 02.MongoDB架构原理 ✅常识原理
02.MongoDB架构原理 ✅常识原理
文档型数据库:使用BSON格式存储数据,灵活的Schema允许嵌套数据结构。
架构模式:复制集确保高可用性,主节点处理写操作,从节点复制数据并可读。分片集群用于分散存储大规模数据,每个分片可以是复制集。
存储引擎:WiredTiger支持数据压缩、文档级锁,提升性能和并发处理。
持久化机制:通过journal日志和write concern参数提高数据安全性。
数据模型:支持模式自由设计,使用嵌入或引用文档实现关联关系。
# 01.MongoDB架构模式
# 1、基本概念
# 1)文档型非关系型数据库
- MongoDB属于文档型的非关系型数据库(NoSQL)
- MongoDB使用BSON(Binary JSON)格式存储数据
- 允许存储复杂的嵌套数据结构,而无需预先定义严格的模式(Schema)
# 2)数据库与集合
- 数据库(Database):
- 在MongoDB中,数据库的概念与关系型数据库中的数据库一致,用于存储多个集合
- 集合(Collection):
- 相当于关系型数据库中的“表”
- 集合是MongoDB中存储文档的容器,不需要预先定义结构,允许存储不同结构的文档
- 文档(Document):
- 类似于关系型数据库中的“行”
- 文档是MongoDB中最小的数据单元,以BSON格式存储,支持嵌套和复杂的数据类型
# 3)BSON格式
- BSON是一种二进制序列化JSON文档的格式,MongoDB使用BSON来存储和传输数据
- 相比于JSON,BSON支持更多的数据类型,并且在编码和解码方面更加高效
# 4)无固定行列组织结构
- MongoDB的集合不要求固定的行列结构,允许每个文档拥有不同的字段和结构
- 这种灵活性使得MongoDB在处理多变的数据模型时具有优势
# 5)集合不支持关联查询
MongoDB不直接支持关系型数据库中的联表查询,但可以通过以下两种方式实现数据的关联
嵌入文档(Embedded Documents):
- 将相关数据嵌入到一个文档中,适用于“一对一”或“一对多”关系且关系较为稳定的数据
引用文档(Referenced Documents):
- 通过引用另一个集合中的文档来实现数据关联,适用于数据关系复杂或需要保持数据独立性的场景
- 引用可以是手动引用,也可以使用DBRef标准
# 2、架构模式
- MongoDB支持两种主要的集群架构:复制集和分片集群
# 1)复制集(Replica Set)
复制集是 MongoDB 高可用性 (HA) 的关键架构,它由多个节点组成
Primary:主节点,处理所有写操作
Secondary:从节点,负责复制主节点的数据,部分配置下可以处理读请求
Arbiter:投票节点,不存储数据,只参与选举
- Primary和Secondary角色:
- 复制集中的一个节点被选举为Primary,负责处理所有的写操作和读取操作(除非配置指定只允许Primary处理写操作)
- 其他节点作为Secondary,负责复制Primary的数据并可以处理读取请求
- 数据复制:
- Secondary节点通过持续复制Primary节点的操作日志(oplog),确保与Primary的数据保持一致
- 故障转移(Failover):
- 当Primary节点发生故障时,复制集会自动进行多数派选举,选出新的Primary,确保系统的持续可用性
- 垂直扩展的最小部署单位:
- 复制集不仅提供数据的高可用性,还为MongoDB的垂直扩展提供了基础
- 每个Sharding Cluster中的Shard也可以使用复制集架构来提高数据的可用性
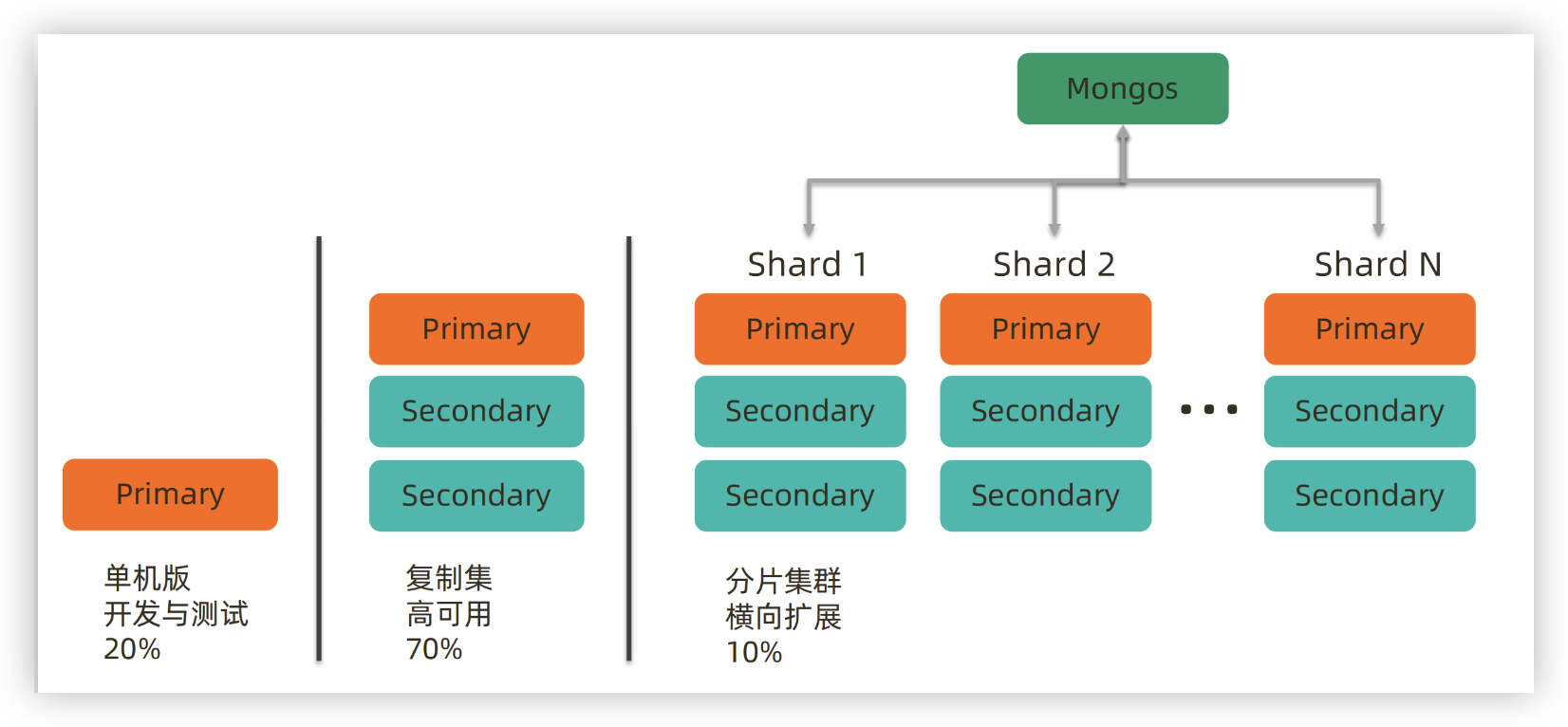
# 2)分片集群(Sharding Cluster)
当数据量超出单节点存储能力时,分片 (Sharding) 机制用于将数据水平切分到多个节点
Shard:数据分片,每个分片存储一部分数据每个Shard通常是一个复制集,提供高可用性
Mongos:路由器,客户端通过它与各分片进行交互
Config Server:存储集群配置信息
- 数据分片(Sharding):
- 将集合中的数据根据指定的分片键分布到多个Shard节点上,每个Shard节点负责存储集合的一部分数据
- 这样可以有效分散数据存储和查询压力,支持更大的数据容量
- eg:
- 把数据分成两半,放到2个库物理里
- 把交易号 0 ~ 500000000 的交易数据放到第一台 mongodb 机器中中
- 500000000 ~ 1000000000 的交易号数据放到第二台 mongodb 实例中
- 分布式架构:
- 分片集群通常由多个Shard组成,每个Shard可以是一个复制集,从而同时具备水平扩展和高可用性的能力
- 支持TB级别的数据:
- 通过分片,MongoDB可以轻松支撑数TB甚至更大规模的数据存储需求
# 3、存储引擎
# 1)MMAPv1
- MMAPV1是MongoDB的原始存储引擎,自最初版本起引入,但从4.0版本开始被弃用
- 数据压缩:
- MMAPV1基于内存映射文件,不支持数据压缩
- 如果所有数据能够完全加载到内存中,MMAPV1可以表现出高效的性能
- 日志(Journal):
- MMAPV1通过日志机制确保写操作的原子性
- 写操作首先记录到journal日志文件,然后应用到数据文件
- 如果在写操作过程中发生崩溃,MongoDB可以通过journal日志在重启时重新应用未完成的写操作,确保数据一致性
- 锁机制:
- 从3.0版本开始,MMAPV1引擎采用集合级别锁(Collection-Level Locking)
- 相比早期的数据库级别锁(Database-Level Locking),提高了并发性和性能
- 内存管理:
- MMAPV1依赖操作系统的虚拟内存管理,使用所有可用的空闲内存作为缓存
- 当系统需要更多内存时,MongoDB会自动释放部分缓存
# 2)WiredTiger
- WiredTiger是MongoDB自3.0版本引入的插件式存储引擎,并从3.2版本开始成为默认的存储引擎
- 数据压缩:
- WiredTiger支持Snappy和Zlib两种压缩模式,显著减少磁盘空间的占用
- 同时,WiredTiger有自己的写缓存(可配置),并利用文件系统缓存提高性能
- 日志(Journal):
- WiredTiger的Journal日志记录两个检查点之间的所有数据修改操作
- 在发生崩溃时,只需重放最近的journal日志即可恢复数据
- 默认情况下,WiredTiger每分钟进行一次检查点操作
- 锁和并发控制:
- WiredTiger支持文档级别锁,并采用乐观并发控制,显著提升并发性能
- 它仅在全局、数据库和集合级别使用意向锁(Intent Locks)
- 内存使用:
- WiredTiger同时利用内部缓存和操作系统缓存资源
- 它会自动使用WiredTiger缓存之外的所有空闲内存,以提高数据访问速度
# 4、持久化原理
# 1) 持久化线程
- MongoDB在启动时,会初始化一个专门的持久化线程,
- 该线程不断循环,从延迟队列(defer队列)中获取需要持久化的数据,
- 并将其写入到磁盘的journal日志和数据文件(mongofile)中
- 持久化操作是延时批量提交(Group Commit),以减少磁盘I/O的开销,提高整体性能
# 2)数据安全性保障
- Journal日志:
- 所有变更操作首先写入journal日志,并在后台定期(默认每60秒)将内存中的变更数据flush到底层的数据文件中
- 这种机制确保即使在系统崩溃时,也可以通过journal日志恢复数据到最后一次flush的状态
- 记录重新分配:
- 当一个文档的尺寸变大,超出原有分配的空间时,MongoDB会重新分配新的存储空间,将文档移动到文件尾部,并更新索引指向新的offset
- 这种操作会导致更多的时间和存储开销,同时也会产生磁盘碎片
- Power of 2 Sized Allocations:
- 自MongoDB 3.0起,默认采用“Power of 2 Sized Allocations”策略,即按照2的幂次方(如32、64、128、256...2MB)为文档分配存储空间
- 此策略有助于减少磁盘碎片,并允许文档在一定范围内增长而无需频繁重新分配空间
- No Padding Allocation:
- 可选的“No Padding Allocation”策略,根据实际数据尺寸分配存储空间,
- 适用于大部分是插入和就地更新、较少删除的场景,可以提高磁盘空间利用率
# 3)持久化机制配置
- commitIntervalMs:
- 配置项决定了flush到磁盘的时间间隔,默认值为100毫秒
- 减小该值可以减少数据丢失的风险,但会增加磁盘I/O负载
- Write Concern:
- 通过设置write concern的“j”参数为true,可以确保写操作在写入journal日志后返回,从而提高数据安全性
- Replica Set架构:
- 采用复制集架构,通过多节点的数据备份和多数派选举机制,进一步保障数据的持久性和可用性
# 5、数据文件存储原理
# 1)数据文件(Data Files)
- MongoDB的数据文件按数据库进行组织,每个数据库对应一组数据文件
- 数据文件的命名格式为“数据库名 + 序列号”,序列号从0开始递增
- mongodb的数据将会保存在底层文件系统中,比如我们dbpath设定为“/data/db”目录
- 我们创建一个database为“test”,collection为“sample”,然后在此collection中插入数条documents
- 我们查看dbpath下生成的文件列表

可以看到test这个数据库目前已经有6个数据文件(data files)
每个文件以“database”的名字 + 序列数字组成,序列号从0开始,逐个递增
数据文件从16M开始,每次扩张一倍(16M、32M、64M、128M…)
在默认情况下单个data file的最大尺寸为2G,如果设置了smallFiles属性(配置文件中)则最大限定为512M
mongodb中每个database最多支持16000个数据文件,即约32T
如果设置了smallFiles则单个database的最大数据量为8T
# 2)Namespace文件
- Namespace文件(如“test.ns”)用于存储集合和索引的命名信息,默认大小为16MB
- 它保存集合的属性信息、每个索引的属性类型等
- 对于需要存储大量集合的数据库,可以通过配置文件中的
nsSize选项来调整Namespace文件的大小
# 3)Journal日志
- Journal日志用于提供数据保障,确保在系统崩溃后能够恢复数据
写操作流程:写操作首先写入journal日志,然后在后台定期将变更的数据flush到数据文件中
性能优化:
- 为了提升性能,write操作会先写入内存中的journal buffer,
- 达到一定大小(如100MB)或时间间隔(如100毫秒)后,再flush到磁盘
数据恢复:
- 在系统崩溃后,MongoDB通过重放journal日志来恢复数据到最后一次成功的写操作,确保数据的一致性
数据安全策略:
减小commitIntervalMs:减少数据丢失的风险,但会增加磁盘I/O负载
Write Concern设置:通过设置write concern的“j”参数为true,确保写操作在写入journal日志后返回
Replica Set架构:通过多节点的数据备份,进一步提高数据的持久性和可用性
# 6、数据模型
- MongoDB的灵活数据模型是其一大优势,允许在同一集合中存储结构不同的文档
- 但在实际应用中,设计合理的数据模型仍然至关重要
# 1)模式自由(Schema-Free)
- MongoDB不要求预先定义模式,允许在同一集合中存储结构各异的文档
- 这种灵活性使得MongoDB适用于快速迭代和多变的数据需求
- 但为了优化查询性能和数据管理,建议在同一集合中保持文档结构的相似性
# 2)内嵌文档与引用文档
内嵌文档(Embedded Documents):
将相关数据嵌入到一个文档中,适用于“一对一”或“一对多”关系,且关系较为稳定的数据
优点:
查询时无需进行联表操作,性能更高
写操作具备原子性,确保数据一致性
缺点:
- 当内嵌文档数量不确定或可能增长时,会导致文档尺寸不断增加
- 可能触发存储空间重新分配,影响性能
引用文档(Referenced Documents):
将相关数据存储在不同的集合中,通过引用进行关联
适用于数据关系复杂或需要保持数据独立性的场景
优点:
数据结构更加灵活,避免文档尺寸过大
适用于“一对多”关系且相关数据量不确定的情况
缺点:
查询时需要进行多次查询或联表操作,性能较低
写操作无法保证多个集合的事务性一致性
# 3)索引(Indexing)
- 索引在MongoDB中用于提高查询性能,但也会带来额外的内存和磁盘开销
- 默认索引:每个集合默认有一个唯一索引
_id,确保每个文档的唯一性 - 自定义索引:
- 根据查询需求创建额外的索引,优化查询性能
- 需注意索引数量不宜过多,以免影响写操作性能和增加存储开销
- 索引类型:
- 单字段索引(Single Field Index)
- 复合索引(Compound Index)
- 多键索引(Multikey Index)
- 地理空间索引(Geospatial Index)
- 文本索引(Text Index)
- 索引维护:
- 每次插入、更新或删除操作都会影响相关索引,需合理规划索引设计,平衡读写性能
# 4)数据生命周期管理(TTL)
- MongoDB提供TTL(Time-To-Live)机制,用于自动删除过期的文档
- 适用于需要管理数据生命周期的场景,如验证码、消息记录等
- 创建TTL索引:在文档的日期字段上创建TTL索引,并指定过期时间
- 过期策略:
- 指定文档保存的时长,过期后自动删除
- 指定在某个特定时间点过期,通过将日期字段设置为目标时间,过期时间设置为0
- 后台线程:MongoDB会启动后台线程,定期扫描并删除过期的文档,确保数据及时清理