限,直接返回错误信息
- 会先查询缓存,如果有直接缓存使用缓存
- 2)词法分析
- 通过分析器进行词法分析,提取 SQL 语句的关键元素
- 比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'
- 然后判断这个 SQL 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步
- 3)查询优化
- 接下来就是优化器进行确定执行方案
- 上面的 SQL 语句,可以有两种执行方案
- a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18
- b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生
- 那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)
- 那么确认了执行计划后就准备开始执行了
- 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果
上次更新: 2025/4/29 17:38:19