 06.Mage平台
06.Mage平台
# 01.Mage智能自动化平台
# 0、MLOps
- MLOps 是让
“数据+模型+资源+用户”这四大闭环自动、有序、可视、可控地闭合并循环优化的系统能力- 其目标是实现
模型快速上线、高效迭代、稳定服务、持续优化。
1. 用户提交任务 (用户闭环)
↓
2. 平台调度资源,创建训练作业 (资源闭环)
↓
3. 训练过程调用数据仓库 + 标注样本 (数据闭环)
↓
4. 模型训练、评估、发布 (模型闭环)
↓
5. 上线推理服务,用户使用 & 反馈 (模型闭环 + 用户闭环)
↓
6. 错误数据 & 异常样本回流 (数据闭环)
↓
7. 平台自动触发再训练任务 (全闭环循环)
2
3
4
5
6
7
8
9
10
11
12
13
# 1、AI能力介绍
# 1)基本能力介绍
- 自训练抽取:
- 1)新建字段、2)上传数据、3)标注数据
- 4)构建数据集、5)新建版本、6)评测、7)发布版本
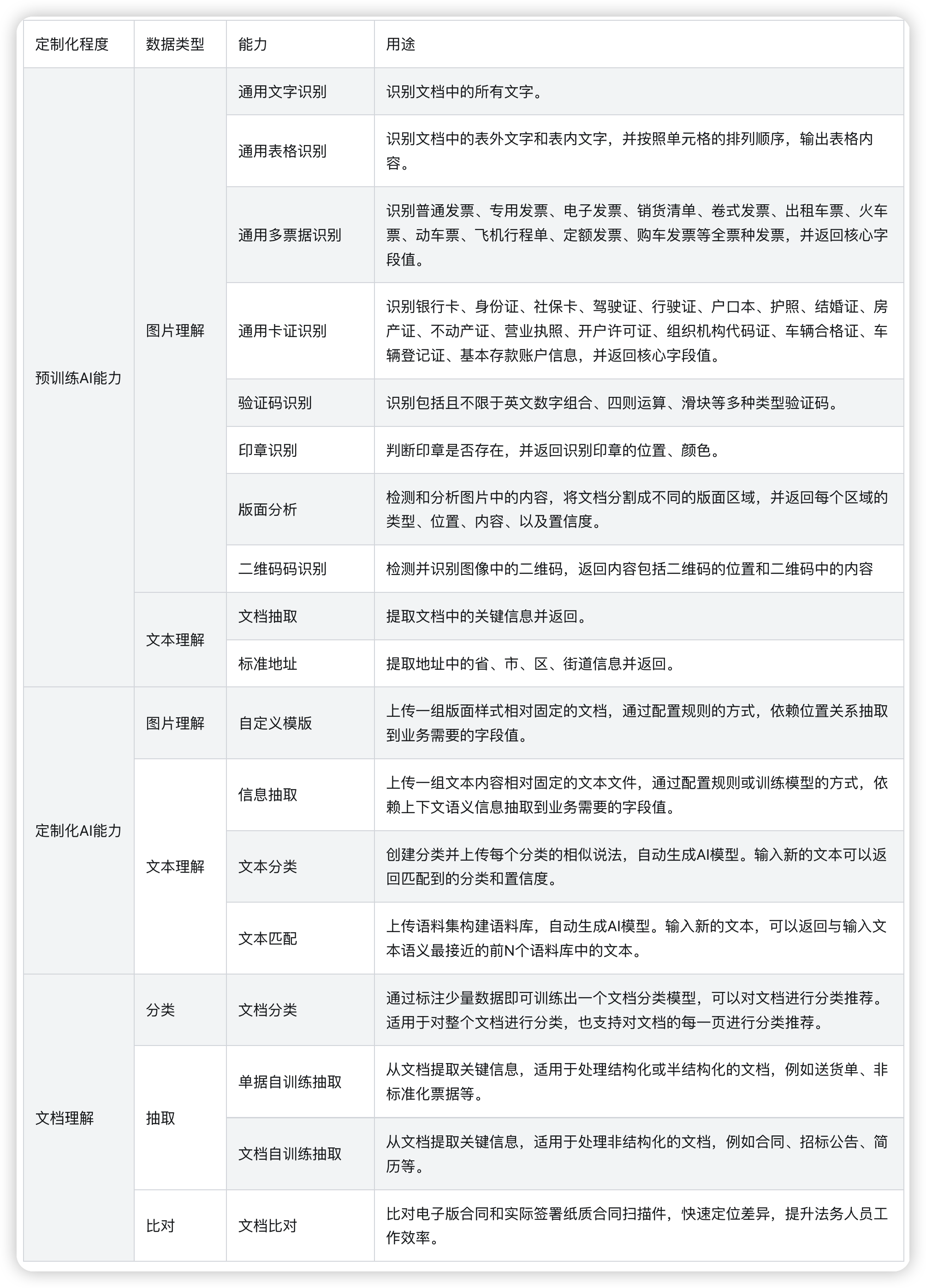
1、从定制化程度看,AI能力可以分为通用AI能力和定制化AI能力两类。
- 预训练AI能力提供了开箱即用的AI模型,能够处理通用文档、表格等非结构化数据,以及身份证、营业执照、增值税发票、火车票识别等结构化数据。
- 定制化AI能力,需要上传自己的数据,通过标注、训练、测评、优化AI模型,使模型能够理解专业领域的文档。
2、从处理的数据类型上看,AI能力可以分为图片理解、文本理解。
3、此外,平台有综合性的AI能力,提供文档的端到端解决方案,利用平台上已有的OCR、NLP原子能力以及深度学习模型,能够协助机器人理解文档,提取文档中的关键信息。
# 2、业务架构

# 2、业务场景
# 1)图片理解类
一、通用票据识别
目标能力: 从各种发票图像中提取如“发票代码、金额、日期”等关键字段。
标注方式:
使用图像标注工具(如LabelImg或自研平台)
对图片中的每个字段进行 框选+字段标注(例如:框出“发票代码”,并在工具中打标签为“InvoiceCode”)
可以通过OCR预识别结果进行辅助标注,人工校验与修正
真实业务例子
财务自动化平台每天需要识别数千张电子发票,将其中的发票号码、金额、开票日期等信息提取后自动入账- 人工标注团队先从各类发票图像中手动标注这些字段,用于训练和评估票据识别模型
二、自定义模板(定制化票据、合同)
目标能力: 固定模板类文档中提取特定字段
标注方式:
以模板为单位配置版面结构:
如某个字段总是在“距离标题下方20px”的位置对多个样例文档进行
位置依赖规则标注可选择框选
字段位置+字段语义名(如“客户名称”、“有效期”)
真实业务例子:
- 某政府机关使用“房产证OCR识别”系统提取“房产坐落”、“权利人”、“建筑面积”等字段
- 由于样本版面固定,采用模板方式快速标注50张样本文档,即可训练出满足需求的模型
三、印章识别
目标能力: 判断图像中是否存在印章,输出位置+颜色
标注方式:
使用图像标注工具,对印章进行框选(矩形框)
同时标注颜色类别(红章、蓝章等)
标注“是否印章存在”字段
真实业务例子:
- 某合同审查平台需判断合同是否加盖有效印章
- 标注人员使用图像工具框选印章区域并标注颜色,配合模型训练实现高置信度的印章识别
# 2)文本理解
一、文本分类(如意图分类、合同类型分类)
目标能力: 将文本归入某个预定义类别
标注方式:
对文本数据进行分类标注(使用文本标注平台如doccano、Label Studio等)
例如:
{"text": "本合同自2025年起生效", "label": "租赁合同"}常见分类:
合同类型、投诉类型、邮件主题意图等
真实业务例子:
- 某企业法务平台对
历史合同文档进行分类(如采购合同、劳动合同、租赁合同) - 标注人员阅读每篇合同,选择所属类别并进行标记
- 某企业法务平台对
二、抽取 - 单摘自训练抽取(适用于结构化文档)
目标能力: 从文档中提取关键信息,如“甲方、乙方、合同金额、有效期”
标注方式:
使用结构化信息标注工具
将文本中的关键字段以**“字段名 - 字段值”**的方式标注出来
如:文本中出现“甲方为北京xx公司”,标注为:
"PartyA": "北京xx公司"
真实业务例子:
- 某金融平台处理数千份贷款合同,需要提取“借款人姓名、身份证号、贷款金额、利率”
- 人工标注团队在合同PDF文本中标注这些字段,训练信息抽取模型替代人工提取
三、比对 - 文档比对
目标能力:
比较两份文档差异,如Word电子版和PDF扫描件是否一致标注方式:
标注差异点(位置、字段值差异)
支持“对齐段落”、“不一致字段”的定位标注
工具支持双文档比对模式:左侧原始电子文本,右侧扫描图或OCR结果
真实业务例子:
- 某保
险公司对合同归档文档进行一致性校验 - 标注团队会标记扫描图与原始文档中存在出入的位置,用于后续训练差异检测模型
- 某保
# 02.平台能力
# 0、数据存储
| 层级 | 技术选型 | 说明 |
|---|---|---|
| 大文件存储 | MinIO / S3 | 存储图像、PDF、标注图 |
| 结构化JSON存储 | MongoDB | 高效索引与分析 |
| 全文检索与字段比对 | Elasticsearch | 文本比对、字段模糊查找 |
| 元数据管理 | MySQL / TiDB | 标注任务流转、标注人、记录追踪 |
| 错误样本回流 | Kafka | 自动构建重标注任务 |
一、图像 / 文档存储(对象存储)
使用统一路径规范管理文档、图像、标注图等
s3://mage-data/2025/合同/任务ID/原始.pdf s3://mage-data/2025/合同/任务ID/标注图1.png1
2利用元数据标签(如图像类型、创建时间、任务ID)增强索引能力
二、JSON 标注数据(MongoDB)
每份数据存储格式建议如下
{ "task_id": "task_123", "doc_type": "发票", "image_path": "s3://.../invoice001.jpg", "fields": [ { "label": "发票代码", "bbox": [x1, y1, x2, y2], "value": "0123456789", "source": "manual" } ], "model_predict": {...}, "gt_compare_result": { "iou": 0.83, "value_match": true }, "features": { "resolution": "1024x768", "illumination_score": 0.68, "tilt_angle": 16, "stamp_color": "red" }, "is_error_case": true, "error_tags": ["歪斜", "红底", "光照弱"] }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26查询举例:
查询“红底 + 歪斜 > 15度”的错误样本
SELECT * FROM samples WHERE is_error_case = 1 AND features.tilt_angle > 15 AND features.stamp_color = 'red'1
2
3查找“发票代码字段缺失”的样本:
SELECT * FROM samples WHERE NOT EXISTS ( SELECT * FROM UNNEST(fields) WHERE label = '发票代码' )1
2
3
三、全文检索 + 相似字段查询(Elasticsearch)
存储结构{ "task_id": "task_123", "doc_text": "甲方:北京某公司;乙方:深圳某公司;金额:50万元...", "doc_type": "合同", "field_values": { "甲方": "北京某公司", "乙方": "深圳某公司", "金额": "50万元" }, "sim_score": 0.86, "diff_locations": [ {"section": "第3条", "type": "金额", "diff": "50万 vs 60万"} ] }1
2
3
4
5
6
7
8
9
10
11
12
13
14
应用场景:
查询所有金额字段为“50万元”的合同文本
比对两份合同的差异点
文本比对时使用 SimCSE/Embedding 预先计算相似度后索引
四、错误样本聚类与回流支持
使用 ClickHouse 承载聚类统计
错误样本 → 特征维度(分辨率、倾斜角度、图像亮度)向量化
可结合 Faiss + ClickHouse 做样本近似检索
构建回流标注队列
以“错误标签+特征组合”为查询条件
自动构造任务并推送给标注系统(可放入 Kafka)
# 1、数据闭环
- 标注 → 训练 → 推理 → 评测 → 挑选错误样本 → 回流标注
# 1)标注
文档图像:发票、合同、身份证等结构化图像文本内容:长文本、合同条款、语义理解任务图片理解类标注- 使用图像标注工具对图片中的目标区域进行
框选并打标签 - 例如在票据识别中
- 框出“发票代码”“金额”等字段;
- 在印章识别中,框选印章位置并标注颜色;
- 在固定模板文档中,通过设置位置规则和字段标签实现快速标注
- 预识别+人工修正的方式提升效率
- 使用图像标注工具对图片中的目标区域进行
文本理解类标注- 使用文本标注工具对文档进行
分类、字段抽取或比对差异等操作 - 比如合
同文本分类标注为“租赁合同”,或抽取“甲方、金额、有效期”等字段 - 文档比对场景中标注两份合同内容的差异点用于一致性检测
- 使用文本标注工具对文档进行
真实业务驱动- 平台广泛应用于
发票自动入账、房产证字段提取、合同盖章识别、文档归类、金融合同信息抽取、纸电合同比对等业务中 - 通过少量高质量样本标注支撑模型快速训练与迭代,兼顾定制化和通用性
- 平台广泛应用于
# 2)训练(训练集)
- 训练一个图像识别模型,能够根据图片自动检测并识别目标区域及其标签
输入:已标注的数据集(图像 + JSON)
模型选择:检测类模型、OCR模型
模型训练:
- 框架:PyTorch / TensorFlow / PaddlePaddle
- 输入:图像 + 标注框 + 标签
- 输出:检测到的位置框 + 预测类别 + 置信度
验证与评估
- 可视化检测效果,查看模型是否准确识别关键信息
总结流程图
标注数据(图/文+JSON)
↓
数据转换(COCO / BIO / Token)
↓
模型选择(YOLO / BERT / CRF等)
↓
模型训练(PyTorch / Transformers等)
↓
模型评估(准确率 / F1 / mAP)
↓
推理部署(API/SDK)
2
3
4
5
6
7
8
9
10
11
# 3)评测(测试集)
- 验证模型是否能准确识别图像中的目标区域(位置+字段标签+值),衡量模型泛化能力
评测流程① 模型推理对测试集中的每张图进行预测
得到:每个检测框的位置、字段类别、字段值、置信度
② 与标注数据对比- 将模型预测结果(pred.json)与人工标注(gt.json)进行字段级逐一比对
- 依据 IoU 和字段名称进行匹配,比较字段值是否完全一致(可容忍空格/符号误差)
- IoU 是否达标(> 0.5 通常认为匹配)
- 类型(字段名)是否一致
- 值是否完全一致(支持容错匹配,如空格、数字格式)
③ 计算指标判断预测对错,构建 confusion matrix(TP、FP、FN)
统计 Precision / Recall / mAP
评测指标文本分类
Accuracy(准确率):预测正确的比例
F1 Score(调和均值):综合考虑 Precision 和 Recall,适用于不均衡分类
Confusion Matrix:用于观察分类混淆情况
字段抽取
Token-level Precision / Recall / F1
Entity-level F1(整个字段是否预测正确)
支持“部分命中”或“值错位”统计
文档比对
相似度分数(Cosine/SimCSE)
段落对齐正确率
差异定位准确率
# 4)挖掘(错误样本)
- 错误样本挖掘不仅仅是“找错”,更重要的目的是“找到具有特征性的问题样本”,为模型改进提供方向
一、基础误差检测(漏检、错检)
初步收集错误样本,与标注真值比对,筛选出
字段未识别(漏检)
字段位置偏移严重(框错)
识别值不符(错读)
印章未识别/误识别
二、深入错误样本分析与特征归因(挖掘开始)
对错误图像提取关键视觉特征
- 图像分辨率(低于800x600分辨率的图)
- 光照条件(图片整体亮度 < 某阈值)
- 图像扭曲度(利用边框检测计算倾斜角度)
- 印章颜色(红色、蓝色、模糊印章)
- 背景干扰(是否存在背景阴影、水印)
对错误样本聚类,识别系统性问题类型
- Case 1:“红色底纹 + 夜间拍照”的图像中,金额字段误读率达70%
- 红底干扰OCR,光照差导致印刷体模糊
- Case 2:“印章偏上角”区域识别失败
- 特征:合同上方印章被遮挡一半、或非标准圆章
- 提示:模型没有见过这些变异印章样本
- Case 3:“票据歪斜>15度”的字段定位严重偏移
- 提示模型需加强旋转鲁棒性
- Case 1:“红色底纹 + 夜间拍照”的图像中,金额字段误读率达70%
挖掘:找到符合上面特征的bad case集合,用于新的训练
# 5)回流标注(再标注)
回流标注(Re-annotation)是指在模型训练或上线后- 对模型
识别效果不佳的数据进行再次人工标注或校正,以用于模型修正训练或精细化优化
# 6)推理
- 推理指的是将已训练好的模型应用到新样本上进行预测,输出所需的字段、类别、位置信息等
# 2、 模型闭环
- 模型迭代 → 部署 → 实时反馈 → 自动评估 → 在线学习/回滚机制
# 1)模型迭代(训练阶段)
- 目标:基于标注数据训练模型,通过错误样本精细化迭代,提升识别效果
- 数据准备
- 来自业务场景的真实图片或文档,结合人工标注
- 发票图像 + OCR辅助标注“金额、代码”;合同文本 + 抽取“甲方、有效期”
- 模型训练
- 使用合适的模型架构进行训练 图像类如 YOLO / DBNet / CRNN
- 印章识别中,加入印章颜色分类子任务;字段识别加入模糊、旋转数据增强
- 训练策略
- 基础模型 + 业务微调多任务学习:分类+抽取
- 对抗训练/图像增强:增强复杂图场景鲁棒性
- 合同图像中“非标准红章”误识别;发票中“旋转>15°”识别率下降
- 错误样本挖掘
- 自动化 pipeline 对误检样本聚类分析,如歪斜图、红底图、遮挡图
- 小样本优化
- 结合业务样本少的问题,引入 Few-shot/Fine-tune 方法
- 仅标注 50 份房产证模板,利用 layout-aware 模型如 LayoutLM
- 增量训练机制
- 仅用新增/错误样本 fine-tune 不完全重训,提高效率
- 每天新增的印章图像样本 100 张,供次日增量迭代
# 2)部署上线(服务化)
- 目标:将训练好的模型转化为在线服务供业务调用
- 模型打包
- 将模型权重导出为 ONNX / TorchScript / SavedModel 等格式
- PyTorch 模型导出为
model.pt供部署
- 服务封装
- 使用 Flask / FastAPI / Triton Inference Server 做模型封装
- 发票识别服务提供 REST API,输入图片返回结构化字段
- 模型上线策略
- A/B test 上线新模型,灰度发布,带版本的多模型管理
- v1 模型识别印章,v2 支持颜色分类,灰度上线后逐步全量
# 3)实时反馈收集
- 目标:获取真实业务调用后的预测结果与用户行为,用于回流优化
- 显式反馈
- 用户点击“识别错误”按钮并提供手动修正
- 标记该样本为 hard case,优先回流标注
- 隐式反馈
- 用户在自动入账后再次修改发票金额字段
- 自动识别该字段为错值,标记为误识别样本
- 系统日志
服务端记录每次推理字段置信度、字段缺失情况可挖掘字段置信度极低的场景,发现新类型样本
# 3、资源闭环
- 自动化、智能化地管理训练与推理任务中的计算资源(主要是GPU)
- 确保资源利用最大化,同时保障任务时效与公平
- 用户通过 Mage 平台提交一个模型训练任务,指定需要使用 GPU 资源
- 平台将该任务调度到合适的 GPU 节点上执行,并确保资源合理分配、故障可恢复、任务可监控
# 1)任务定义提交阶段
用户在前端或 CLI 提交任务时,平台将任务参数转化为 Kubernetes Job / CRD 资源
与 CPU 任务不同,GPU 任务必须设置
nvidia.com/gpu且
调度器会自动识别这些字段触发GPU-aware 调度路径
apiVersion: batch/v1
kind: Job
metadata:
name: train-task-abc123
namespace: ml-training
spec:
template:
spec:
containers:
- name: train
image: mage-registry/model-train:v1.0
resources:
limits:
nvidia.com/gpu: 2 # 必须显式声明 GPU 数量
cpu: "4"
memory: "16Gi"
restartPolicy: Never
tolerations: # 支持带 GPU 污点的节点调度
- key: "gpu"
operator: "Exists"
effect: "NoSchedule"
nodeSelector: # 或 node affinity 限定 GPU 类型
accelerator: "nvidia-a100"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 2)调度器调度阶段
- GPU 任务不能走默认的 K8s 调度器(
default-scheduler)路径 - 平台通常会使用自定义调度器插件,如
- Volcano (opens new window)(支持 gang scheduling、抢占、优先级队列)
- 或自研调度器插件(拦截并调度 GPU Pod)
调度流程如下
① 调度器接收 Pending GPU Pod② 过滤器阶段(Filter)- 资源是否满足:GPU 数量是否足够(包括显存)
- 污点/容忍度是否匹配(如节点打了
gpu=NoSchedule) - GPU 类型是否匹配(A100/V100/T4 等)
③ 优先级排序(Score)- 节点剩余资源率(prefer pack or spread)
- GPU Fragmentation(是否产生 GPU 零碎分配)
- 历史失败率(避免分配到 flaky 节点)
④ 抢占检查(Preemption)- 若所有节点资源不足,是否可以抢占低优先级任务释放资源
- 会在被抢占任务 Pod 上打上
deletionTimestamp,然后调度新任务
⑤ 绑定阶段(Bind)- 将 Pod 与目标 Node 绑定,并正式调度执行
# 3)节点执行准备
GPU Pod 调度成功后,节点上的 kubelet 启动容器
必须预先部署 NVIDIA Device Plugin (opens new window)
- 该插件通过共享内存
/var/lib/kubelet/device-plugins/与 kubelet 通信 - 注册
nvidia.com/gpu资源,并将 GPU 分配挂载到容器
- 该插件通过共享内存
若使用的是 containerd,则还需要
nvidia-container-runtime平台通常会抽象为「GPU Node 镜像准备就绪」状态,统一管理驱动版本、CUDA等依赖
# 4)自动回收与抢占逻辑
自动回收机制训练任务完成后,Job Controller 自动清理 Pod、PVC、挂载资源
GPU利用率 <10%、持续15分钟无stdout → 触发资源回收(需双确认)
推理服务长时间无QPS → 卸载容器或缩容副本
抢占策略(自研或基于 Volcano)高优任务提交 → 查询是否存在可抢占任务
- 判断是否满足抢占条件:
- 被抢任务优先级低、运行时间短、非关键任务
被抢占任务触发 graceful termination(写入日志 + graceful shutdown)
# 5)go-client调用
- 在平台后端(Golang),你们可能是通过
client-go编排 + 补充调度元信息
job := &batchv1.Job{
ObjectMeta: metav1.ObjectMeta{
Name: "train-job-001",
Namespace: "ml-training",
},
Spec: batchv1.JobSpec{
Template: corev1.PodTemplateSpec{
Spec: corev1.PodSpec{
Containers: []corev1.Container{{
Name: "train",
Image: "myimage:v1",
Resources: corev1.ResourceRequirements{
Limits: corev1.ResourceList{
"nvidia.com/gpu": resource.MustParse("2"),
"cpu": resource.MustParse("4"),
"memory": resource.MustParse("16Gi"),
},
},
}},
RestartPolicy: corev1.RestartPolicyNever,
Tolerations: []corev1.Toleration{{
Key: "gpu",
Operator: corev1.TolerationOpExists,
Effect: corev1.TaintEffectNoSchedule,
}},
NodeSelector: map[string]string{
"accelerator": "nvidia-a100",
},
},
},
},
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 6)调度前置服务
client-go是 单集群访问客户端,它一次只能连接一个 Kubernetes API Server- 平台支持多个 GPU 集群(如 A100 集群、V100 集群、跨机房集群),每个集群的 GPU 资源、节点状态都不同
- 因此,在
client-go发起 Job 创建前,平台必须先决策:调度到哪个集群、哪个 namespace
核心思路
- 在任务提交阶段,引入一个统一的调度前置服务(Multi-cluster GPU Dispatcher)
根据资源/策略/用户权限等进行智能选址
资源采集器(GPU集群状态聚合器)
各个集群部署资源上报组件(如 Metrics Server、Prometheus Exporter、Node Exporter)
周期性(如每 10 秒)汇总各集群的 GPU 总量、剩余量、当前负载、GPU类型、任务排队情况
将数据汇总到中央调度前置服务中,存入 Redis 或内部内存缓存
调度前置逻辑(Dispatcher)
平台在任务提交时,不直接使用 client-go 发请求,而是走调度前置服务
维度 决策逻辑示例 GPU 类型匹配 只考虑具备指定 GPU 型号的集群 GPU 利用率 优先调度到当前剩余最多的集群 排队时延预测 估算 job 启动时间,避免盲目排队 节点亲和性 若有镜像缓存、数据分布,优先靠近调度 用户权限 校验该用户是否具备目标集群权限 灰度实验策略 可动态打标:某类模型优先跑新集群
多集群 client-go 实例管理
- Dispatcher 拥有每个集群的 KubeConfig,通过动态切换
rest.Config实例来访问目标集群
- Dispatcher 拥有每个集群的 KubeConfig,通过动态切换
Namespace 映射和租户隔离
- 每个 GPU 集群预先创建对应的 namespace,如
ns-dev,ns-prod - 调度策略根据任务环境自动分配
- 训练任务 →
training-ns - 推理任务 →
serving-ns
- 训练任务 →
- 也支持一套租户规则
- 用户 ID
u123→ 所属 namespace 映射规则
- 用户 ID
- 每个 GPU 集群预先创建对应的 namespace,如
支持调度失败回退重试
- 如果 Dispatcher 调度到 A 集群,但任务因资源不足或抢占失败长时间排队,可加入自动 failover
- 任务状态中心定时检查排队任务状态
- 若 10 分钟未调度成功 → 回滚任务 → 重调度 B 集群
- 可结合任务重入幂等机制,保证任务不会重复执行
# 4、用户闭环
- 用户闭环:日志、告警、监控、审计全链路支持,确保可维护性与安全