101.ES同步
101.ES同步
# 01.MySQL数据同步到ES
# 1.1 同步类型
- MySQL数据同步到ES中分为两种,分别是全量同步和增量同步。
- 全量同步表示第一次建立好ES索引之后,将MySQL中所有数据一次性导入到ES中。
- 增量同步表示MySQL中产生新的数据,这些新的数据包括三种情况
- 新插入MySQL中的数据
- 更新老的数据
- 删除的数据
- 这些数据的变动与新增都要同步到ES中。
# 1.2 数据同步实现方式
业界有一些开源方案,开源中间件来实现
-
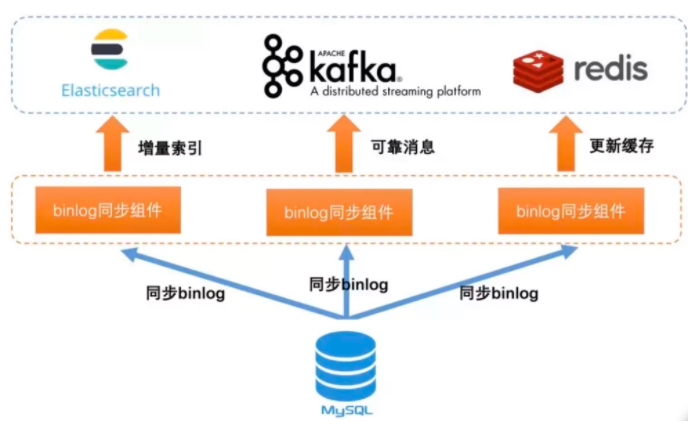
- 基于MySQL的binlog日志订阅:binlog日志是MySQL用来记录数据实时的变化。
- 这里主要的是binlog同步组件,目前实现的有国内的阿里巴巴开发的canal
方法2:go-MySQL-elasticsearch
- 就是这样一个项目,它可以从 MySQL 的数据表中读取指定数据表的数据,发送到 ElasticSearch 之中。
- 它会使用
MySQLdump命令处理现有存量数据,并借助 binlog 的方式跟踪增量数据 - 从而保证 Elasticsearch 的数据和 MySQL 数据库中的数据保持同步。
# 02.canal实现方案
# 2.1 canal是什么
- 我们都知道一个系统最重要的是数据,数据是保存在数据库里。
- 但是很多时候不单止要保存在数据库中,还要同步保存到Elastic Search、HBase、Redis等等
- 阿里开源的框架Canal,他可以很方便地同步数据库的增量数据到其他的存储应用
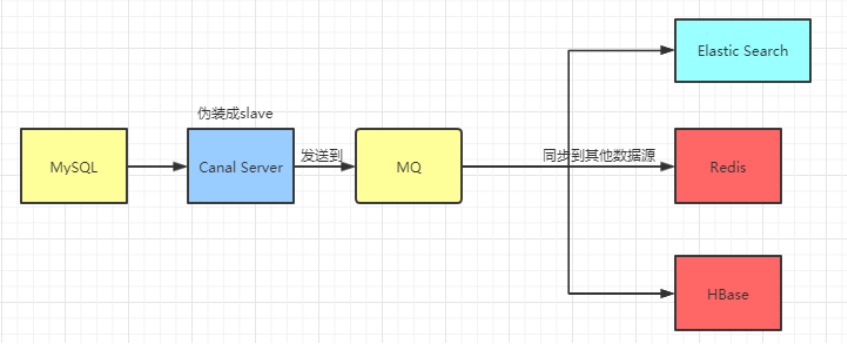
# 2.2 canel原理
- canal的工作原理就是把自己伪装成MySQL slave
- 1) 模拟MySQL slave的交互协议向MySQL Mater发送 dump协议
- 2) MySQL mater收到canal发送过来的dump请求,开始推送binary log给canal
- 3) 然后canal解析binary log,再发送到存储目的地,比如MySQL,Kafka,Elastic Search等等
# 03.搭建canal
# 3.1 安装MySQL与基本配置
# 3.1.1 安装MySQL
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
我的Linux服务器安装的MySQL服务器是5.7版本。
MySQL的安装这里就不演示了,比较简单,网上也有很多教程。
# 3.1.2 创建MySQL用户
# 创建用户 用户名:canal 密码:Canal@123456
create user 'canal'@'%' identified by 'Canal@123456';
# 授权 *.*表示所有库
grant SELECT, REPLICATION SLAVE, REPLICATION CLIENT on *.* to 'canal'@'%' identified by 'Canal@123456';
FLUSH PRIVILEGES;
2
3
4
5
# 3.1.3 配置文件my.cnf
[MySQLd]
log-bin=MySQL-bin #添加这一行就ok
binlog-format=ROW #选择row模式
server_id=129 #配置MySQL replaction需要定义,不能和canal的slaveId重复
2
3
4
# 3.1.4 确定执行状态
- 重启MySQL
- 确定打开了打开binlog模式
MySQL> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
2
3
4
5
6
MySQL> show binary logs; # 查看binlog日志文件列表
MySQL> show master status; # 查看当前正在写入的binlog文件
2
# 3.2 安装canal
# 3.2.1 下载并解压 canal
- 进入官网
去官网下载页面进行下载:https://github.com/alibaba/canal/releases (opens new window)
- 下载并解压
[root@localhost ~]# cd /usr/local/src/
[root@localhost src]# wget https://github.com/alibaba/canal/releases/download/canal-1.0.19/canal.deployer-1.0.19.tar.gz
[root@localhost src]# mkdir /usr/local/canal
[root@localhost src]# tar zxvf canal.deployer-1.0.19.tar.gz -C /usr/local/canal/
2
3
4
5
- 可以看到如下结构
[root@localhost src]# cd ..
[root@localhost local]# cd /usr/local/canal/
[root@localhost canal]# ls
bin conf lib logs
2
3
4
# 3.2.2 配置修改
- 修改conf/example/instance.properties
[root@localhost canal]# vim conf/example/instance.properties
# 第一:MySQL serverId,改成唯一的
canal.instance.MySQL.slaveId = 129
# 第二:position info,需要改成自己的数据库信息
canal.instance.master.address=127.0.0.1:3306 # 数据库地址
canal.instance.master.journal.name=MySQL-bin.000001 # binlog日志名称
canal.instance.master.position=154 # MySQL主库链接时起始的binlog偏移量
canal.instance.master.timestamp= # MySQL主库链接时起始的binlog的时间戳
# 第三:username/password,需要改成自己的数据库信息
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.defaultDatabaseName=test
canal.instance.connectionCharset=UTF-8
# 第四:table regex
canal.instance.filter.regex=.*\\..*
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- 修改 conf/canal.properties 文件
- 将 canal.ip 改成canal所在机器的ip地址,避免无谓的问题
canal.id= 128
canal.ip=192.168.134.128
canal.port= 11111
2
3
# 3.2.3 准备启动
[root@localhost canal]# ./bin/startup.sh
- linux启动完成后,会在bin目录下生成canal.pid,stop.sh会读取canal.pid进行进程关闭;
- startup.sh默认读取系统环境变量中的which java获得JAVA执行路径,需要设置PATH=$JAVA_HOME/bin环境变量。
# 3.2.4 查看日志
[root@localhost canal]# vim logs/canal/canal.log
[root@localhost canal]# vim logs/example/example.log
2
# 3.2.5 关闭
[root@localhost canal]# ./bin/stop.sh
localhost.localdomain: stopping canal 6237 ...
2
# 04.canel客户端
# 4.1 canal-python 简介
canal-python 是阿里巴巴开源项目 Canal (opens new window)是阿里巴巴MySQL数据库binlog的增量订阅&消费组件 的 python 客户端。
为 python 开发者提供一个更友好的使用 Canal 的方式。
Canal 是MySQL数据库binlog的增量订阅&消费组件。
基于日志增量订阅&消费支持的业务:
- 1)数据库镜像
- 2)数据库实时备份
- 3)多级索引 (卖家和买家各自分库索引)
- 4)search build
- 5)业务cache刷新
- 6)价格变化等重要业务消息
# 4.2 应用场景
1.代替使用轮询数据库方式来监控数据库变更,有效改善轮询耗费数据库资源。
2.根据数据库的变更实时更新搜索引擎,比如电商场景下商品信息发生变更,实时同步到商品搜索引擎 Elasticsearch、solr等
3.根据数据库的变更实时更新缓存,比如电商场景下商品价格、库存发生变更实时同步到Redis
4.数据库异地备份、数据同步
5.根据数据库变更触发某种业务,比如电商场景下,创建订单超过xx时间未支付被自动取消,我们获取到这条订单数据的状态变更即可向用户推送消息。
6.将数据库变更整理成自己的数据格式发送到kafka等消息队列,供消息队列的消费者进行消费。
# 4.3 工作原理
- canal-python 是 Canal 的 python 客户端
- 它与 Canal 是采用的Socket来进行通信的,传输协议是TCP
- 交互协议采用的是 Google Protocol Buffer 3.0
# 4.4 工作流程
1.Canal连接到MySQL数据库,模拟slave
2.canal-python 与 Canal 建立连接
2.数据库发生变更写入到binlog
5.Canal向数据库发送dump请求,获取binlog并解析
4.canal-python 向 Canal 请求数据库变更
4.Canal 发送解析后的数据给canal-python
5.canal-python收到数据,消费成功,发送回执。(可选)
6.Canal记录消费位置。
# 4.5 快速启动
安装Canal
- Canal 的安装以及配置使用请查看 https://github.com/alibaba/canal/wiki/QuickStart
环境要求
- python >= 3
构建canal python客户端
pip install canal-python
- 建立与Canal的连接
import time
from canal.client import Client
from canal.protocol import EntryProtocol_pb2
from canal.protocol import CanalProtocol_pb2
client = Client()
client.connect(host='127.0.0.1', port=11111)
client.check_valid(username=b'', password=b'')
client.subscribe(client_id=b'1001', destination=b'example', filter=b'.*\\..*')
while True:
message = client.get(100)
entries = message['entries']
for entry in entries:
entry_type = entry.entryType
if entry_type in [EntryProtocol_pb2.EntryType.TRANSACTIONBEGIN, EntryProtocol_pb2.EntryType.TRANSACTIONEND]:
continue
row_change = EntryProtocol_pb2.RowChange()
row_change.MergeFromString(entry.storeValue)
event_type = row_change.eventType
header = entry.header
database = header.schemaName
table = header.tableName
event_type = header.eventType
for row in row_change.rowDatas:
format_data = dict()
if event_type == EntryProtocol_pb2.EventType.DELETE:
for column in row.beforeColumns:
format_data = {
column.name: column.value
}
elif event_type == EntryProtocol_pb2.EventType.INSERT:
for column in row.afterColumns:
format_data = {
column.name: column.value
}
else:
format_data['before'] = format_data['after'] = dict()
for column in row.beforeColumns:
format_data['before'][column.name] = column.value
for column in row.afterColumns:
format_data['after'][column.name] = column.value
data = dict(
db=database,
table=table,
event_type=event_type,
data=format_data,
)
print(data)
time.sleep(1)
client.disconnect()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 05.总结
canal的好处在于对业务代码没有侵入,因为是基于监听binlog日志去进行同步数据的。
实时性也能做到准实时,其实是很多企业一种比较常见的数据同步的方案。
通过上面的学习之后,我们应该都明白canal是什么,它的原理,还有用法
实际上这仅仅只是入门,因为实际项目中我们不是这样玩的...
实际项目我们是配置MQ模式,配合RocketMQ或者Kafka
canal会把数据发送到MQ的topic中,然后通过消息队列的消费者进行处理
Canal的部署也是支持集群的,需要配合ZooKeeper进行集群管理
Canal还有一个简单的Web管理界面