 02.ES介绍
02.ES介绍
# 01.ES功能与特点
# 1、ES是什么
特点: 非关系型、搜索引擎、近实时搜索与分析、高可用、天然分布式、横向可扩展
ES是一个分布式、可扩展、实时的搜索与数据分析引擎
ES不仅仅只是全文搜索,还支持结构化搜索、数据分析、复杂的语言处理、地理位置和对象间关联关系等
ES的底层依赖Lucene,Lucene可以说是当下最先进、高性能、全功能的搜索引擎库
为什么不直接使用Lucene?
但是Lucene仅仅只是一个库,你需要使用Java并将Lucene直接集成到应用程序中
您可能需要获得信息检索学位才能了解其工作原理,因为Lucene非常复杂
ES也是使用Java编写的,它的内部使用Lucene做索引与搜索
它的目的是隐藏Lucene的复杂性,取而代之的提供一套简单一致的RESTful API
# 2、ES主要功能
- 分布式实时文件存储,处理的结构化和非结构数据
- 实时分析的分布式搜索引擎,为用户提供关键字查询的全文检索功能
- 是实现企业级PB级海量数据处理分析的大数据解决方案(ELK)
ES主要致力于结构化和非结构化数据的分布式实时全文搜索及分析,使用场景
- 日志管理与分析(ELK)
- 系统指标分析
- 安全分析
- 企业搜索(OA、CRM、ERP)
- 网站搜索(电商、招聘、门户)
- 应用搜索
- 应用性能管理APM
# 02.ES主要特点
# 2.1 分片与集群
- ES默认把数据分成多个片,多个片可以组成一个完整的数据,这些片可以分布在集群中的各个机器节点中
- 随着后期数据的越来越大,ES集群可以增加多个分片,把多个分片分散到更多的主机节点上
- ES集群可以增加多个分片,把多个分片分散到更多的机器主机节点上,负责负载均衡,横向扩展
- 而每个查询任务提交到某一个节点,该节点必须负责将数据进行整理汇聚,再返回给客户端
# 2.2 自动索引
- ES所有数据默认都是索引的
- ES只有不加索引才需要额外处理
# 2.3 搜索是近实时的
- 你往 es 里写的数据,实际上都写到磁盘文件里去了
- 查询的时候,操作系统会将磁盘文件里的数据自动缓存到 filesystem cache 里面去。
- es 的搜索引擎严重依赖于底层的 filesystem cache,你如果给 filesystem cache 更多的内存
- 尽量让内存可以容纳所有的
idx segment file索引数据文件,那么你搜索的时候就基本都是走内存的,性能会非常高。
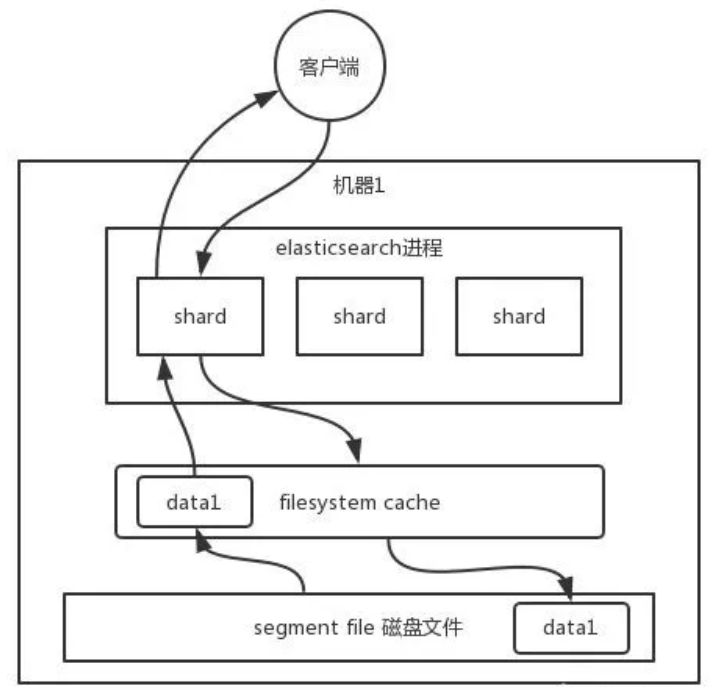
- 性能差距究竟可以有多大?我们之前很多的测试和压测:
- 如果走磁盘一般肯定上秒,搜索性能绝对是秒级别的,1秒、5秒、10秒。
- 但如果是走 filesystem cache,是走纯内存的,那么一般来说性能比走磁盘要高一个数量级,基本上就是毫秒级的,从几毫秒到几百毫秒不等。
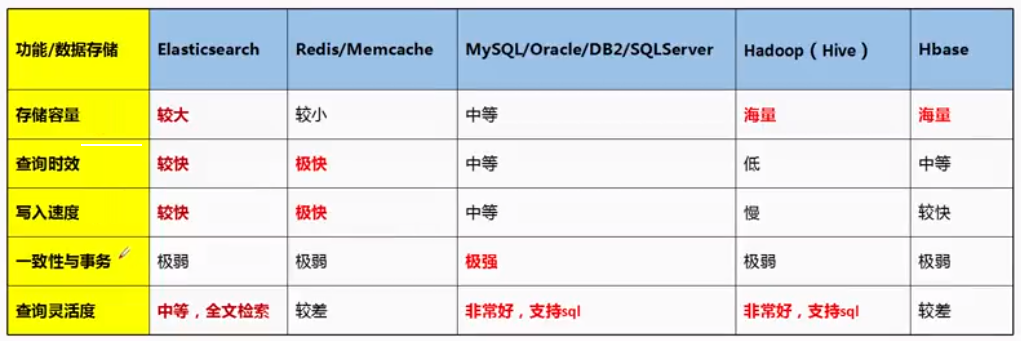
# 2.4 ES优缺点
# 03.ES核心概念
| MySQL | elasticsearch |
|---|---|
| 数据库(Datebase) | 索引(Index) |
| 表(Table) | 类型(Type) |
| 行(Row)每一条 | 文档(Document)每一条 |
| 字段 | 属性 |
| 对象(Schema) | 映射(Mapping) |
| 索引(Index) | 万物皆索引(不管什么数据都默认索引) |
| SQL语言(Select、update) | Query DSL(GET、PUT) |
# 3.1 索引(index)库
- ES将他的数据存储在一个或多个索引中,可以向索引读写文档
- 索引相当于关系型数据库中的一个数据库
# 3.2 类型(type)表
- 类型(type)是用来规定文档的各个字段内容的数据类型和其他的一些约束
- 一个索引(index)可以有多个文档类型(type)
文档类型(type)相当于关系型数据库中的表
# 3.3 文档(document)行
- 在ES中,文档(document)是存储数据库的载体,包含一个或多个字段
- ES中的最小的,整体的数据单位
- 文档(document)相当于关系型数据库中的一行数据
- 一个document里面有多个field,每个field就是一个数据字段
# 3.4 Lucene Index
- 注意和ES Index区别,Lucene Index是由若干段和提交点文件组成
# 3.5 段(Segment)
- Luncene里面的一个数据集概念,因为ES底层是基于Lucene
- 最核心的概念就是Segment,每个段本身就是一个倒排索引
# 3.6 提交点(commit point)
- 有一个列表存放着所有已知的所有段
# 3.7 映射
- 映射是定义ES对索引中字段的存储类型,分词方式和是否存储等信息
- 就像数据库中的Schema,描述了文档可能具有的字段或属性,每个字段的数据类型
- Es对字段类型可以不指定,然后动态对字段类型猜测
- 也可以在创建索引时具体指定字段的类型(关系型数据库才需要手动指定)
# 3.8 Shard 分片
- 单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储
- 有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能
- 每个shard都是一个lucene index
# 3.9 Replica 副本
- 任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本
- replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能
- primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个)
- 默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器
# 3.10 Cluster集群
- 包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的
- 对于中小型应用来说,刚开始一个集群就一个节点很正常
# 3.11 Node节点
- 集群的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候)
- 默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群
- 当然一个节点也可以组成一个elasticsearch集群
# 04.ES使用
# 1、分片的设定
分片数过小,数据写入形成瓶颈,无法水平拓展
分片数过多,每个分片都是一个lucene的索引,分片过多将会占用过多资源
如何计算分片数
分片数量最好设置为节点数的整数倍,保证每一个主机的负载是差不多一样的
否则可能遇到其他主机负载正常,就某个主机负载特别高的情况
一般我们根据每天的数据量来计算分片,保持每个分片的大小在 50G 以下比较合理
如果还不能满足要求,那么可能需要在索引层面通过拆分更多的索引或者通过别名 + 按小时 创建索引
# 2、ES数据近实时问题
ES数据写入之后,要经过一个refresh操作之后,才能够创建索引,进行查询
但是get查询很特殊,数据实时可查
- get查询的实时性,通过每次get查询的时候
- 如果发现该id还在内存中没有创建索引,那么首先会触发refresh操作,来让id可查
ES5.0之前translog可以提供实时的CRUD
get查询会首先检查translog中有没有最新的修改,然后再尝试去segment中对id进行查找
5.0之后,为了减少translog设计的复杂性以便于再其他更重要的方面对translog进行优化
所以取消了translog的实时查询功能