 06.LangGraph
06.LangGraph
# 01.LangGraph
# 1、概述
一、LangGraph 是什么?
- LangGraph 是一个构建多阶段、有状态、多智能体(Multi-Agent)工作流的框架
- 它并非独立于 LangChain 存在,而是作为 **LangChain 的高级扩展库
- 通过引入状态图的概念,解决了传统 AgentExecutor 模式下「黑盒不可控」的问题
二、LangGraph 的核心理念
组件/概念 作用 StateGraph主图结构,表示整个应用的执行流程图 Node(节点)流程中的某个步骤(如调用 LLM、Tool、Chain、判断条件等) Edge(边)控制流程走向的条件路径,可以显式定义“下一个节点” state(状态)每轮执行共享的上下文数据,可自定义字段,如用户输入、中间结果等 compile()编译整个 StateGraph 为可执行的 LangChain 应用(通常为 AsyncRunnable) run()/astream()启动图执行,进行单次或流式任务处理
三、LangGraph 能做什么
应用类型 示例说明 RAG 流程 文档加载 → 向量检索 → 生成回复 → 检查是否满意 → 循环优化 多智能体协作 多个专家 Agent 处理不同子任务(如 GPT-Newspaper 编写新闻) 多轮对话 实现嵌套判断逻辑的对话流程,支持上下文切换与回退 自定义工作流 自定义任意节点调用逻辑,如代码生成流程、Chain-of-Thought 推理路径等
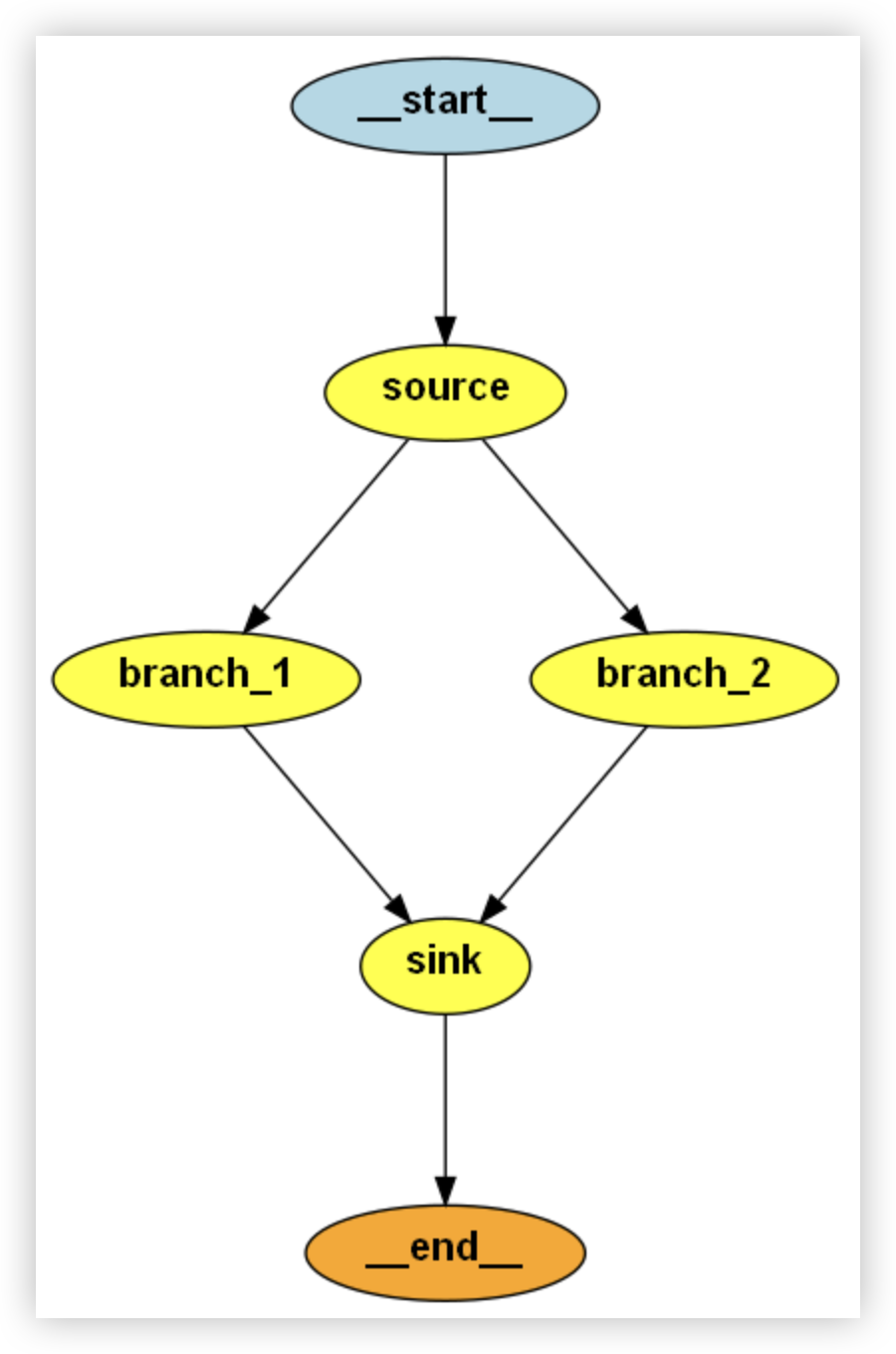
# 2、多分支并行处理
- 本案例展示了 LangGraph 在构建多分支并行处理流程上的能力
- 利用 MessageGraph 构建有多个分支(如“正方观点”和“反方观点”)的处理流。
- 每个分支可以独立地接受相同输入,进行不同逻辑处理(如通过不同 Prompt 模板和 LLM 推理)
- 最后所有分支的结果统一流入汇总节点,进行信息整合和判断(比如选择哪个更有说服力)
# 1)llm_model.py
import os
from langchain.chains import LLMChain, RetrievalQA
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv() # 加载 API Key
llm = ChatOpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL"),
model="deepseek-chat"
)
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 2)logic.py
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from llm_model import llm # 指定使用的语言模型对象
from langchain_core.messages import HumanMessage
# 正方 Prompt 模板
fan_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""现在你放弃一切想法,假装成为一个任何主题的狂热粉丝和追随者,应该尽一切能力吹捧主题的观点"""
),
MessagesPlaceholder(variable_name="messages"), # 用于动态填充传入的上下文
]
)
proponent = fan_prompt | llm # 管道组合 prompt 和模型调用
# 反方 Prompt 模板
detractor_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"现在你假装成为任何话题的批评者和坚定的反对者,应该尽一切能力提供有力的证据来批判和反驳主题的观点",
),
MessagesPlaceholder(variable_name="messages"),
]
)
opponent = detractor_prompt | llm
# 汇总 Prompt 模板:要求判断哪方观点更有力
synthesis_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"哪个论证更有力? 选择一边。",
),
MessagesPlaceholder(variable_name="messages"),
]
)
"""
sink 节点收到的 messages 是来自 直接相邻的上游节点
"""
# 合并正反方输出信息,形成新的输入给 synthesis_prompt
def merge_messages(messages: list):
print("merge_messages", messages)
original = messages[0].content # 第一个为原始主题
arguments = "\n".join(
[f"Argument {i}: {msg.content}" for i, msg in enumerate(messages[1:])] # 正反观点
)
return {
"messages": [
HumanMessage(
content=f"""Topic: {original}
Arguments: {arguments}\n\n哪一个论点更有说服力?"""
)
]
}
# 组合 merge → prompt → llm 的最终汇总链
final = merge_messages | synthesis_prompt | llm
# 可独立测试两个 Agent 的表现(非必须)
if __name__ == "__main__":
res1 = proponent.invoke([HumanMessage(content="躺平是当代人的解药")])
res2 = opponent.invoke([HumanMessage(content="躺平是当代人的解药")])
print(res1)
print(res2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# 3)graph.py
from langchain_core.messages import HumanMessage
from logic import final, proponent, opponent # 从另一个文件导入了正方、反方、和最终汇总逻辑
from langgraph.graph import MessageGraph
# 将 message 列表包装为字典结构,便于 prompt 接收
def dictify(messages: list):
print("dictify", messages)
return {"messages": messages}
# 定义多分支处理图
def new_builder():
builder = MessageGraph()
# I. 添加节点
# 添加节点:输入节点(source),返回空列表,表示最初输入处理
builder.add_node("source", lambda x: [])
# 添加两个分支节点,正方和反方(通过 dictify 包装消息后再送入对应 Agent)
builder.add_node("branch_1", dictify | proponent)
builder.add_node("branch_2", dictify | opponent)
# 添加汇总节点,比较正反观点,判断谁更有说服力
builder.add_node("sink", final)
# II. 设置边连接关系
# 设置入口节点为 source
builder.set_entry_point("source")
# source -> 分别 fan out 给正方和反方节点
builder.add_edge("source", "branch_1")
builder.add_edge("source", "branch_2")
# 分别 fan in 回 sink 汇总节点
builder.add_edge("branch_1", "sink")
builder.add_edge("branch_2", "sink")
# 设置最终结束节点
builder.set_finish_point("sink")
# III. 编译为可执行的 graph 对象
graph = builder.compile()
return graph
if __name__ == "__main__":
graph = new_builder()
# 执行图,传入初始人类消息
for step in graph.stream([HumanMessage(content="躺平是当代人的解药")]):
print(step)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 4)打印图
from graph import new_builder
import networkx as nx
import matplotlib.pyplot as plt
if __name__ == "__main__":
graph = new_builder()
langgraph_obj = graph.get_graph() # 获取 langgraph 的图对象
# 创建一个空的 networkx 图
nx_graph = nx.DiGraph()
# 手动添加节点(假设 langgraph_obj 有 nodes 属性)
for node in langgraph_obj.nodes: # 如果 nodes 是属性或方法
nx_graph.add_node(node)
# 手动添加边(假设 langgraph_obj 有 edges 属性)
for edge in langgraph_obj.edges: # 如果 edges 是属性或方法
nx_graph.add_edge(edge[0], edge[1])
# 绘制图形
nx.draw(nx_graph, with_labels=True, node_color="skyblue", node_size=1000, arrowsize=20)
plt.savefig("graph.png") # 保存为图片
plt.show() # 直接显示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
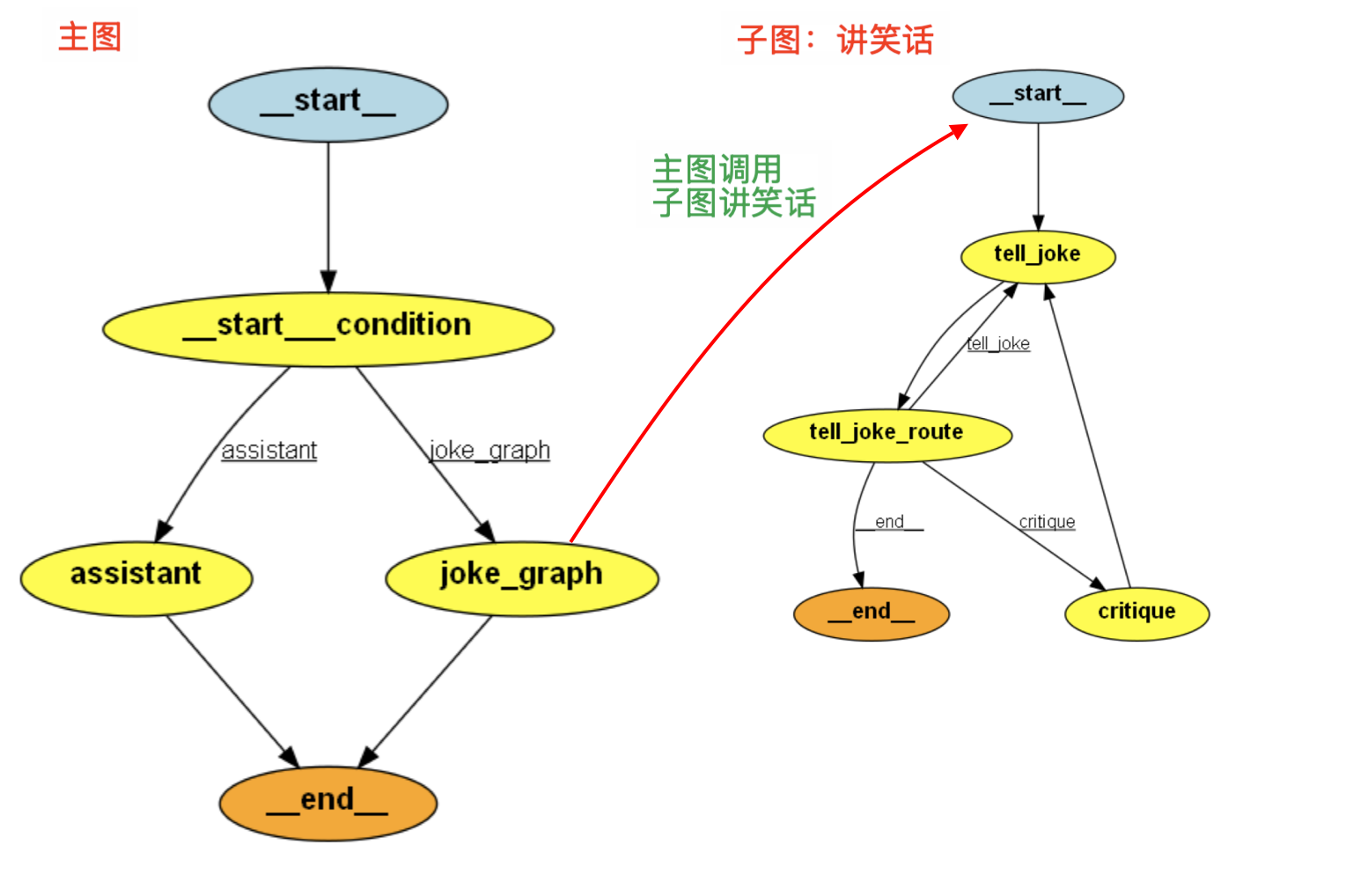
# 3、多图协作
LangGraph 构建了一个有条件分支的对话系统,其中包含一个主图(
main_builder)和一个笑话子图(joke_graph)用户输入问题查询:“躺平是当代人的解药”
主图(
main_builder)基于 llm 模型判断当前问题是,2. 讲笑话根据路由 router 会调用,子图(
joke_graph)来进行讲笑话主图不会在调用子图后立即结束,会等待子图执行完毕
子图的返回结果会作为当前节点的输出,传回主图
set_finish_point("joke_graph")指明,当流程走到joke_graph完成时,就认为整个图流程结束了
# 0)调用顺序
用户输入
"请给我讲个减肥笑话"→ 执行
route()意图识别为2→ 路由至
joke_graph节点→ 执行:
get_user_message提取用户输入joke_graph.invoke(...)子图执行(如包含模型调用)get_joke(...)提取最终笑话,包装为主图状态格式- → 返回
{"conversation": [final_joke]} - → 结束于
"joke_graph"节点
- → 返回
# 1)llm_model.py
import os
from langchain.chains import LLMChain, RetrievalQA
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv() # 加载 API Key
llm = ChatOpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL"),
model="deepseek-chat"
)
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 2)joke_agent.py 子图讲笑话
import operator
from typing import Annotated, List, TypedDict
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langgraph.graph import END, StateGraph
from langchain_core.messages import SystemMessage,HumanMessage,AIMessage
from sales_gpt import llm
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你就是那个爱开玩笑的人。 用一个笑话来回应,这是有史以来最好的笑话。",
),
MessagesPlaceholder(variable_name="messages"),
],
)
critic_prompt = ChatPromptTemplate.from_messages(
[
("system", """{message}
-------
请提出对这个笑话的改进建议,使其成为有史以来最好的笑话。"""),
],
)
def update(out):
print(out)
return {"messages": [("assistant",out.content)]}
def replace_role(out):
print("replace_role--------")
print(out)
print("replace_role_end--------")
return {"messages": [HumanMessage(out.content)]}
def critiqueFn(state):
print("state---------------------")
print(state)
message = state["messages"][-1]
print(message)
print("state end---------------------")
return {"message":message[1]}
class SubGraphState(TypedDict):
messages: Annotated[List, operator.add]
builder = StateGraph(SubGraphState)
builder.add_node("tell_joke", prompt | llm | update)
builder.add_node("critique", critiqueFn |critic_prompt | llm | replace_role)
def route(state):
print(state)
return END if len(state["messages"]) >= 3 else "critique"
builder.add_conditional_edges("tell_joke", route)
builder.add_edge("critique", "tell_joke")
builder.set_entry_point("tell_joke")
joke_graph = builder.compile()
if __name__ == "__main__":
for step in joke_graph.stream({"messages": [("user", "讲一个关于减肥的笑话")]}):
print(step)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# 3)main_agent.py 主图调用子图
import operator
from typing import TypedDict, Annotated, List
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda
from langgraph.graph import StateGraph
from joke_agent import SubGraphState, joke_graph
from sales_gpt import llm
output_parser = StrOutputParser() # 输出解析器实例,用于处理模型的输出
# 定义助手状态类型,包含一个名为 conversation 的字段,存储对话历史
class AssistantState(TypedDict):
conversation: Annotated[List, operator.add]
# 创建一个聊天提示模板,用于引导模型的对话
assistant_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个意图识别助手"), # 系统消息,设置助手角色
("human", "{input}") # 用户输入的消息,待替换为实际输入
])
# 定义一个将消息添加到对话历史的函数
def add_to_conversation(message):
print(message) # 打印消息以进行调试
return {"conversation": [message]} # 返回包含消息的对话状态
# 定义一个获取用户最后一条消息的函数
def get_user_message(state: AssistantState):
print(state["conversation"]) # 打印对话历史以进行调试
last_message = state["conversation"][-1] # 获取最后一条消息
return {"messages": [last_message]} # 返回包含最后消息的字典
# 定义一个处理笑话生成的函数
def get_joke(state: SubGraphState):
print(state) # 打印子图状态以进行调试
final_joke = state["messages"][-1] # 获取笑话生成的最终结果
return {"conversation": [final_joke]} # 返回生成的笑话,添加到对话历史
# 定义一个路由函数,根据意图识别的结果决定走哪个分支
def route(state: AssistantState):
print(state) # 打印状态信息以进行调试
message = state["conversation"][-1][-1] # 获取最新的用户输入消息
# 创建一个用于识别意图的聊天提示模板
intent_prompt = ChatPromptTemplate.from_messages([
("system", """你是一个意图识别的助手,能够识别以下意图:
1. 讲故事
2. 讲笑话
3. AI绘画
4. 学习知识
5. 其他
例如:
用户输入:给我说个故事把。
1
用户输入:给我画个美女图片。
3
------
用户输入:{input}
请识别用户意图,返回上面意图的数字序号,只返回数字,不返回任何其他字符。
""")
])
# 创建一个意图识别链,首先使用提示模板生成意图,再通过语言模型进行处理
intent_chain = intent_prompt | llm | output_parser
# 执行意图识别,获取结果并去除多余的空白字符
result = intent_chain.invoke({"input": message}).strip()
print("意图识别:", result)
# 根据识别的意图返回不同的分支
if result == "2": # 如果识别为“讲笑话”
return "joke_graph" # 转到笑话生成子图
else:
return "assistant" # 否则继续进行助手流程
def new_many_builder():
# 创建一个状态图构建器,初始化时指定助手状态类型
main_builder = StateGraph(AssistantState)
# 向状态图中添加一个“assistant”节点,处理输入并返回模型输出
# 等价于 c(b(a(x))) 把第一个函数的输出作为 | 符号后面函数的输入
main_builder.add_node(
"assistant", assistant_prompt | llm | add_to_conversation
)
# 向状态图中添加一个“joke_graph”节点,用于生成笑话
main_builder.add_node("joke_graph", get_user_message | joke_graph | get_joke)
# 设置状态图的条件入口点,根据路由函数判断流程
main_builder.set_conditional_entry_point(route)
# 设置状态图的结束点,定义结束流程的节点
main_builder.set_finish_point("assistant")
main_builder.set_finish_point("joke_graph")
# 编译状态图
graph = main_builder.compile()
return graph
if __name__ == "__main__":
# 启动图流并传入初始状态(一个用户请求讲笑话的对话)
graph = new_many_builder()
for step in graph.stream({"conversation": [("user", "请给我讲个减肥笑话")]}):
print(step) # 打印每一步的执行结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111