 07.binlog redolog undolog ✅
07.binlog redolog undolog ✅
# 00.介绍
# 1、三种日志作用
Redo Log + Undo Log 一起保障一致性:
Undo Log:在事务失败或用户
主动回滚时,用于撤销未提交的变更 → 保证原子性Redo Log:在系统崩溃时,用于
重放已提交事务的变更 → 保证持久性
1、二进制日志(Binlog)
- 用途: Binlog主要用于
MySQL中的复制,基于时间点的数据恢复 - 内容: 更改操作(如 INSERT、UPDATE、DELETE),记录的是逻辑SQL语句
2、重做日志(Redo Log)
- 用途: 保证事务的
持久性,用于崩溃恢复和确保数据持久性 - 内容: 记录了一个事务修改了那些磁盘,分别修改了那些字段那些值信息
- 解决问题: update 可能更改了多个磁盘区域的数据,数据刷到磁盘的每个扇区里无法保证原子性
3、撤销日志(Undo Log)
用途:
- 实现事务的
原子性 和 隔离性,支持回滚未提交事务 - 实现多版本并发控制(MVCC),支持快照读
- 实现事务的
撤销日志用于存储
事务修改的数据的先前图像,使回滚成为可能,确保事务一致性内容: 记录当前事务没有修改前原始数据是什么,以便回滚时恢复原始数据
# 2、MySQL预写机制
- 预写日志机制是一种数据库事务日志技术,数据库修改被写入到永久存储(也就是磁盘)之前,先将这些修改记录到日志中
- 这样当 MySQL 遇到意外的断电情况时,它会在重启后,如何保证一致性和原子性
- 利用
Redo log 来恢复已提交但未写入数据文件的事务继续写入数据文件,从而保证一致性 - 再利用
undo log 来撤销未提交事务的需改,从而保证原子性
# 01.binlog二进制日志
# 1、binlog 设计目标
binlog 记录了对 MySQL 数据库执行更改的所有的写操作,包括所有对数据库的数据、表结构、索引等等变更的操作。
可以把数据库的数据看做银行账户里的余额,而 binlog 就相当于我们银行卡的流水记录。
账户余额只是一个结果,至于这个结果怎么来的,那就必须得看流水了。
在实际应用中, binlog 的主要应用场景分别是 主从复制 和 数据恢复。
主从复制 :在 Master 端开启 binlog ,然后将 binlog 发送到各个 Slave 端, Slave 端重放 binlog 来达到主从数据一致。
数据恢复 :通过使用 MySQLbinlog 工具来恢复数据。
# 2、binlog 数据格式
binlog 日志有三种格式,分别为 STATMENT 、 ROW 和 MIXED。
在 MySQL 5.7.7 之前,默认的格式是 STATEMENT ,
MySQL 5.7.7 之后,默认值是 ROWROW:基于行的复制(row-based replication, RBR)
记录表的每行变更记录,update 语句修改一百行数据,就会
记录 100 行对应的记录日志优点:对于一些特殊函数可以正确复制缺点:会产生大量的日志,尤其是 alter table 的时候会让日志暴涨
STATMENT:基于 SQL 语句的复制( statement-based replication, SBR )
每一条会修改数据的 SQL 语句会记录到 binlog 中 , 避免着大量的 IO 操作。
优点:不需要记录每一行的变化,
减少了 binlog 日志量,节约了 IO, 从而提高了性能;缺点:在某些情况下
会导致主从数据不一致,比如执行 sysdate() 、 slepp() 等 。
MIXED:基于 STATMENT 和 ROW 两种模式的混合复制(mixed-based replication, MBR)
- 一般的复制使用 STATEMENT 模式保存 binlog ,对于一些函数,STATEMENT 模式无法复制的操作使用 ROW 模式保存 binlog。
三种模式特点使用 row 格式的 binlog 时,在进行数据同步或恢复的时候不一致的问题更容易被发现,因为它是基于数据行记录的。
使用 mixed 或者 statement 格式的 binlog 时,数据同步或恢复的时候就容易出现不一致的情况。
# 3、binlog 写入策略
对于 InnoDB 存储引擎而言,在进行事务的过程中,首先会把 binlog 写入到 binlog cache 中
只有在事务提交时才会记录 biglog ,此时记录还在内存中,那么 biglog 是什么时候刷到磁盘中的呢?
0:每次提交事务 binlog先写到 page cache,由系统判断何时写入磁盘,崩溃时有丢失日志风险
1:每次提交事务都会执行 fsync 将 binlog 写入到磁盘;
N:每次提交事务先写到 page cach,只有等到积累了 N 个事务之后才 fsync 将 binlog 写入到磁盘,有丢失 N 个事务日志的风险
sync_binlog=1 是强一致的选择,选择 0 或者 N 的情况下在极端情况下就会有丢失日志的风险
# 02.redo log重做日志
# 1、redo log 设计目标
- redo log 是属于引擎层(innodb)的日志,称为
重做日志 - 当 MySQL 服务器意外崩溃或者宕机后,
保证已经提交的事务持久化到磁盘中(持久性) - 它能保证对于已经 COMMIT 的事务产生的数据变更,即使是系统宕机崩溃也可以通过它来进行数据重做
# 2、redo log 包括两部分
内存中的日志缓冲(redo log buffer)
- 内存层面,默认 16M,通过 innodb_log_buffer_size 参数可修改
磁盘上的日志文件(redo logfile)
- 持久化的,磁盘层面
MySQL 每执行一条 DML 语句,先将记录写入 redo log buffer,后续某个时间点再一次性将多个操作记录写到 redo log file
# 3、redo log 几点疑惑
Q1:为什么不直接修改磁盘中的数据?
因为直接修改磁盘数据的话,它是随机 IO,修改的数据分布在磁盘中不同的位置,需要来回的查找
以一定的频率去刷新磁盘可以降低随机 IO 的频率,增加吞吐量,这是使用 buffer pool 的根本原因
Q2:同为操作数据变更的日志,有了 binlog 为什么还要 redo log?
- 最核心的一点就是两者记录的数据变更粒度是不一样的。
- update 可能更改了多个磁盘区域的数据,数据刷到磁盘的每个扇区里无法保证原子性
- 如果数据库宕机,那么就可能会造成一部分数据成功,而一部分数据失败的情况
- 所以这个时候得需要通过 redo log 这种记录到磁盘数据级别的日志进行数据恢复
Q3: redo log到底存的什么内容
物理修改: 重做日志记录了对数据库页的物理修改,包括
哪些数据页发生了变化以及发生了什么样的变化事务标识: 重做日志中包含了与
事务相关的标识,确保对数据库的修改可以按照事务的顺序进行重放变更的类型: 记录了每个事务
对数据库的具体修改类型,例如插入、更新或删除数据变更前后的值: 对于更新和删除操作,记录了
变更前后的数据值,以便在恢复时能够正确地重做这些操作持久性保证: 由于重做日志的内容会被立即写入到磁盘,它确保了已提交的事务在发生崩溃时可以被恢复,从而保证数据库的持久性
Q4:redo log 一定能保证事务的持久性吗?
不一定,这要根据 redo log 的刷盘策略决定,因为 redo log buffer 同样是在内存中
如果提交事务之后,redo log buffer 还没来得及将数据刷新到 redo log file 进行持久化,此时发生宕机照样会丢失数据
那该如何解决呢?刷盘写入策略。
# 4、redo log 写入策略
- 0(延迟写):表示每次事务提交时都只是把 redo log 留在 redo log buffer 中,开启一个后台线程,每 1s 刷新一次到磁盘中
- 1(实时写,实时刷):表示每次事务提交时都将 redo log 直接持久化到磁盘,真正保证数据的持久性
- 2(实时写,延迟刷):表示每次事务提交时都只是把 redo log 写到 page cache,具体的刷盘时机不确定
还有其它两种情况会把 redo log buffer 中的日志刷到磁盘
定时处理:有线程会定时(每隔 1 秒)把 redo log buffer 中的数据刷盘
根据空间处理:redo log buffer 占用到了一定程度( innodb_log_buffer_size 设置的值一半)
# 03.undo log撤销日志
# 1、undo log 设计目标
redo log 和 undo log 的核心是为了保证 innodb 事务机制中的
持久性和原子性事务提交成功由 redo log 保证数据持久性,而
事务可以进行回滚从而保证事务操作原子性则是通过 undo log 来保证的。事务回滚 :
- 前面提到过,后台线程会不定时的去刷新 buffer pool 中的数据到磁盘
- 但是如果该事务执行期间出现各种错误(宕机)或者执行 rollback 语句
- 那么前面刷进去的操作都是需要回滚的,保证原子性,undo log 就是提供事务回滚的
MVCC:
- 当读取的某一行被其他事务锁定时,可以从 undo log 中分析出该行记录以前的数据版本是怎样的
- 从而让用户能够读取到当前事务操作之前的数据——快照读
# 2、undo log 两类数据
insert undo log
- insert 操作的记录,只对事务本身可见,对其他事务不可见(这是事务隔离性的要求)
- 故该 undo log 可以在事务提交后直接删除,不需要进行 purge 操作
update undo log
- update undo log 记录的是对 delete 和 update 操作产生的 undo log
- 该 undo log 可能需要提供 MVCC 机制,因此不能在事务提交时就进行删除
- 提交时放入 undo log 链表,等待 purge 线程进行最后的删除
# 3、undo log 操作实例
1、首先准备一张表(user_info)
- DB_ROW_ID∶记录的主键 id
- DB_TRX_ID:事务 ID,当对某条记录发生修改时,就会将这个事务的 Id 记录其中
- DB_ROLL_PTR︰回滚指针,版本链中的指针
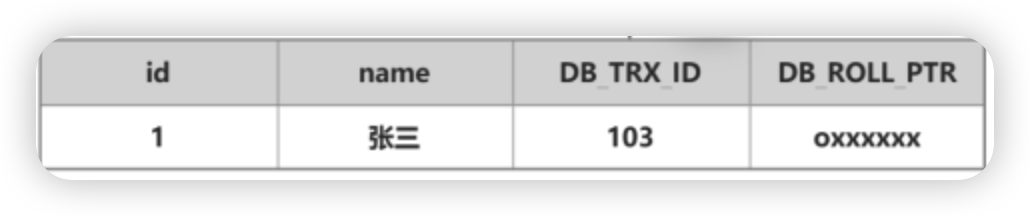
2、开启一个事务 A
update user_info set name ="李四" where id=1
1)首先
获得一个事务编号 1042)把 user_info 表修改前的数据拷贝到 undo log
3)修改 user_info 表 id=1 的数据
4)
把修改后的数据事务版本号改成 当前事务版本号,并把 DB_ROLL_PTR 地址指向 undo log 数据地址
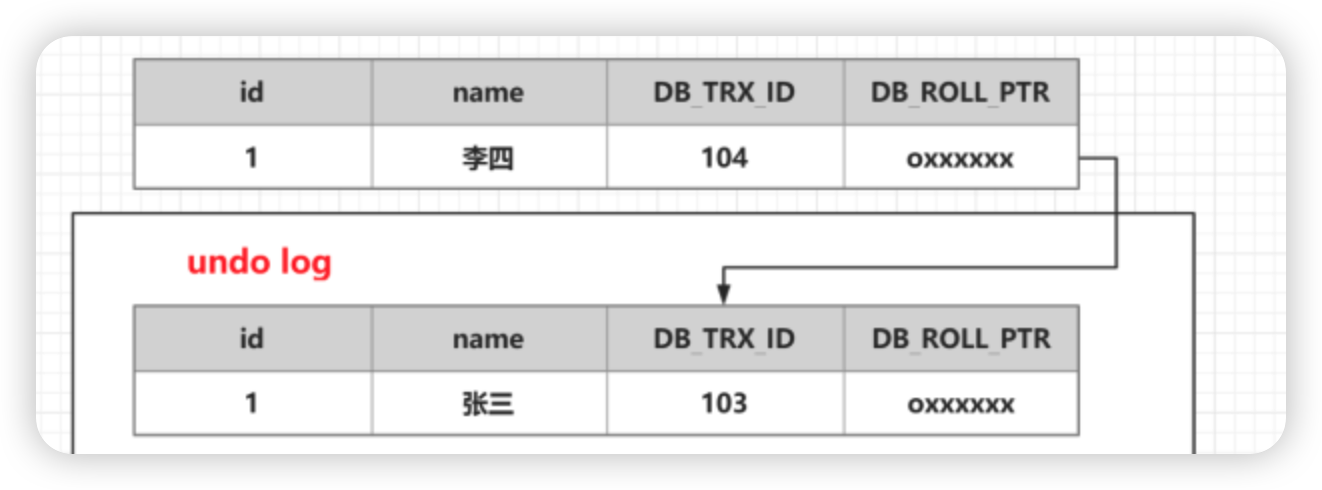
3、undo log回归原理
- 每次对数据的变更都会产生一个 undo log,当一条记录被变更多次时,那么就会产生多条 undo log
- undo log 记录的是变更前的日志,并且每个 undo log 的序号是递增的
- 那么当要回滚的时候,按照序号依次向前推,就可以找到我们的原始数据了