 05.CICD
05.CICD
# 01.架构设计
# 1.0 介绍
项目介绍- Bamboo是京东自研的一套CI/CD流水线解决方案,实现了 持续、快速、高质量地交付你的产品
- 核心功能包括:
工程编译、静态代码检查、自动化测试、滚动部署、流量摘挂等流程 - 是基于 go/python/java/shell/js等多种语言编写实现的,采用 插件式开发,具备高可用可扩展的架构设计
- 核心服务包括:
流水线服务、云原生流水线引擎、Done发布平台、原子市场、代码检查、凭证管理等 - 使用微服务架构
- 服务层包括:前端服务、接口网关、后端服务、原子服务、存储层
- 微服务架构上主要选择:Nacos、Skywalking、ELK、Prometheus、SpringCloud Gateway网关、ETCD
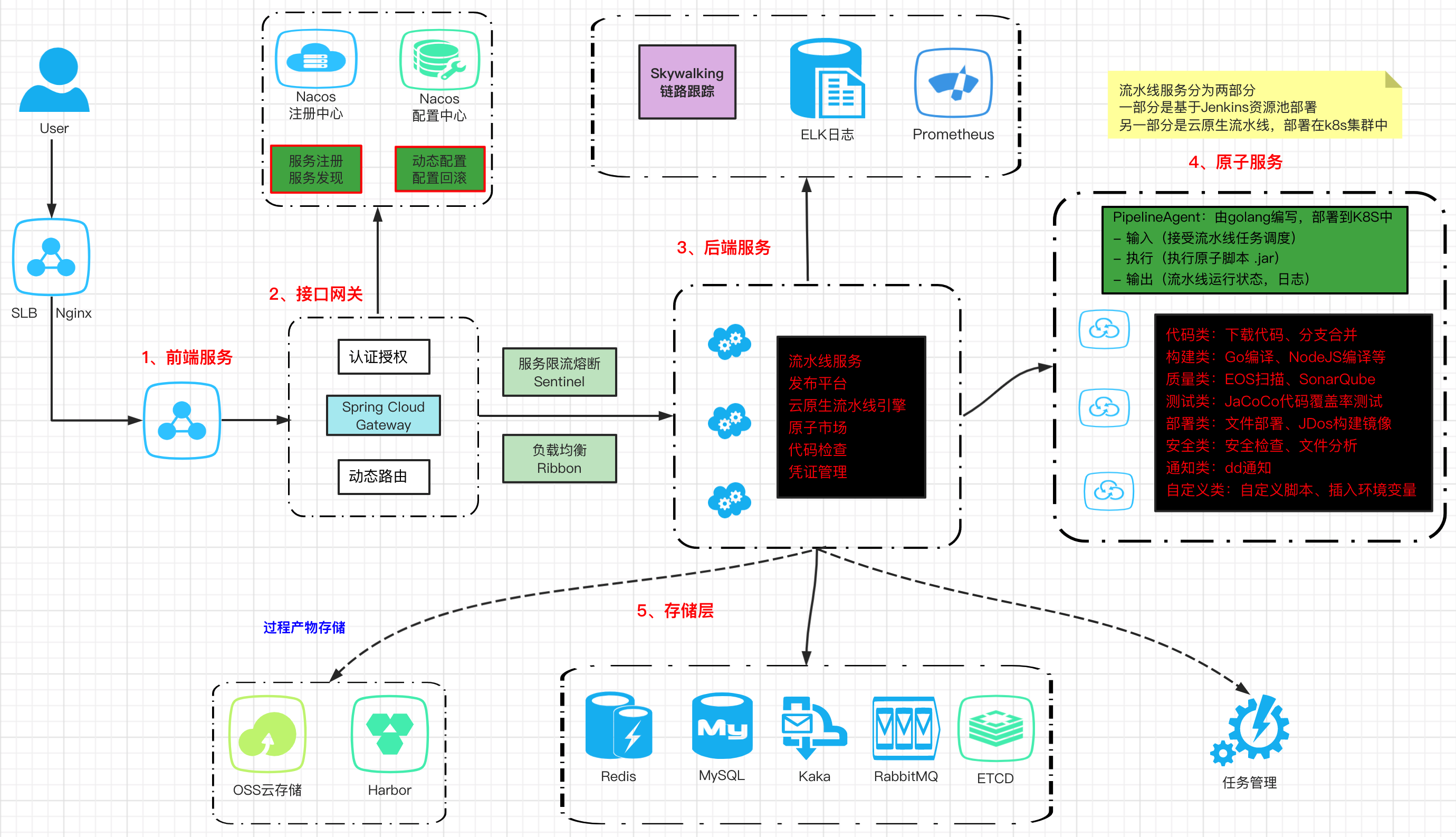
# 1.1 接口网关
- SpringCloud Gateway 接口网关服务
- 动态路由
- 认证授权
- 服务限流熔断Sentinel
# 1.2 后端服务
- 1)
流水线服务:主要负责流水线的资源编排- Pipeline(流水线)、Stage(阶段)、Jobs(作业)、Task(任务)
Pipeline(流水线)- 由多个 Stage 组成,同个 Pipeline 下的 Stage 串行执行,一个 Stage 失败,将不会执行后续 Stage
Stage(阶段)- 由多个 Job 组成,同个 Stage 下的 Job 并行执行,且 Job 与 Job 之间相互独立
Jobs(作业)- 由多个 Tasks(插件)组成,一个 Task 失败,则该 Job 失败,其余 Task 将不会运行
Task(任务)- 一个单独的任务,如拉取 GitHub 仓库代码,代码分支合并等
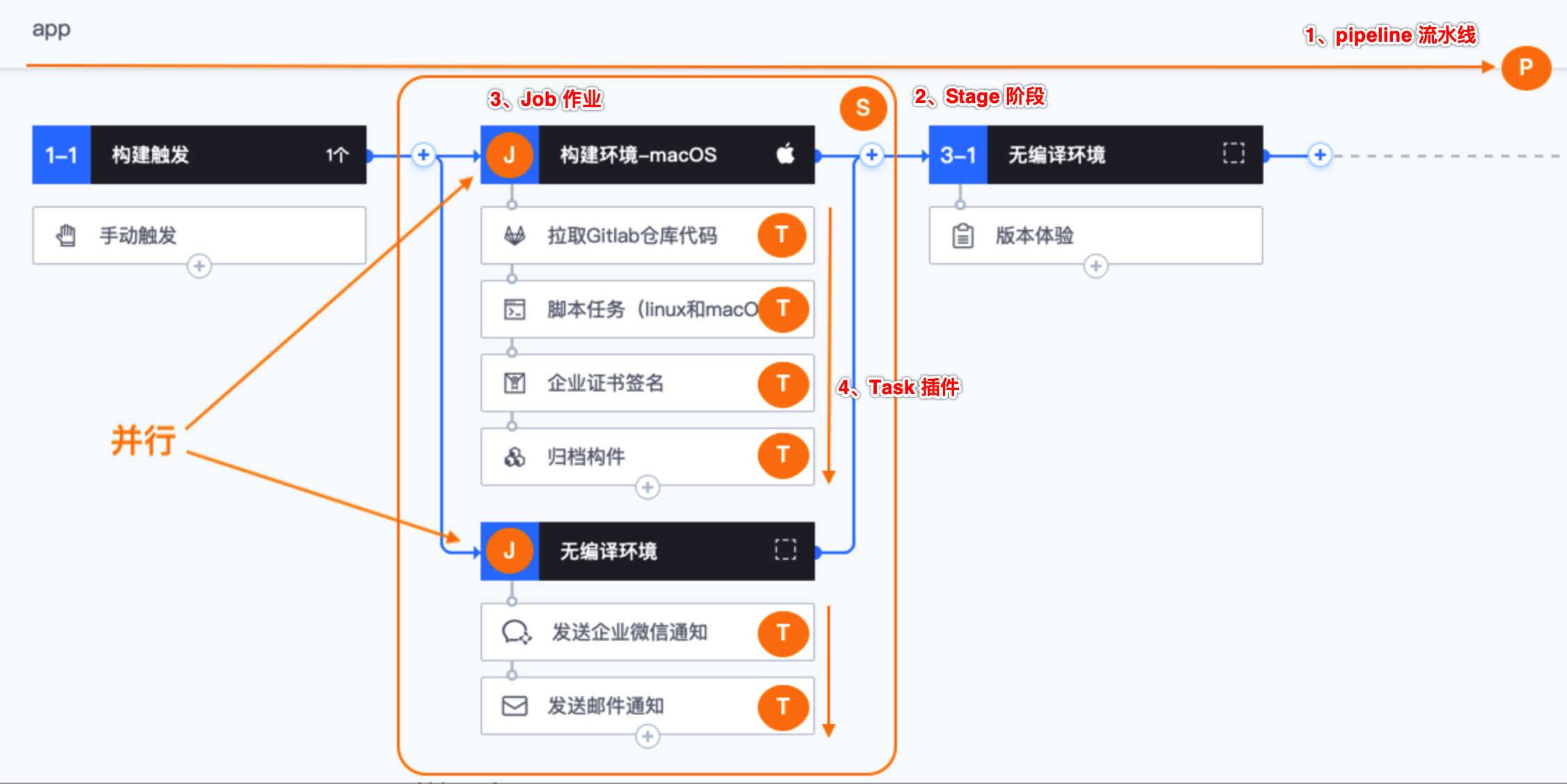
- 2)
全局调度服务:负责将流水线任务派发给对应云原生服务 或者 流水线服务- 全局调度服务维护了一个
全局任务队列 和 优先队列 - 调度器每隔1s钟启动一次调度服务,调度开始进入循环调度模式,直到
队列为空 或 资源不足结束 - 全局调度器有
抢注功能,多节点保持心跳服务,支持任务重新派发等功能 - 注:派发任务会从etcd中获取可用的执行服务,从队列中获获取任务进行派发
- 全局调度服务维护了一个
- 3)
云原生流水线引擎:将原子能力融入到K8S服务中,实现资源动态扩展能力- 云原生流水线引擎分为 master服务和slave服务
- master服务接收全局调度器任务调度,解析pipeline流水线任务,按照串并行原则调度对应原子执行
- slave服务可以简单理解是可以执行原子任务的pod节点,当流水线需要在pod中执行时动态创建
- Agent核心功能
接受流水线任务调度(输入)执行原子脚本(执行)流水线运行状态,日志(输出)
- 4)
Done发布平台:Done发布平台主要是面向全集团用户提供完整持续交付流程Done发布平台是架构于流水线服务之上,提供标准化发布流程解决方案- 主要流程包括:
预发发布、单台发布、灰度发布、机房发布四个阶段 - 核心功能包括:策略配置、策略自由编排、组件重试、组件回滚、灰度部署、多机房滚动部署、流量摘挂、分支预合并、团队应用管理、权限管理 等


- 5)
Log(构建日志服务):第一步:收集日志
- 通过与agent保持websocket通信,将日志按照 pipelieId/atomId.log 的文件夹中(在master服务中挂载大存储)
第二步:转发存储
- 开发日志转发agent,可以将日志对接到 kafka、ES等平台
Ticket(凭证管理服务):存储用户的凭证信息,比如代码库帐号密码/SSL/Token等信息Artifactory(制品构件服务): 该服务存储过程中制品信息(oss构建产物、Harbor镜像等)Store(原子市场):负责管理流水线原子插件
# 1.3 存储层与架构
MySQL:弹性数据库,存储所有关系型数据Redis:缓存构建机信息和构建时的信息和提供分布式锁操作等等Kafka:核心消息队列服务,推送流水线状态变化和流水线日志等RabbitMQ:作为异步任务分发队列ElasticSearch: 日志存储,log模块对接ES来对构建的日志做存取ETCD:服务注册、发现、配置管理、负载均衡OSS云存储:编译产物、图片、视频等Harbor:docker镜像存储- 微服务相关
SpringCloud Getaway:动态路由SSO:认证授权Sentinel:服务限流熔断Ribbon:负载均衡Nacos:服务注册、服务发现、配置管理Skywalking:链路追踪Prometheus:服务监控ELK:日志存储分析
# 1.4 原子服务
代码类:下载代码、分支合并构建类:Go编译、JAVA编译、Golang编译、Android编译、IOS编译、NodeJS编译、GCC编译等质量类:EOS扫描、SonarQube测试类:JaCoCo代码覆盖率测试、单元测试、Java接口测试部署类:文件部署、JDos部署、JDos构建镜像、NP网路平台、Django部署安全类:应用安全检查、IOS资源文件分析、Android安全加固通知类:咚咚通知自定义类:自定义脚本、插入环境变量
# 1.5 Agent(构建机)
流程介绍
- 构建机是负责运行CI打包编译构建的一台服务器/PC,是由比如go,gcc,java,python,nodejs等等编译环境依赖
- 在集群中
部署一类原子插件服务的一群机器定义为资源池(比如:GO环境资源池有 Go1.17、JDK1.8.0、Node10.16等) - 传统资源池资源固定,扩容复杂,云原生流水线通过agent加载BPE环境,
将服务部署到K8S集群中,方便动态扩容
构建机介绍
- 构建机是负责运行CI打包编译构建的一台服务器/PC/容器,是由比如go,gcc,java,python,nodejs等等编译环境依赖
PipelineAgent:由Golang编写实现
- Agent和原子插件同时编译到docker镜像里,通过k8s部署
- 虽然原子服务相同,编译环境依赖不同,所以不同资源池实现功能不同(比如go,java等等编译环境依赖)
- Agent核心功能
接受流水线任务调度(输入)加载执行原子脚本(执行)流水线运行状态,日志(输出)
PipelineWorker:
- 由java编写实现,是一个命名为agent.jar的脚本文件,任务真正的执行者
- 被PipelineAgent通过jre来拉起运行,之后会负责与Process(流水线管理)微服务模块通信
# 02.云原生流水线调度
# 2.1 云原生调度流程
1)
服务编排在前端配置流水线执行流程2)将流水线流程配置存储到bb服务端(MySQL)
3)bb服务端将任务派发到 云原生流水线服务
- api流水线管理接口(json)
- 权限管理
- 任务管理
- 任务调度
4)云原生流水线服务负责
接收任务请求,任务管理、任务调度云原生流水线在 redis中维护任务- 第一:全局队列 list 存放所有待执行任务
- 第二:使用 Hset 有序集合作为 加权任务队列
- 第三:使用 Hash 字典存放正在执行的任务(对超时任务处理)
5)Go Agent
流水线ExcutorAgent核心功能
接受流水线任务调度(输入)执行原子脚本 .jar(执行)流水线运行状态,日志(输出)
第一种:使用时创建和销毁(方便用户可以在任意mac机中运行)
- Agent是一个Go服务,部署到k8s集群的pod节点中
- 在创建pod节点时会指定agent拉取对应的原子代码
pod中agent启动后会定时拉取任务,执行,执行完成后主动销毁- 注:pod节点在创建后会返回当前pod的 container名字,可以通过这个名字来访问容器执行
第二种:Agent资源资源注册到ETCD中
- Go Agent根据环境不同,打包成不同docker镜像(比如:
服务端通用资源池、特殊服务资源池)- 服务端通用资源池 包括(Go、Node、JDK、Maven、Node、Ant、Gradle)等
- 同一类资源服务使用相同名称注册到etcd中作为作为微服务,提供不同类型原子服务
- 流水线
任务调度可以根据任务请求中携带的资源标识从etcd中获取对应的ip和端口进行服务调用 - 服务调用后状态被设置为进行中,并将处理任务的 ip:port 服务一同记录到redis的Hash字典中,以便主动进行任务状态查询
- Go Agent根据环境不同,打包成不同docker镜像(比如:
注:使用时创建和销毁弊端
高频使用的流水线,频繁创建销毁,浪费资源、消耗时间
不利于
代码编译和镜像构建的缓存复用(通过hostPath Volume在宿主机挂载并缓存,平均提速3~5倍)
# 2.2 缓存支持
- https://cloudnative.to/blog/cloudnative-devops/
缓存作用
- 缓存加速:自研容器化流水线的缓存技术,通过
代码编译和镜像构建的缓存复用,平均加速流水线3~5倍; - 细粒度缓存配置:任一阶段、步骤可以控制是否开启缓存及缓存路径;
- 可视化编辑界面,灵活配置流水线;
实现方案
云环境下的流水线是通过启动容器来运行具体的功能步骤,每次运行流水线可能会被调度到不同的计算节点上
这会导致一个问题:容器运行完是不会保存数据的,每当流水线重新运行时,
又会重新拉取代码、编译代码、下载依赖包等等失去了
本地宿主机编译代码、构建镜像时缓存的作用,大大延长了流水线运行时间,浪费很多不必要的时间、网络和计算成本等为了提高用户使用流水线的体验,加入支持缓存的功能,采用了k8s挂载hostPath Volume方式。
当流水线运行时我们会记录当前运行节点,下次运行时通过设置Pod的亲和性优先调度到该节点上
随着流水线运行次数越来越多,我们会得到一个运行节点列表。
# 03.Mage智能自动化平台
# 3.1 项目介绍
● 技术栈
Golang、Python、GRPC、Grpc-Gateway、Protobuf、Gin、Beego、Xzap、Cadence、MySQL、Redis、ElasticSearch、
Snowflake、OSS、MinIO、Nginx、Docker、K8S 、Istio
● 项目描述
Mage平台是软件机器人的眼睛和大脑,利用平台上已有的OCR、NLP原子能力以及深度学习模型,能够协助机器人理解文档,提取文档中的关键信息。
就拿我们生活中的各种单据报销为例,财务人员需要人工核对单据与审批系统上的金额是否一致,验证发票真实性等。
如果使用Mage平台,可以自动识别发票中的关键信息,验证发票真实性,自动完成审批流程,大大节省了人力成本
Mage平台技术上采用微服务架构,服务内部通过 GRPC 通信,外部调用提供 HTTP 接口,,后端主要使用Golang和Python,调用主要流程
1、服务端将文档或图片发送给OCR服务,提取文字和坐标信息
2、用户根据需求对数据进行框选,将框选结果和识别json发送给机器学习平台进行训练
3、训练后的模型就可以实现用户对数据进行精确抽取
# 3.2 总体介绍
对RPA机器人来说,如果说AI是它的大脑,认知能力是它的眼睛、嘴、耳朵,RPA是它的双手。
结合了AI能力,RPA从只能帮助基于规则的、机械性、重复性的任务实现自动化,拓展到了更丰富的业务场景
将物理世界与数字世界有效连接,满足实际业务中更灵活、多元的自动化需求。
而企业采用具备AI能力的RPA平台,可以快速、经济、灵活地将AI技术应用到业务中。

- 提供丰富的预训练的AI模型。 使用者无需AI经验,开箱即用。
- 提供强大的定制化的AI能力。 使用者可以在自己的数据集上,通过无代码的方式,标注、训练、测评、优化AI模型,使模型能够理解专业领域的文档。
- 通过预置件和Creator无缝集成。 通过拖拽即可让机器人具备AI能力,帮助企业快速落地RPA+AI。
- 支持公有云、私有部署以及混合部署方式。 私有部署支持国产化适配,保证数据的私密性。
- 适用于财务、人力、法务、IT运维、电网、运营商、营销、客服等各行各业,形成端到端的智能自动化解决方案。
# 3.3 AI能力介绍
- 自训练抽取:
- 1)新建字段、2)上传数据、3)标注数据
- 4)构建数据集、5)新建版本、6)评测、7)发布版本
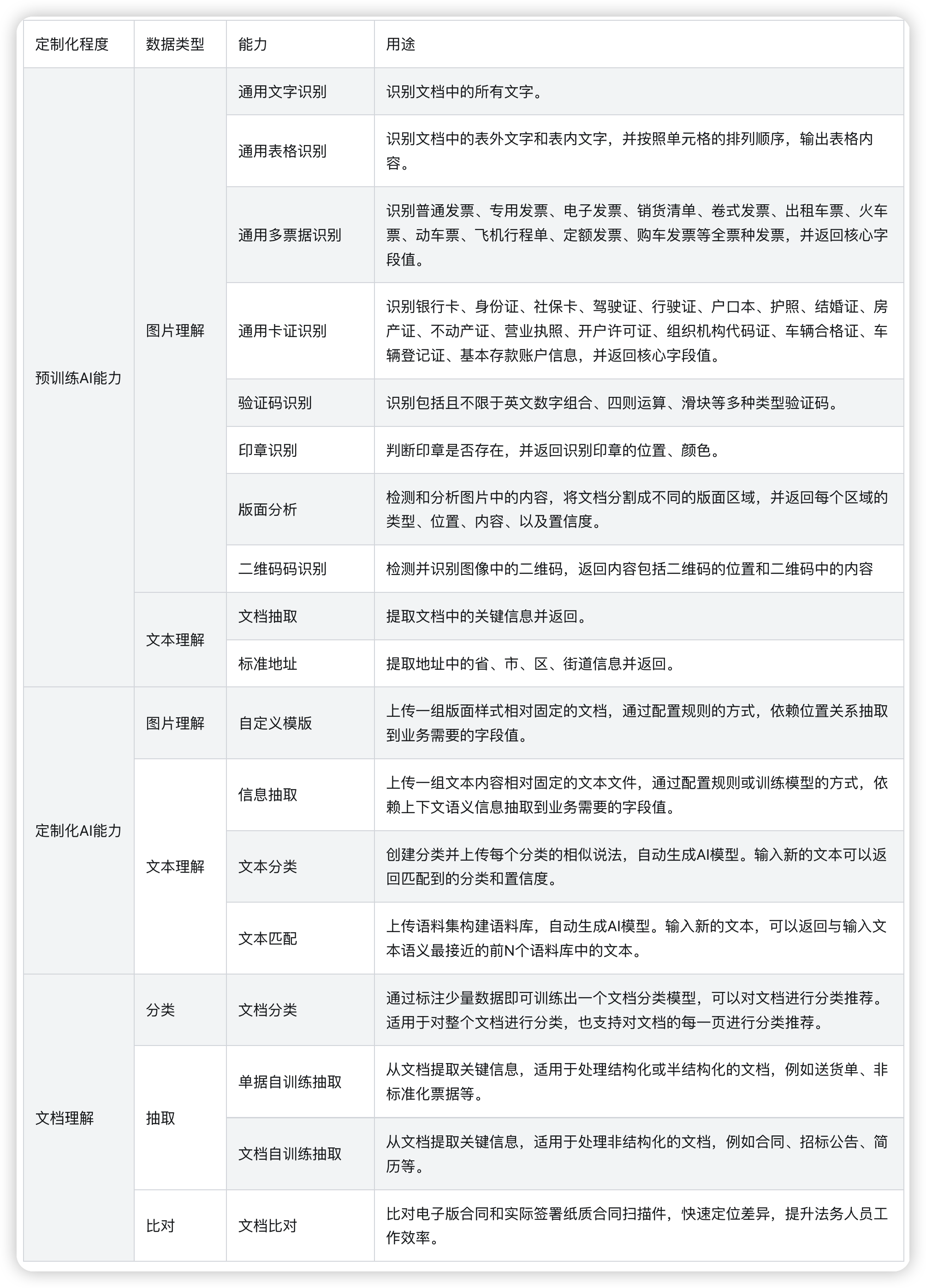
1、从定制化程度看,AI能力可以分为通用AI能力和定制化AI能力两类。
- 预训练AI能力提供了开箱即用的AI模型,能够处理通用文档、表格等非结构化数据,以及身份证、营业执照、增值税发票、火车票识别等结构化数据。
- 定制化AI能力,需要上传自己的数据,通过标注、训练、测评、优化AI模型,使模型能够理解专业领域的文档。
2、从处理的数据类型上看,AI能力可以分为图片理解、文本理解。
3、此外,平台有综合性的AI能力,提供文档的端到端解决方案,利用平台上已有的OCR、NLP原子能力以及深度学习模型,能够协助机器人理解文档,提取文档中的关键信息。
# 3.4 网关路由
- nginx(Mage.laiye.com)
- istio(匹配不同域名,根据域名匹配对应服务环境)
- Ingress

- 应对复杂的变化一直都是软件工程的核心难点问题
- 如何用较小的架构变化应对较大的业务变化,就是设计中常说的:高内聚、低耦合;
- 还需要补充很重要的一点:单从技术层面是无法持续解决复杂问题的
- 还需要从管理角度去定义流程标准,规范各种解决方案,是整个部门要持续面对的事项。