 08.redis和rabbitmq区别
08.redis和rabbitmq区别
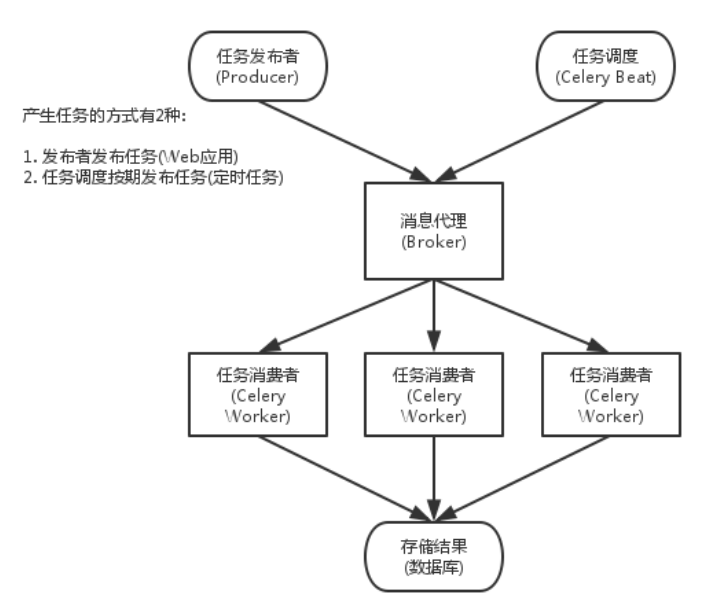
# 01.celery工作流程
# 1.1 celery工作流程
消息中间件(message broker):
- Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成。
- 包括,RabbitMQ, Redis, MongoDB ,SQLAlchemy等
- 其中rabbitm与redis比较稳定,其他处于测试阶段。
任务执行单元(worker):
- Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
任务结果存储(result store):
- result store用来存储Worker执行的任务的结果,支持AMQP,redis,mongodb,mysql等主流数据库。
# 1.2 并发、序列化、压缩
celery任务并发执行支持prefork、eventlet、gevent、threads的方式;
序列化支持pickle,json,yaml,msgpack等;
压缩支持zlib, bzip2 。
# 1.3 celery使用中的一些建议和优化
(1)如果你的broker使用的是rabbitmq
- 可安装一个C语言版的客户端librabbitmq来提升性能
- pip install librabbitmq;
(2)通过 BROKER_POOL_LIMIT 参数配置消息中间件的连接池;
(3)通过CELERYD_PREFETCH_MULTIPLIER 参数配置消息预取的数量
- 如果消息队列中有很多消息,这个值建议设为1,以达到各个worker的最大化利用;
(4)指定worker消费的队列
- 如果你根据业务配置了多个不同的消息队列,各个队列的任务量大小不同
- 可以在worker启动时指定消费队列 celery -A app_name -l INFO -Q queue1,queue2
(5)worke(prefork)默认启动cpu核数个子进程
- 进程管理可以使用supervisor,supervisor是用Python开发的一套通用的进程管理程序
- 能将一个普通的命令行进程变为后台daemon,并监控进程状态,异常退出时能自动重启
# 02.rabbitMQ和redis区别
# 2.1 可靠性
- redis :
- 没有相应的机制保证消息的可靠消费,如果发布者发布一条消息
- 而没有对应的订阅者的话,这条消息将丢失,不会存在内存中
- rabbitMQ:
- 具有消息消费确认机制,如果发布一条消息,还没有消费者消费该队列,那么这条消息将一直存放在队列中
- 直到有消费者消费了该条消息,以此可以保证消息的可靠消费
# 2.2 实时性
- redis:实时性高,redis作为高效的缓存服务器,所有数据都存在在服务器中,所以它具有更高的实时性
# 2.3 消费者负载均衡
- redis发布订阅模式
- 一个队列可以被多个消费者同时订阅,当有消息到达时,会将该消息依次发送给每个订阅者;
- rabbitMQ队列可以被多个消费者同时监控消费
- 但是每一条消息只能被消费一次,由于rabbitMQ的消费确认机制
- 因此它能够根据消费者的消费能力而调整它的负载;
# 2.4 持久性
- redis:redis的持久化是针对于整个redis缓存的内容,它有RDB和AOF两种持久化方式(redis持久化方式,后续更新),可以将整个redis实例持久化到磁盘,以此来做数据备份,防止异常情况下导致数据丢失。
- rabbitMQ:队列,消息都可以选择性持久化,持久化粒度更小,更灵活;
# 2.5 队列监控
- rabbitMQ实现了后台监控平台,可以在该平台上看到所有创建的队列的详细情况,良好的后台管理平台可以方便我们更好的使用;
- redis没有所谓的监控平台。
# 2.6 总结
- redis: 轻量级,低延迟,高并发,低可靠性;
- rabbitMQ:重量级,高可靠,异步,不保证实时;
- rabbitMQ是一个专门的AMQP协议队列,他的优势就在于提供可靠的队列服务,并且可做到异步,而redis主要是用于缓存的,redis的发布订阅模块,可用于实现及时性,且可靠性低的功能。
上次更新: 2024/3/13 15:35:10