 03.支持10万QPS的会员系统 ✅
03.支持10万QPS的会员系统 ✅
ES双中心主备集群
- 主集群部署在机房A,备集群在机房B,通过MQ同步数据主集群故障时,切换至备集群
- 流量隔离:独立营销集群处理营销活动请求,避免影响主流业务
- 优化:调整ES线程池大小,使用filter替代query查询,降低CPU消耗
Redis缓存一致性
- 双写机制:更新缓存时,双机房Redis集群同时写入,确保一致性
- 解决ES延时问题:更新ES时加2秒分布式锁,并删除Redis缓存,防止旧数据写入
MySQL双中心集群
- 分片处理十亿级数据,1主3从架构,主库在机房A,从库在机房B,延迟低于1毫秒
- 读写分离:写操作路由至主库,读操作路由至本地从库,支持主库故障时从库升级为主库
SqlServer迁移至MySQL
- 实时双写:主写SqlServer,异步写MySQL,失败重试三次并记录日志
- 灰度切换:全量同步后,增量双写,逐步灰度1%流量至MySQL
服务降级与流控
- MySQL异常时,读写切至ES,写入流量暂存MQ,恢复后同步至MySQL
- 流控策略:按账号设置阈值,超限时快速失败,防止系统崩溃
# 01.支持10万QPS的会员系统
只有查到对应的艺龙会员卡号后,才能将红包挂载到该会员账号
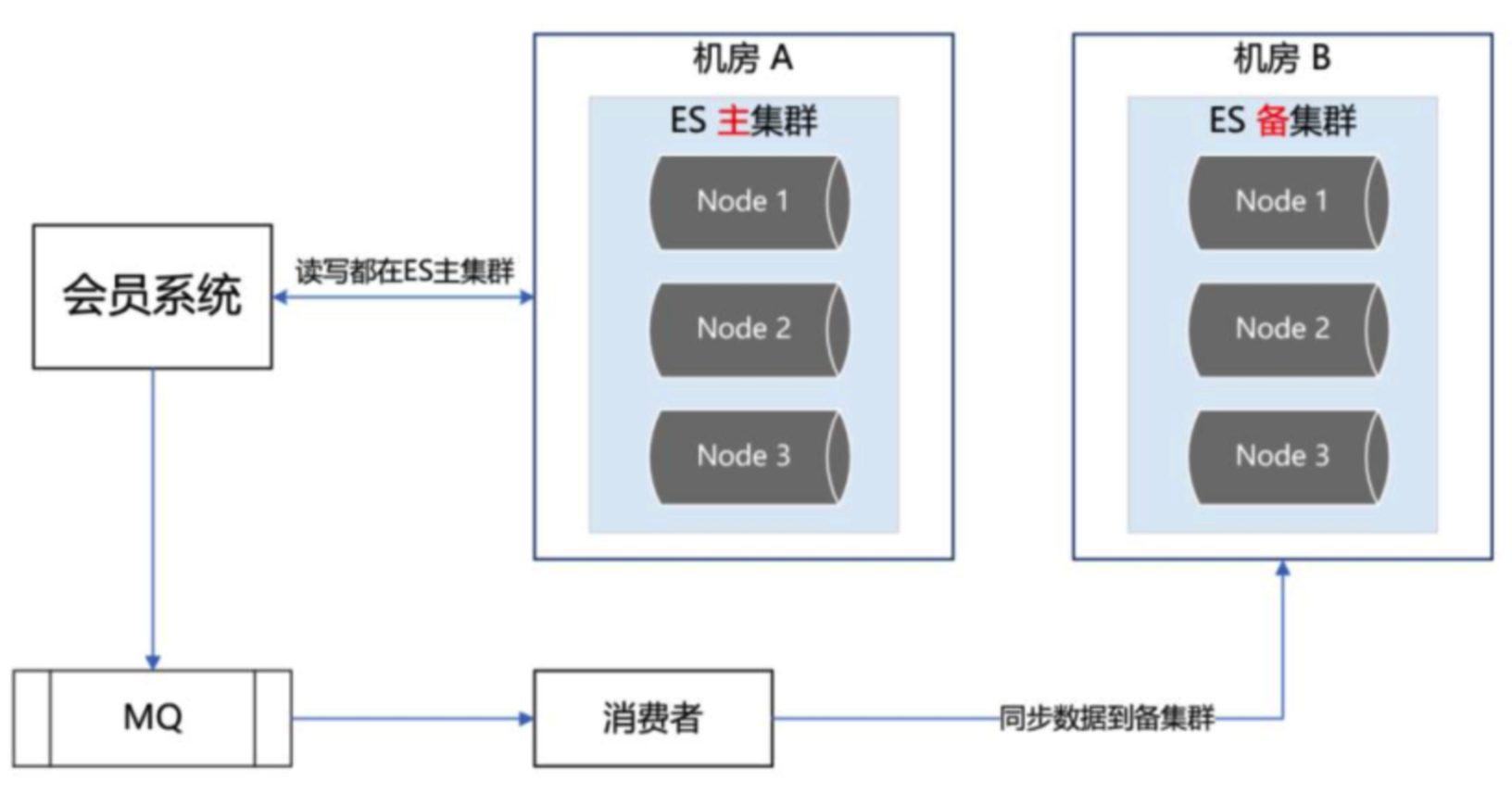
# 1、ES 双中心主备集群架构
集群架构我们把 ES 主集群部署在机房 A,把 ES备集群部署在机房 B
会员系统的读写都在 ES 主集群,通过 MQ 将数据同步到 ES备集群
此时,如果 ES 主集群崩了,通过统一配置,将会员系统的读写切到机房 B 的 ES 备集群上
流量隔离三集群架构- 在下图集群中
机房B简历一个专门的ES 营销集群 - 营销活动相关的大量冲击请求单独查询
ES 营销集群 - 这样就可以保证 营销类流量 不会影响 用户的下单主流(流量隔离、降级)
- 在下图集群中
ES 集群深度优化提升- ES 线程池的大小设置得太高,导致 cpu 飙高, 一般将线程数设置为服务器的 cpu 核数
- ES 查询,使用 filter,不使用 query,query 会对搜索结果进行相关度算分,比较耗 cpu
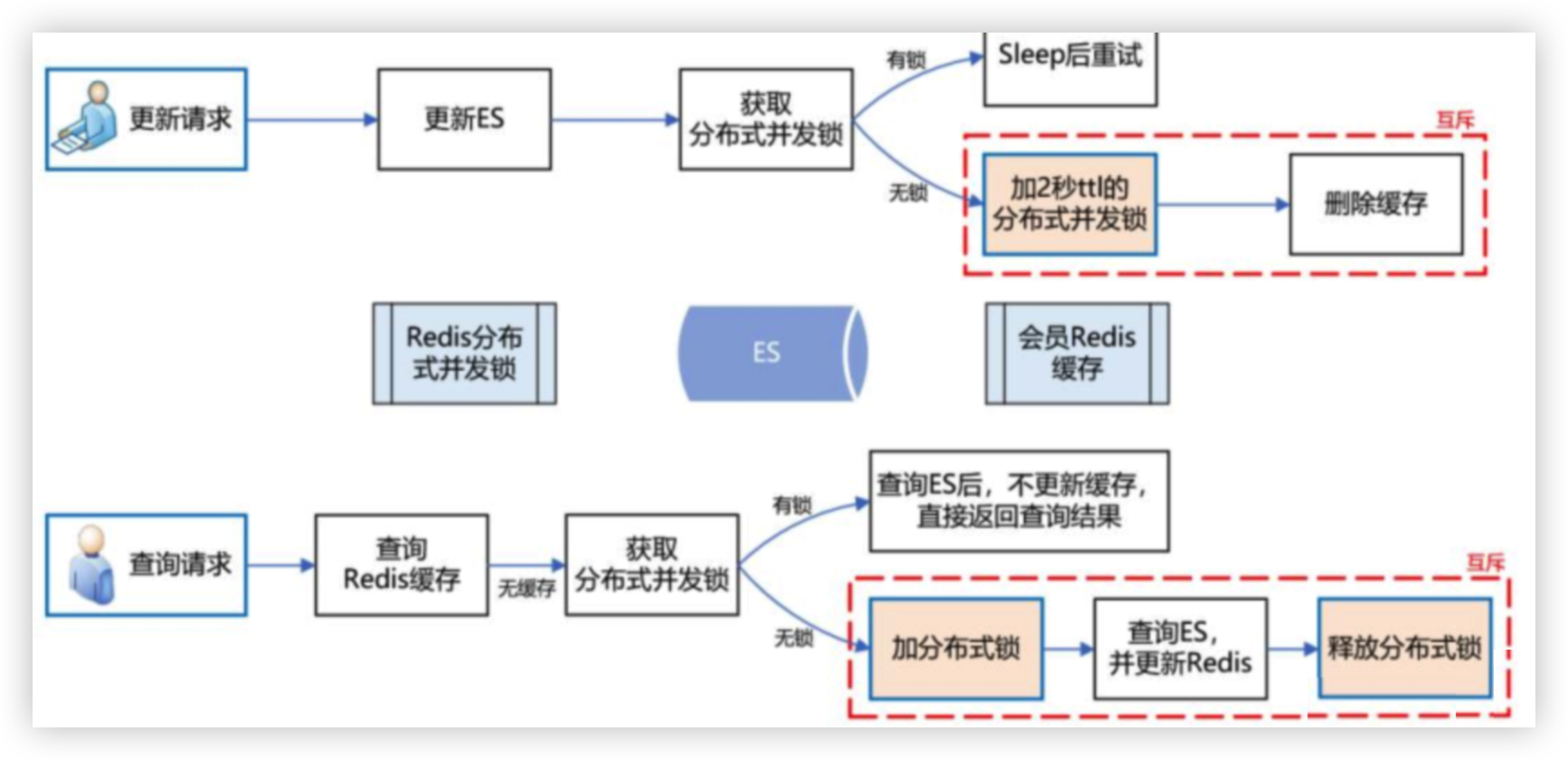
# 2、ES延时导致和Redis不一致问题
- 在机房 A 和机房 B 各部署一套 Redis 集群
- 更新缓存数据时,双写,只有两个机房的 Redis 集群都写成功了,才返回成功
- 查询缓存数据时,机房内就近查询,降低延时
不一致原因ES 操作数据是近实时的,,需要等待 1 秒后才能查询到
ES更新了但还未同步,如果此时查询会把ES旧数据写入Redis导致数据不一致
解决方案
- 在更新 ES 数据时,加一个 2 秒的 Redis分布式并发锁
- 为了保证缓存数据的一致性,接着再删除 Redis 中该会员的缓存数据
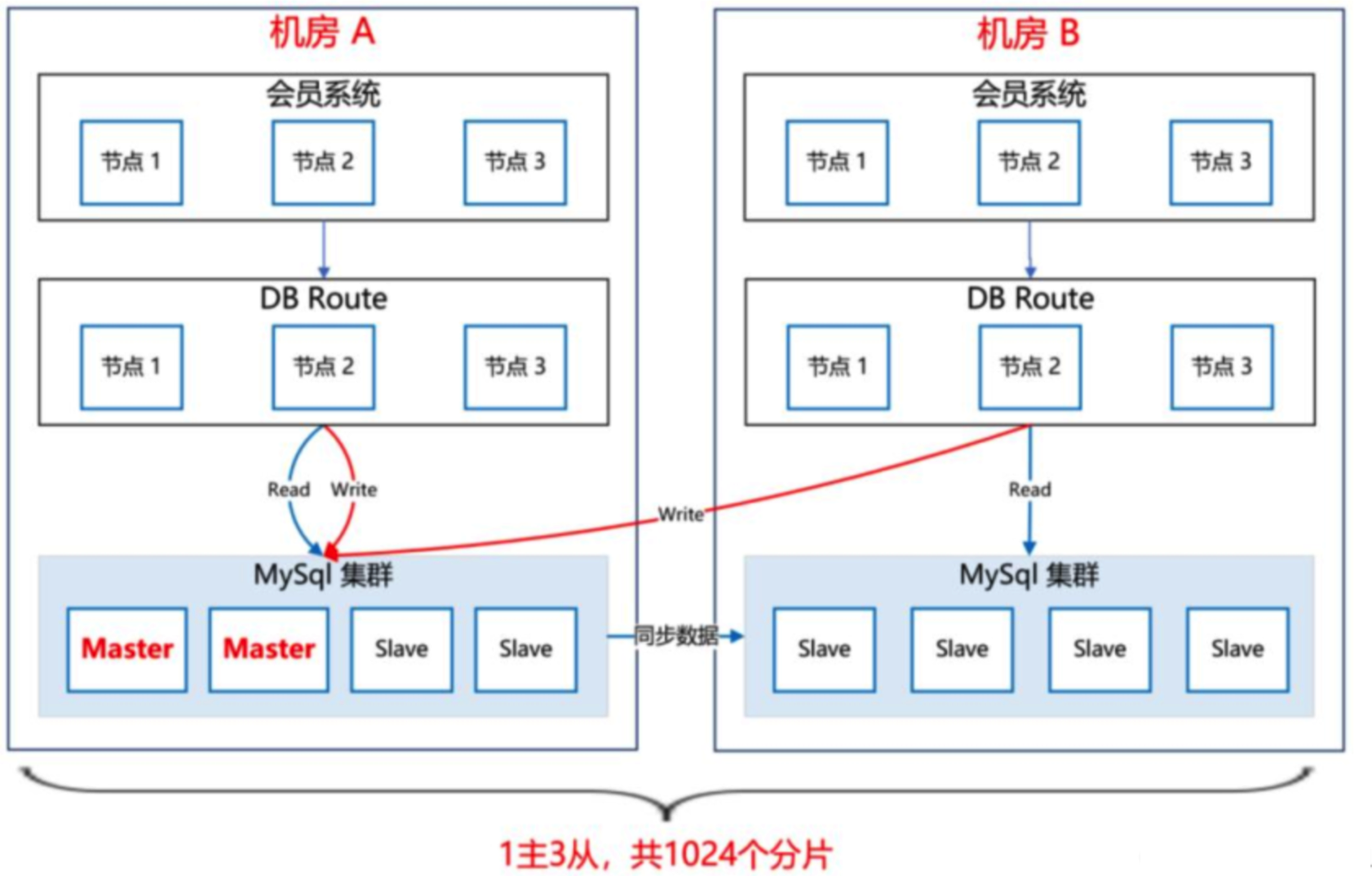
# 3、MySQL双中心集群方案
会员一共有十多亿的数据,我们把会员主库分了 1000 多个分片,平分到每个分片大概百万的量级
MySQL 集群采用 1 主 3 从的架构,主库放在机房 A,从库放在机房 B,两个机房之间通过专线同步数据,延迟在 1 毫秒内
通过
DBRoute读写数据,写数据都路由到 master 节点所在的机房 A,读数据都路由到本地机房即使机房 A 整体都崩了,还可以将机房 B 的 Slave 升级为 Master,继续提供服务
压测结果:秒并发能达到 2 万多,平均耗时在 10 毫秒内,性能达标
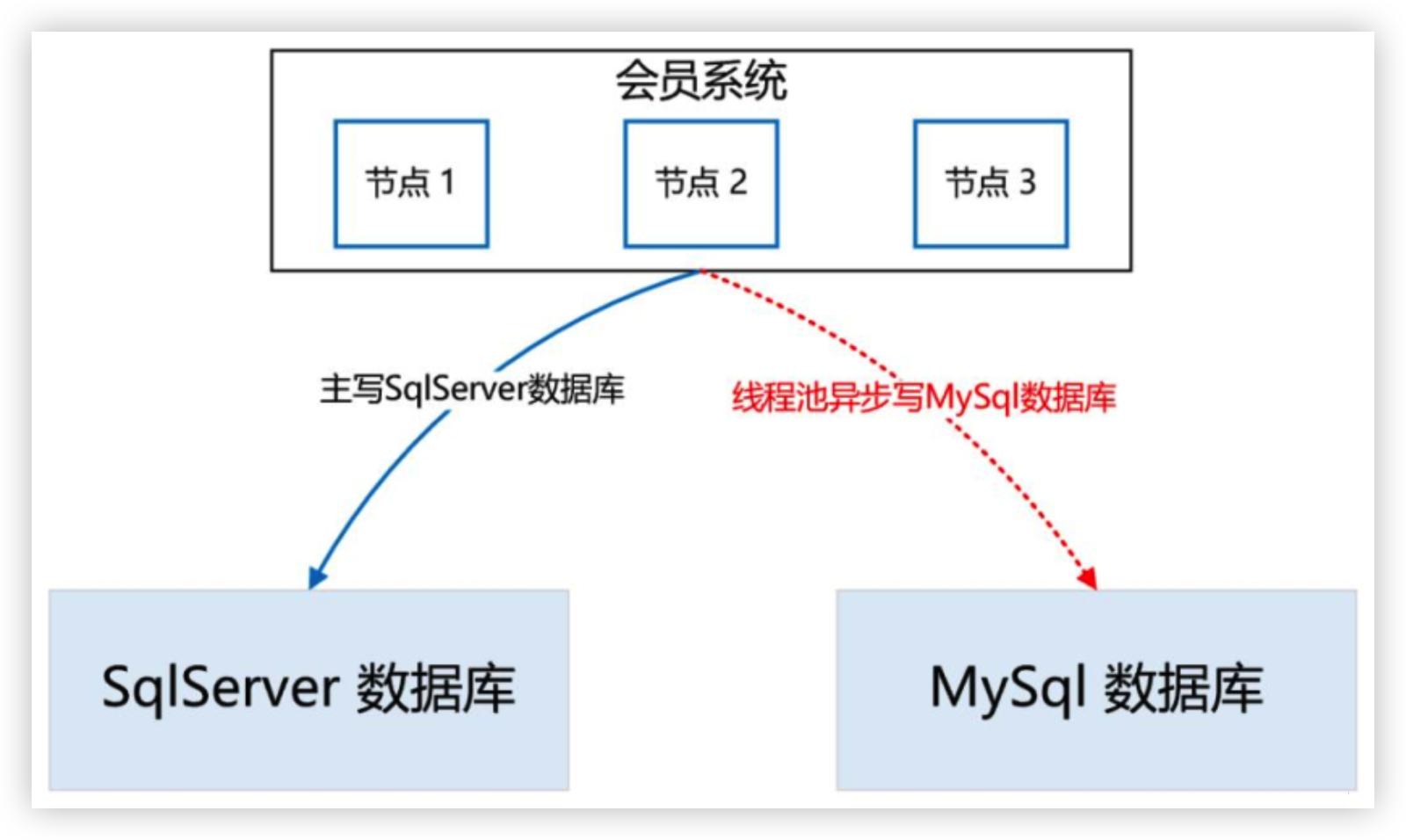
# 4、SqlServer迁移到MySQL
为了保证数据的无缝切换,采用
实时双写的方案主写 SqlServer,采用实时双写的方案池异步写MySQL,如果写失败了,重试三次如果依然失败,则记日志,然后人工排查原因,解决后,继续双写,直到运行一段时间,没有双写失败的情况
即使在试运行期间出现了 SqlServer 和 MySQL 的数据不一致的情况,也可以
基于 SqlServer再次全量构建出 MySQL 的数据整个流程
- 第一步:SqlServer全量同步到MySQL
- 第二步:增量同步数据,实现SqlServer和MySQL试试双写
- 第三步:灰度 1% 流量到MySQL读请求
# 5、服务降级方案
MySQL 异常 直接读写 ES- 如果 MySQL 数据库挂了,可以把读写切到 ES,把写入流量暂时写入到MQ中
- 等 MySQL 恢复了,再从MQ把数据同步到 MySQL,最后把读写再切回到 MySQL 数据库
流控策略- 针对每个调用账号设置流控规则,当超过阈值时,实施限流策略
- 当流量过大超过最大流量,可以快速失败,不会让整个会员系统全部崩溃
上次更新: 2025/4/29 17:38:19