 04.各种数据类型操作
04.各种数据类型操作
# 01.string
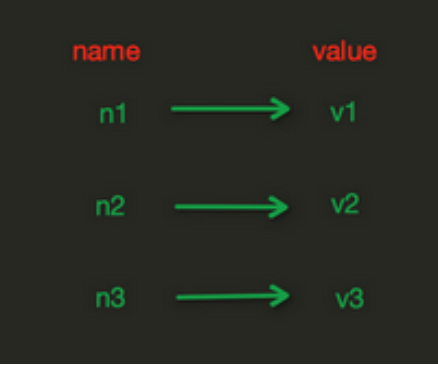
# 1.1 String存存储样式
- 注:String操作,Redis中的String在在内存中按照一个name对应一个value字典形式来存储
# 1.2 set常用参数
- set(name, value, ex=None, px=None, nx=False, xx=False)
1) ex,过期时间(秒)
2) px,过期时间(毫秒)
3) nx,如果设置为True,则只有name不存在时,当前set操作才执行
4) xx,如果设置为True,则只有name存在时,当前set操作才执行
# 1.3 string常用命令
import Redis
r = Redis.Redis(host='1.1.1.3', port=6379)
#1、打印这个Redis缓存所有key以列表形式返回:[b'name222', b'foo']
print( r.keys() ) # keys *
#2、清空Redis
r.flushall()
#3、设置存在时间: ex=1指这个变量只会存在1秒,1秒后就不存在了
r.set('name', 'Alex') # ssetex name Alex
r.set('name', 'Alex',ex=1) # ssetex name 1 Alex
#4、获取对应key的value
print(r.get('name')) # get name
#5、删除指定的key
r.delete('name') # del 'name'
#6、避免覆盖已有的值: nx=True指只有当字典中没有name这个key才会执行
r.set('name', 'Tom',nx=True) # setnx name alex
#7、重新赋值: xx=True只有当字典中已经有key值name才会执行
r.set('name', 'Fly',xx=True) # set name alex xx
#8、psetex(name, time_ms, value) time_ms,过期时间(数字毫秒 或 timedelta对象)
r.psetex('name',10,'Tom') # psetex name 10000 alex
#10、mset 批量设置值; mget 批量获取
r.mset(key1='value1', key2='value2') # mset k1 v1 k2 v2 k3 v3
print(r.mget({'key1', 'key2'})) # mget k1 k2 k3
#11、getset(name, value) 设置新值并获取原来的值
print(r.getset('age','100')) # getset name tom
#12、getrange(key, start, end) 下面例子就是获取name值abcdef切片的0-2间的字符(b'abc')
r.set('name','abcdef')
print(r.getrange('name',0,2))
#13、setbit(name, offset, value) #对name对应值的二进制表示的位进行操作
r.set('name','abcdef')
r.setbit('name',6,1) #将a(1100001)的第二位值改成1,就变成了c(1100011)
print(r.get('name')) #最后打印结果:b'cbcdef'
#14、bitcount(key, start=None, end=None) 获取name对应的值的二进制表示中 1 的个数
#15、incr(self,name,amount=1) 自增 name对应的值,当name不存在时,则创建name=amount,否则自增
#16、derc 自动减1:利用incr和derc可以简单统计用户在线数量
#如果以前有count就在以前基础加1,没有就第一次就是1,以后每运行一次就自动加1
num = r.incr('count')
#17、num = r.decr('count') #每运行一次就自动减1
#每运行一次incr('count')num值加1每运行一次decr后num值减1
print(num)
#18、append(key, value) 在Redis name对应的值后面追加内容
r.set('name','aaaa')
r.append('name','bbbb')
print(r.get('name')) #运行结果: b'aaaabbbb'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
# 1.4 使用案例
# 1、计数器
- 假设我们要记录网站的访问次数,可以设置一个 key 叫做 "website:views"
# 创建计数器
SET website:views 0
# 计数器+1
INCR website:views
(integer) 1
1
2
3
4
5
2
3
4
5
# 2、分布式锁
- 假设我们有一个需要同步的操作,我们可以使用 SET 命令和 NX 选项来实现一个简单的分布式锁
SET lock:my_operation "twgdh" NX EX 300
# 这行命令试图获取一个叫做 "lock:my_operation" 的锁
# 如果这个锁不存在(NX 选项),那么就设置这个锁的值为 "twgdh",并且在 300 秒后过期(EX 选项)
# 如果返回 "OK",那么说明我们成功获取了这个锁,可以进行同步操作
# 如果返回 nil,那么说明其他人已经持有这个锁,我们需要等待
1
2
3
4
5
6
2
3
4
5
6
# 02.Hash
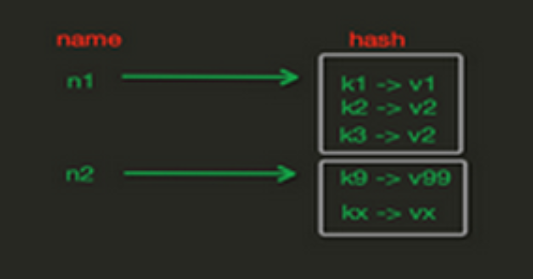
# 2.1 Hash在内存存储样式
- 注: hash在内存中存储可以不像string中那样必须是字典,可以一个键对应一个字典
# 2.2 Redis对Hash字典操作
import Redis
pool = Redis.ConnectionPool(host='1.1.1.3', port=6379)
r = Redis.Redis(connection_pool=pool)
#1 hset(name, key, value) name=字典名字,key=字典key,value=对应key的值
r.hset('info','name','tom') # hset info name tom
r.hset('info','age','100')
print(r.hgetall('info')) # hgetall info {b'name': b'tom', b'age': b'100'}
print(r.hget('info','name')) # hget info name b'tom'
print(r.hkeys('info')) #打印出”info”对应的字典中的所有key [b'name', b'age']
print(r.hvals('info')) #打印出”info”对应的字典中的所有value [b'tom', b'100']
#2 hmset(name, mapping) 在name对应的hash中批量设置键值对
r.hmset('info2', {'k1':'v1', 'k2': 'v2','k3':'v3'}) #一次性设置多个值
print(r.hgetall('info2')) #hgetall() 一次性打印出字典中所有内容
print(r.hget('info2','k1')) #打印出‘info2’对应字典中k1对应的value
print(r.hlen('info2')) # 获取name对应的hash中键值对的个数
print(r.hexists('info2','k1')) # 检查name对应的hash是否存在当前传入的key
r.hdel('info2','k1') # 将name对应的hash中指定key的键值对删除
print(r.hgetall('info2'))
#3 hincrby(name, key, amount=1)自增name对应的hash中的指定key的值,不存在则创建key=amount
r.hincrby('info2','k1',amount=10) #第一次赋值k1=10以后每执行一次值都会自动增加10
print(r.hget('info2','k1'))
#4 hscan(name, cursor=0, match=None, count=None)对于数据大的数据非常有用,hscan可以实现分片的获取数据
# name,Redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
print(r.hscan('info2',cursor=0,match='k*')) #打印出所有key中以k开头的
print(r.hscan('info2',cursor=0,match='*2*')) #打印出所有key中包含2的
#5 hscan_iter(name, match=None, count=None)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
for item in r.hscan_iter('info2'):
print(item)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 2.3 使用案例
# 1、用户信息管理
- 用户信息: 利用 hset 和 hget 命令实现对象属性的增删改查
- 配置信息: 利用 hmset 和 hmget 命令实现批量设置和获取配置项
# 添加用户信息
HSET user:1001 name "Tom"
HSET user:1001 email "tom@example.com"
HSET user:1001 age 30
# 获取用户信息
HGET user:1001 name
HGET user:1001 email
HGET user:1001 age
# 修改用户信息
HSET user:1001 age 31
# 删除用户的某个属性
HDEL user:1001 age
# 查询用户的所有属性
HGETALL user:1001
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# 2、商品数量增减
- 购物车: 利用 hincrby 命令实现商品数量的增减
# 购物车ID为1001的购物车中itemA的数量增加1
HINCRBY cart:1001 itemA 1
# 减少商品的数量
HINCRBY cart:1001 itemA -1
# 获取购物车中的商品数量
HGET cart:1001 itemA
# 获取购物车中的所有商品和数量
HGETALL cart:1001
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# 03.List
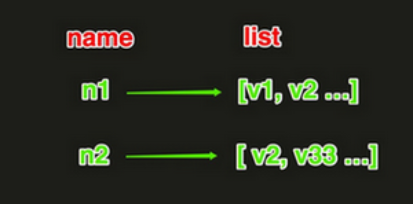
# 3.1 List内存中存储样式
# 3.2 List常用操作
import Redis
pool = Redis.ConnectionPool(host='10.1.0.51', port=6379)
r = Redis.Redis(connection_pool=pool)
#1 lpush:反向存放 rpush正向存放数据
r.lpush('names','alex','tom','jack') # 从右向左放数据比如:3,2,1(反着放)
print(r.lrange('names',0,-1)) # 结果:[b'jack', b'tom']
r.rpush('names','zhangsan','lisi') #从左向右放数据如:1,2,3(正着放)
print(r.lrange('names',0,-1)) #结果:b'zhangsan', b'lisi']
#2.1 lpushx(name,value) 在name对应的list中添加元素,只有name已经存在时,值添加到列表最左边
#2.2 rpushx(name, value) 表示从右向左操作
#3 llen(name) name对应的list元素的个数
print(r.llen('names'))
#4 linsert(name, where, refvalue, value)) 在name对应的列表的某一个值前或后插入一个新值
# name,Redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
r.rpush('name2','zhangsan','lisi') #先创建列表[zhangsan,lisi]
print(r.lrange('name2',0,-1))
r.linsert('name2','before','zhangsan','wangwu') #在张三前插入值wangwu
r.linsert('name2','after','zhangsan','zhaoliu') #在张三前插入值zhaoliu
print(r.lrange('name2',0,-1))
#5 r.lset(name, index, value) 对name对应的list中的某一个索引位置重新赋值
r.rpush('name3','zhangsan','lisi') #先创建列表[zhangsan,lisi]
r.lset('name3',0,'ZHANGSAN') #将索引为0的位置值改成'ZHANGSAN'
print(r.lrange('name3',0,-1)) #最后结果:[b'ZHANGSAN', b'lisi']
#6 r.lrem(name, value, num) 在name对应的list中删除指定的值
# name,Redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
r.rpush('name4','zhangsan','zhangsan','zhangsan','lisi')
r.lrem('name4','zhangsan',1)
print(r.lrange('name4',0,-1))
#7 lpop(name) 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
r.rpush('name5','zhangsan','lisi')
r.rpop('name5')
print(r.lrange('name5',0,-1))
#8 lindex(name, index) 在name对应的列表中根据索引获取列表元素
r.rpush('name6','zhangsan','lisi')
print(r.lindex('name6',1))
#9 lrange(name, start, end) 在name对应的列表分片获取数据
r.rpush('num',0,1,2,3,4,5,6)
print(r.lrange('num',1,3))
#10 ltrim(name, start, end) 在name对应的列表中移除没有在start-end索引之间的值
r.rpush('num1',0,1,2,3,4,5,6)
r.ltrim('num1',1,2)
print(r.lrange('num1',0,-1))
#11 rpoplpush(src, dst) 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
r.rpush('num2',0,1,2,3)
r.rpush('num3',100)
r.rpoplpush('num2','num3')
print(r.lrange('num3',0,-1)) #运行结果:[b'3', b'100']
#12 blpop(keys, timeout) 将多个列表排列,按照从左到右去pop对应列表的元素
#timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
r.rpush('num4',0,1,2,3)
r.blpop('num4',10)
print(r.lrange('num4',0,-1))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
# 3.3 使用案例
# 1、消息队列
- 消息队列:可以作为消息队列使用
# 生产者添加消息到队列
LPUSH myqueue "Hello World"
# 消费者从队列中取出消息
RPOP myqueue
1
2
3
4
2
3
4
- 延时队列:
- Redis List 类型可以用来实现延时队列
- 通过 LPUSH 和 BRPOP 命令可以实现在列表头部插入元素并在列表尾部阻塞取出元素
如果列表为空,BRPOP 命令会等待指定的超时时间
# 生产者添加消息到队列
LPUSH myqueue "Hello World"
# 名为 myqueue 的队列为空时,让消费者等待直到有消息可取,0 表示消费者会一直等待直到有消息
BRPOP myqueue 0
1
2
3
4
2
3
4
# 2、最新列表
Redis List 类型可以用来存储最新的 N 个元素,比如最新的日志信息、最新的新闻、最新的评论等
通过 LPUSH 和 LTRIM 命令可以实现在列表头部插入元素并
保持列表长度不超过 N历史列表:
- Redis List 类型可以用来存储历史记录,比如用户的浏览历史、购物历史等
- 通过 LPUSH 命令可以在列表头部插入元素,通过
LRANGE 命令可以获取列表中的一段元素
# 将"comment01"添加到名为 comments 的列表的左边
LPUSH comments "comment01"
# 查长度
LLEN comments
# 如果列表的长度超过了设定的最大长度,删除最旧的评论
LTRIM comments 0 <最大长度-1>
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# 04.set集合
# 1、集合常用操作
import Redis
r = Redis.Redis(host='10.1.0.51', port=6379)
#1 sadd(name,values) name对应的集合中添加元素
#2 scard(name) 获取name对应的集合中元素个数
r.sadd('name0','alex','tom','jack')
print(r.scard('name0'))
#3 sdiff(keys, *args) 在第一个name对应的集合中且不在其他name对应的集合的元素集合
r.sadd('num6',1,2,3,4)
r.sadd('num7',3,4,5,6) #在num6中有且在num7中没有的元素
print(r.sdiff('num6','num7')) #运行结果:{b'1', b'2'}
#4 sdiffstore(dest, keys, *args)
#获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
# 将在num7中不在num8中的元素添加到num9
r.sadd('num7',1,2,3,4)
r.sadd('num8',3,4,5,6)
r.sdiffstore('num9','num7','num8')
print(r.smembers('num9')) #运行结果: {b'1', b'2'}
#5 sinter(keys, *args) 获取多一个name对应集合的交集
r.sadd('num10',4,5,6,7,8)
r.sadd('num11',1,2,3,4,5,6)
print(r.sinter('num10','num11')) #运行结果: {b'4', b'6', b'5'}
#6 sinterstore(dest, keys, *args) 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
r.sadd('num12',1,2,3,4)
r.sadd('num13',3,4,5,6)
r.sdiffstore('num14','num12','num13')
print(r.smembers('num14')) #运行结果: {b'1', b'2'}
#7 sismember(name, value) 检查value是否是name对应的集合的成员
r.sadd('name22','tom','jack')
print(r.sismember('name22','tom'))
#8 smove(src, dst, value) 将某个成员从一个集合中移动到另外一个集合
r.sadd('num15',1,2,3,4)
r.sadd('num16',5,6)
r.smove('num15','num16',1)
print(r.smembers('num16')) #运行结果: {b'1', b'5', b'6'}
#9 spop(name) 从集合的右侧(尾部)移除一个成员,并将其返回
r.sadd('num17',4,5,6)
print(r.spop('num17'))
#10 srandmember(name, numbers) 从name对应的集合中随机获取 numbers 个元素
r.sadd('num18',4,5,6)
print(r.srandmember('num18',2))
#11 srem(name, values) 在name对应的集合中删除某些值
r.sadd('num19',4,5,6)
r.srem('num19',4)
print(r.smembers('num19')) #运行结果: {b'5', b'6'}
#12 sunion(keys, *args) 获取多一个name对应的集合的并集
r.sadd('num20',3,4,5,6)
r.sadd('num21',5,6,7,8)
print(r.sunion('num20','num21')) #运行结果: {b'4', b'5', b'7', b'6', b'8', b'3'}
#13 sunionstore(dest,keys, *args)
# 获取多个name对应的集合的并集,并将结果保存到dest对应的集合中
r.sunionstore('num22','num20','num21')
print(r.smembers('num22')) #运行结果: {b'5', b'7', b'3', b'8', b'6', b'4'}
#14 sscan(name, cursor=0, match=None, count=None)
# sscan_iter(name, match=None, count=None)
#同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
# 2、使用案例
- 去重,利用 sadd 和 scard 命令实现元素的添加和计数
- 交集,并集,差集,利用 sinter,sunion 和 sdiff 命令实现集合间的运算
- 随机抽取,利用 srandmember 命令实现随机抽奖或者抽样
# 05.zset集合
# 5.1 有序集合
有序集合,在集合的基础上,为每元素排序
元素的排序需要根据另外一个值来进行比较
对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序
# 5.2 Redis操作有序集合
import Redis
pool = Redis.ConnectionPool(host='10.1.0.51', port=6379)
r = Redis.Redis(connection_pool=pool)
#1 zadd(name, *args, **kwargs) 在name对应的有序集合中添加元素
r.zadd('zz', n1=11, n2=22,n3=15)
print(r.zrange('zz',0,-1)) #[b'n1', b'n3', b'n2']
print(r.zrange('zz',0,-1,withscores=True)) #[(b'n1', 11.0), (b'n3', 15.0), (b'n2', 22.0)]
#2 zcard(name) 获取name对应的有序集合元素的数量
#3 zcount(name, min, max) 获取name对应的有序集合中分数 在 [min,max] 之间的个数
r.zadd('name01', tom=11,jack=22,fly=15)
print(r.zcount('name01',1,20))
#4 zincrby(name, value, amount) 自增name对应的有序集合的 name 对应的分数
#5 zrank(name, value) 获取某个值在 name对应的有序集合中的排行(从 0 开始)
r.zadd('name02', tom=11,jack=22,fly=15)
print(r.zrank('name02','fly'))
#6 zrem(name, values) 删除name对应的有序集合中值是values的成员
r.zadd('name03', tom=11,jack=22,fly=15)
r.zrem('name03','fly')
print(r.zrange('name03',0,-1)) # [b'tom', b'jack']
#7 zremrangebyrank(name, min, max)根据排行范围删除
r.zadd('name04', tom=11,jack=22,fly=15)
r.zremrangebyrank('name04',1,2)
print(r.zrange('name04',0,-1)) # [b'tom']
#8 zremrangebyscore(name, min, max) 根据分数范围删除
r.zadd('name05', tom=11,jack=22,fly=15)
r.zremrangebyscore('name05',1,20)
print(r.zrange('name05',0,-1))
#9 zremrangebylex(name, min, max) 根据值返回删除
#10 zscore(name, value) 获取name对应有序集合中 value 对应的分数
#11 zinterstore(dest, keys, aggregate=None) #11测试过代码报错,未解决
#获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
r.zadd('name09', tom=11,jack=22,fly=15)
r.zadd('name10', tom=12,jack=23,fly=15)
r.zinterstore('name11',2,'name09','name10')
print(r.zrange('name11',0,-1))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 5.3 有序集合在命令行测试
# 127.0.0.1:6379> zadd name222 11 zhangsan 12 lisi
(integer) 2
# 127.0.0.1:6379> zrange name222 0 -1
1) "zhangsan"
2) "lisi"
# 127.0.0.1:6379> zadd name333 11 zhangsan 12 lisi
(integer) 2
# 127.0.0.1:6379> zrange name333 0 -1
1) "zhangsan"
2) "lisi"
# 127.0.0.1:6379> zinterstore name444 2 name222 name333
(integer) 2
# 127.0.0.1:6379> zrange name444 0 -1 withscores
1) "zhangsan"
2) "22"
3) "lisi"
4) "24"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 5.4 使用案例
# 1、限流
#1)api:limit(有序集合名)
# <当前时间戳> 排序值
# <请求ID> 作为 key
ZADD api:limit <当前时间戳> <请求ID>
#2)删除60秒前的请求记录
ZREMRANGEBYSCORE api:limit 0 <当前时间戳-60秒>
#3)统计当前剩余的请求记录数量
ZCARD api:limit
#4)判断请求记录数量是否超过10,如果超过10,就拒绝当前请求,否则就接受当前请求
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 2、排行榜
- 排行榜,利用 zadd 和 zrange 命令实现分数的更新和排名的查询
# 添加用户的分数
ZADD leaderboard 1500 "John"
ZADD leaderboard 2000 "Tom"
ZADD leaderboard 1800 "Bob"
# 更新用户的分数
ZADD leaderboard 2200 "Tom"
# 查询排行榜
ZRANGE leaderboard 0 -1
# 查询排行榜(包含分数)
ZRANGE leaderboard 0 -1 WITHSCORES
# 查询用户的排名(排名从0开始)
ZRANK leaderboard "Tom"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 3、访问统计
- 访问统计,可以使用 zset 来存储网站或者文章的访问次数,并且可以按照访问量进行排序和筛选
- ZINCRBY和ZRANGE命令可以用来增加访问次数和查询访问统计
# 记录文章的访问次数
ZINCRBY pageview 1 "article1"
# 查询文章的访问次数
# 命令返回了所有文章的访问次数,文章按照访问次数从小到大的顺序排列,并且包含了文章的访问次数
ZRANGE pageview 0 -1 WITHSCORES
# 查询访问次数最多的文章
# 这个命令返回了访问次数最多的文章和它的访问次数
ZREVRANGE pageview 0 0 WITHSCORES
# 查询访问次数在某个范围内的文章
ZRANGEBYSCORE pageview 1000 5000 WITHSCORES
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
# 4、延时队列
- 延时队列,利用 zadd 和 zpopmin 命令实现任务的添加和执行,并且可以定期地获取已经到期的任务
- 我们可以将任务的到期时间设为UNIX时间戳,然后将这个时间戳作为任务的分数
- 当我们获取队列中的任务时,我们只需要比较当前的UNIX时间戳和任务的分数即可判断任务是否到期
# 添加任务到延时队列
# 这个命令将任务"Task1"和"Task2"添加到名为"tasks"的延时队列中,任务的过期时间为UNIX时间戳
ZADD tasks 1632892800 "Task1"
ZADD tasks 1632979200 "Task2"
# 获取队列中的所有任务(这个命令返回队列中的所有任务和它们的到期时间)
ZRANGE tasks 0 -1 WITHSCORES
# 获取并移除已经到期的任务
ZPOPMIN tasks
# 这个命令返回并移除延时队列中分数值最小的元素,也就是最早到期的任务
# 如果队列为空,或者没有已经到期的任务,这个命令会返回空
# 可以设置一个定时器,每隔一段时间执行一次ZPOPMIN命令,获取并处理已经到期的任务
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
使用 Python 定期清理过期任务
- 在应用程序中定期地获取并处理到期的任务
- 我们可以设置一个定时器,每隔一段时间执行一次以下的操作
- a. 获取当前的UNIX时间戳
- b. 使用ZRANGEBYSCORE命令获取所有到期的任务,即分数小于或等于当前UNIX时间戳的任务
- c. 处理获取到的任务
- d. 使用ZREM命令移除处理过的任务
- 这个程序会每秒钟检查一次是否有到期的任务,如果有的话就处理并移除这些任务
import time
import Redis
r = Redis.Redis(host='localhost', port=6379, db=0)
while True:
# 获取当前的UNIX时间戳
now = time.time()
# 获取所有到期的任务
tasks = r.zrangebyscore('tasks', '-inf', now)
for task in tasks:
# 处理任务
print('Processing task: ', task)
# 移除处理过的任务
r.zrem('tasks', task)
# 每隔一段时间执行一次
time.sleep(1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 06.bitmap
# 1、常用命令
#1)将 mykey 的第 7 位设置为 1
SETBIT mykey 7 1
#2)获取 mykey 的第 7 位的值
GETBIT mykey 7
#3)统计 mykey 第 0 到第 1 位中,值为 10 的二进制位的数量
BITCOUNT mykey 0 10
#4)返回 mykey 中第一个值为 1 的二进制位的位置
BITPOS mykey 1
#5)对 mykey1 和 mykey2 进行位与操作,并将结果保存到 destkey 上
BITOP AND destkey mykey1 mykey2
#6)将 mykey 的第 100 位开始的连续 5 位看作一个有符号整数,增加它的值为 1,并返回第 0 位开始的连续 4 位看作一个无符号整数的值
BITFIELD mykey INCRBY i5 100 1 GET u4 0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 2、布隆过滤器
- Redis 的 bitmap 数据类型通常可以用来实现布隆过滤器
- 布隆过滤器是一种空间效率极高的概率型数据结构,用于检测一个元素是否在一个集合中
- 假设我们有一个新闻网站,每天都有很多新闻发布
- 我们想记录用户看过哪些新闻,以便为用户推荐他们可能感兴趣的新闻
- 假设我们有一个新闻,ID 是 123456,我们可以使用多个 hash 函数将新闻 ID 映射到 bitmap 的不同位置
# 我们可以使用三个 hash 函数 h1, h2, h3,然后用以下命令将新闻 ID 添加到布隆过滤器中
SETBIT bloomfilter:h1 123456 1
SETBIT bloomfilter:h2 123456 1
SETBIT bloomfilter:h3 123456 1
# 检查用户是否看过 ID 为 123456 的新闻,我们可以用以下命令
GETBIT bloomfilter:h1 123456
GETBIT bloomfilter:h2 123456
GETBIT bloomfilter:h3 123456
# 以上命令会返回三个结果,如果三个结果都为 1,那么说明用户可能看过这个新闻
# 如果有任何一个结果为 0,那么说明用户肯定没有看过这个新闻
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
- 布隆过滤器有一定的误报率,也就是说,即使三个结果都为 1
- 也只能说用户可能看过这个新闻,不能确定用户一定看过这个新闻
- 但是如果有任何一个结果为 0,那么我们可以确定用户肯定没有看过这个新闻
go演示布隆过滤器
package main
import (
"fmt"
"github.com/go-Redis/Redis"
"hash/fnv"
)
var client *Redis.Client
// init 初始化 Redis 连接
func init() {
client = Redis.NewClient(&Redis.Options{
Addr: "localhost:6379",
Password: "", // no password set
DB: 0, // use default DB
})
}
// hash hash函数计算 bitmap 要存放的位置
func hash(s string, i int) uint32 {
h := fnv.New32a()
h.Write([]byte(s))
return h.Sum32() + uint32(i)
}
// add 将 key添加到布隆过滤器
func add(s string) {
for i := 0; i < 3; i++ {
offset := hash(s, i)
client.SetBit("bloomfilter", int64(offset), 1)
}
}
// exists 判断当前 key 在布隆过滤器中是否都有 1 的占位
func exists(s string) bool {
for i := 0; i < 3; i++ {
offset := hash(s, i)
bit := client.GetBit("bloomfilter", int64(offset))
if bit.Val() == 0 {
return false
}
}
return true
}
func main() {
add("item1")
add("item2")
fmt.Println(exists("item1")) // should print: true
fmt.Println(exists("item3")) // should print: false
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 3、统计活跃用户
- 假设我们有一个社交网络网站,我们想要统计每天的活跃用户数量
# 用户 ID=10 的用户在20211201访问了网站
SETBIT daily_active_users:20211201 10 1
# 返回20211201活跃用户量
BITCOUNT daily_active_users:20211201
# 统计某一个时间段内的活跃用户数量,我们可以使用 BITOP 命令将多个 bitmap 进行 OR 操作
BITOP OR active_users:20211201-20211207 daily_active_users:20211201 daily_active_users:20211202 daily_active_users:20211203 daily_active_users:20211204 daily_active_users:20211205 daily_active_users:20211206 daily_active_users:20211207
# 下面命令返回20211201-20211207的活跃用户数量
BITCOUNT active_users:20211201-20211207
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 4、预定
Redis bitmap 方案描述
- 如果选择不加分布式锁的前提下可以使用 Redis bitmap 来存储车辆预定情况
- 每个车唯一名称对应一个 bitmap,以小时为单位,预定为 1,未预定为 0
- 比如开始时间为2024年1月1日00:00:00为起始时间
预热
- 预定只能预定当前时间往后的数据,所以我们只需要到数据库查询
预定时间 > 当天零点的数据来初始化
- 预定只能预定当前时间往后的数据,所以我们只需要到数据库查询
数据准确性
- 页面显示数据可以使用 MySQL 中数据即可,写入已 Redis bitmap 为准
批量设置为 1(会议预定)
// 使用 BITCOUNT 命令来获取给定范围内的 1 的数量
count, _ := client.BitCount("meeting_room:1", &Redis.BitCount{startOffset, endOffset}).Result()
// 如果给定范围内的 1 的数量为 0,即给定范围内全是 0
if count == 0 {
// 使用 SETBIT 命令来将给定范围内的位全部设置为 1
pipe := client.Pipeline()
for i := startOffset * 8; i < endOffset * 8; i++ {
pipe.SetBit("meeting_room:1", int64(i), 1)
}
_, err := pipe.Exec()
}
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
- 预定、取消 等相关命令
# 检查2024年1月1日10:00:00是否已经被预定(如果返回1,那么会议室已经被预定,如果返回0,那么会议室没有被预定)
GETBIT meeting_room:1 10
# 预定会议室,在2024年1月1日10:00:00预定会议室
SETBIT meeting_room:1 10 1
# 取消预定,消2024年1月1日10:00:00的预定
SETBIT meeting_room:1 10 0
# 查询一个范围内是否全是 1
BITCOUNT meeting_room:1 3 7
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
上次更新: 2024/10/15 16:27:13