 101.困难题
101.困难题
# 01.排序链表(难)
# 1.1 题目描述
输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]
1
2
2
# 1.2 解题思路
找到链表的中点,以中点为分界,将链表拆分成两个子链表。
寻找链表的中点可以使用快慢指针的做法,快指针每次移动 2步,慢指针每次移动 1 步
当快指针到达链表末尾时,慢指针指向的链表节点即为链表的中点。
对两个子链表分别排序,将两个排序后的子链表合并,得到完整的排序后的链表
class ListNode:
def __init__(self,val=None, next=None):
self.val = val
self.next = next
def sortList(head):
# 找到链表的中点,以中点为分界,将链表拆分成两个子链表
def sortFunc(head, tail):
'''
:param head: 链表头部为 head
:param tail: 链表尾部初始值为 None
'''
if not head: # 如果链表头部为None直接返回
return head
if head.next == tail: # 如果链表头部下一个元素 = 链表尾部元素 返回head
head.next = None
return head
slow = fast = head # 快慢指针刚开始都执行 head
while fast != tail:
slow = slow.next
fast = fast.next # 快指针先走一步
if fast != tail: # 判断当前快指针是否达到 链表尾部
fast = fast.next # 如果快指针没有达到链表尾部,那么快指针再移动一位
mid = slow # 当上面 while 循环退出时,此时的 slow慢指针 的位置就是链表中心位置
return merge(sortFunc(head, mid), sortFunc(mid, tail))
def merge(head1, head2):
dummyHead = ListNode(0) # 新建一个链表
temp, temp1, temp2 = dummyHead, head1, head2
while temp1 and temp2:
if temp1.val <= temp2.val:
temp.next = temp1
temp1 = temp1.next
else:
temp.next = temp2
temp2 = temp2.next
temp = temp.next
if temp1:
temp.next = temp1
elif temp2:
temp.next = temp2
return dummyHead.next
return sortFunc(head, None)
l1 = ListNode(-1,ListNode(5,ListNode(3,ListNode(4,ListNode(0))))) # -1 -> 5 -> 3 -> 4 -> 0
l = sortList(l1) # -1 -> 0 -> 3 -> 4 -> 5
while l:
print(l.val) # -1 -> 0 -> 3 -> 4 -> 5
l = l.next
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 02.单词搜索
# 2.1 题目描述
- 给定一个二维网格和一个单词,找出该单词是否存在于网格中
- 单词必须按照字母顺序,通过相邻的单元格内的字母构成
- 其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。
- 同一个单元格内的字母不允许被重复使用。
board =
[
['A','B','C','E'],
['S','F','C','S'],
['A','D','E','E']
]
给定 word = "ABCCED", 返回 true
给定 word = "SEE", 返回 true
给定 word = "ABCB", 返回 false
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
# 2.2 深度优先搜索
使用深度优先搜索(DFS)和回溯的思想实现。
关于判断元素是否使用过,我用了一个二维数组
mark对使用过的元素做标记。外层:遍历
- 首先遍历 board 的所有元素,先找到和 word 第一个字母相同的元素,然后进入递归流程
- 假设这个元素的坐标为 (i, j),进入递归流程前,先记得把该元素打上使用过的标记
内层:递归
- 好了,打完标记了,现在我们进入了递归流程。递归流程主要做了这么几件事:
- 从 (i, j) 出发,朝它的上下左右试探,看看它周边的这四个元素是否能匹配 word 的下一个字母
- 如果匹配到了:带着该元素继续进入下一个递归
- 如果都匹配不到:返回 False
- 当 word 的所有字母都完成匹配后,整个流程返回 True
class Solution:
directs = [(0, 1), (0, -1), (1, 0), (-1, 0)] # 定义上下左右四个行走方向
def exist(self, board, word):
n = len(board[0]) # 获取二维网格 长
m = len(board) # 获取二维网格 宽
# 定义一个二维数组 `mark` 对使用过的元素做标记
mark = [[0 for _ in range(n)] for _ in range(m)]
for i in range(m):
for j in range(n):
if board[i][j] == word[0]:
mark[i][j] = 1 # 将该元素标记为已使用
if self.backtrack(i, j, mark, board, word[1:]) == True:
return True
else:
mark[i][j] = 0 # 回溯
return False
def backtrack(self, i, j, mark, board, word):
if len(word) == 0:
return True
for direct in self.directs:
cur_i = i + direct[0]
cur_j = j + direct[1]
if cur_i >= 0 \
and cur_i < len(board) \
and cur_j >= 0 and cur_j < len(board[0]) \
and board[cur_i][cur_j] == word[0]:
if mark[cur_i][cur_j] == 1: # 如果是已经使用过的元素,忽略
continue
mark[cur_i][cur_j] = 1 # 将该元素标记为已使用
if self.backtrack(cur_i, cur_j, mark, board, word[1:]) == True:
return True
else:
mark[cur_i][cur_j] = 0 # 回溯
return False
board = [
['A', 'B', 'C', 'E'],
['S', 'F', 'C', 'S'],
['A', 'D', 'E', 'E']
]
print(Solution().exist(board, "ABCCED")) # True
print(Solution().exist(board, "SEE")) # True
print(Solution().exist(board, "ABCB")) # False
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 03.字符串的排列(难)
# 3.1 题目描述
- 字符串的排列 (opens new window)
- 输入一个字符串,打印出该字符串中字符的所有排列
输入:s = "abc"
输出:["abc","acb","bac","bca","cab","cba"]
1
2
2
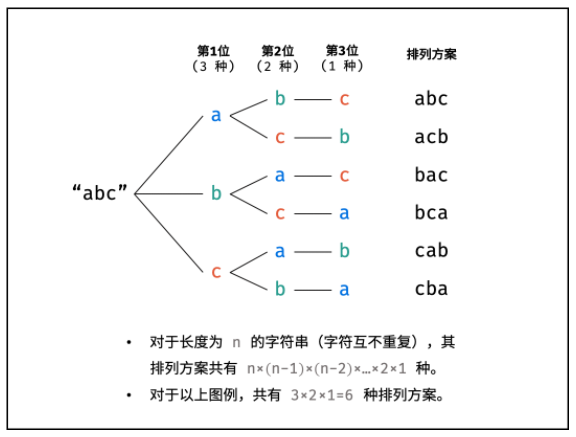
- 排列方案的生成
- 根据字符串排列的特点,考虑深度优先搜索所有排列方案。
- 即通过字符交换,先固定第 1 位字符( n 种情况)
- 再固定第 2 位字符( n-1 种情况)
- 最后固定第 n 位字符( 1 种情况)
# 3.2 解题思路
终止条件: 当 x = len(c) - 1 时,代表所有位已固定(最后一位只有 1种情况)
则将当前组合 c 转化为字符串并加入 res ,并返回;
递推参数: 当前固定位 x ;
递推工作: 初始化一个 Set ,用于排除重复的字符;
将第 x 位字符与 i in∈ [x, len(c)] 字符分别交换,并进入下层递归;
- 剪枝: 若 c[i] 在 Set 中,代表其是重复字符,因此 “剪枝” ;
- 将 c[i] 加入 Set ,以便之后遇到重复字符时剪枝;
- 固定字符: 将字符 c[i] 和 c[x] 交换,即固定 c[i] 为当前位字符;
- 开启下层递归: 调用 dfs(x + 1) ,即开始固定第 x + 1 个字符;
- 还原交换: 将字符 c[i] 和 c[x] 交换(还原之前的交换);
def handle(s):
c, res = list(s), [] # 将字符串数组ArrayList转化为String类型数组
def dfs(x):
if x == len(c) - 1:
res.append(''.join(c)) # 添加排列方案
return
dic = set() # 为了防止同一层递归出现重复元素
for i in range(x, len(c)):
if c[i] in dic: continue # 重复,因此剪枝
dic.add(c[i])
print(c,11111111)
c[i], c[x] = c[x], c[i] # 交换,将 c[i] 固定在第 x 位
print(c,2222222)
dfs(x + 1) # 开启固定第 x + 1 位字符(进入下一层递归)
c[i], c[x] = c[x], c[i] # 恢复交换
print(c,3333333333333)
dfs(0) # 从第一层开始递归
return res
if __name__ == "__main__":
s = "abc"
print( handle(s) ) # ['abc', 'acb', 'bac', 'bca', 'cba', 'cab']
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
编辑 (opens new window)
上次更新: 2024/3/13 15:35:10