 20.回归
20.回归
# 01.线性回归
线性回归输出是一个连续值,因此适用于回归问题
回归问题在实际中很常见,如预测房屋价格、气温、销售额等连续值的问题
我们首先以线性回归为例,介绍大多数深度学习模型的基本要素和表示方法
# 1、模型
房价预测说明我们以一个简单的房屋价格预测作为例子来解释线性回归的基本要素
这个应用的目标是预测一栋房子的售出价格(元)
我们知道这个价格取决于很多因素,如房屋状况、地段、市场行情等
为了简单起见,这里我们假设价格只取决于房屋状况的两个因素,即面积(平方米)和房龄(年)
接下来我们希望探索价格与这两个因素的具体关系
模型- 设房屋的面积为 x1,房龄为 x2 , 售出价格为y
- 我们需要建立基于输入 x1 和 x2 来计算输出y的表达式,也就是模型(model)
- 顾名思义,
线性回归假设输出与各个输入之间是线性关系 - y^ = x1w1 + x2w2 + b
- 其中 w1 和 w2 是权重(weight),b是偏差(bias),且均为标量
- 它们是线性回归模型的参数(parameter)
- 模型输出 y^ 是线性回归对真实价格
y的预测或估计 - 我们通常允许它们之间有一定误差
# 2、模型训练
- 接下来我们需要
通过数据来寻找特定的模型参数值,使模型在数据上的误差尽可能小 - 这个过程叫作模型训练,下面我们介绍模型训练所涉及的3个要素
# 1)训练数据
- 我们通常收集一系列的真实数据,例如多栋房屋的真实售出价格和它们对应的面积和房龄
- 我们希望在这个数据上面寻找模型参数来使模型的预测价格与真实价格的误差最小
- 在机器学习术语里,该数据集被称为
训练数据集或训练集 一栋房屋被称为一个样本(sample),其真实售出价格叫作标签(label),用来预测标签的两个因素叫作特征(feature)

# 2)损失函数
- 在模型训练中,我们需要衡量价格预测值与真实值之间的误差
通常我们会选取一个非负数作为误差,且数值越小表示误差越小- 一个常用的选择是平方函数,常数1/2使对平方项求导后的常数系数为1,这样在形式上稍微简单一些
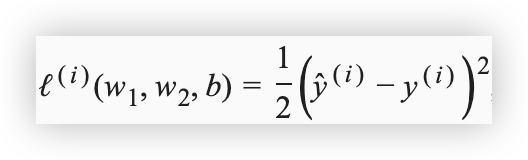
- 在机器学习里,
将衡量误差的函数称为损失函数,这里使用的平方误差函数也称为平方损失

- 在模型训练中,我们希望找出一组模型参数,记为 w1, w2, b,来使训练样本平均损失最小
# 3)优化算法
解析解当模型和损失函数形式较为简单时,上面的误差最小化问题的解
可以直接用公式表达出来这类解叫作解析解,线性回归和平方误差刚好属于这个范畴
数值解然而,大多数深度学习模型并没有解析解,
只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值这类解叫作数值解,在求数值解的优化算法中,
小批量随机梯度下降它的算法很简单:先选取一组模型参数的初始值,如随机选取
接下来对参数进行多次迭代,使
每次迭代都可能降低损失函数的值
# 3、代码实现
import torch
import torch.nn as nn
import torch.optim as optim
# 设置随机种子,保证结果可复现
torch.manual_seed(42)
# 生成模拟数据(面积,房龄 -> 价格)
n_samples = 100 # 样本数量
area = torch.randint(50, 200, (n_samples, 1), dtype=torch.float32) # 面积 50-200 平方米
age = torch.randint(1, 50, (n_samples, 1), dtype=torch.float32) # 房龄 1-50 年
# 假设真实房价计算公式: price = 5000 * area - 3000 * age + 噪声
# 这里的系数 5000 和 -3000 是人为设定的,模拟房价与面积和房龄的线性关系
price = 5000 * area - 3000 * age + torch.randn(n_samples, 1) * 10000 # 价格(带噪声)
# 组织成特征和标签
X = torch.cat([area, age], dim=1) # 特征矩阵,包含面积和房龄
y = price # 目标值(房价)
# 定义线性回归模型
class LinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(2, 1) # 线性层:输入两个特征,输出一个值
def forward(self, x):
return self.linear(x) # 前向传播:线性变换
# 初始化模型、损失函数和优化器
model = LinearRegressionModel()
criterion = nn.MSELoss() # 使用均方误差(MSE)作为损失函数
optimizer = optim.SGD(model.parameters(), lr=1e-6) # 随机梯度下降优化器,学习率设为 1e-6
# 训练模型
epochs = 1000 # 训练轮数
for epoch in range(epochs):
optimizer.zero_grad() # 清空梯度
predictions = model(X) # 前向传播,计算预测值
loss = criterion(predictions, y) # 计算损失(预测值与真实值的误差)
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
if (epoch + 1) % 100 == 0: # 每 100 轮输出一次损失
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.2f}')
# 测试预测
sample = torch.tensor([[120, 10]], dtype=torch.float32) # 预测面积 120 平方米,房龄 10 年的价格
predicted_price = model(sample).item() # 获取模型预测的价格
print(f'预测价格: {predicted_price:.2f} 元')
# 预测合理性解释:
# 1. 训练数据模拟了价格与面积、房龄的线性关系。
# 2. 通过训练,模型学习到面积和房龄对价格的影响。
# 3. 由于训练时加入了噪声,模型不会完全拟合数据,而是学习大致趋势。
# 4. 线性回归本身适用于这种简单的线性关系场景,因此预测结果是合理的。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# 02.softmax回归
# 1、分类问题
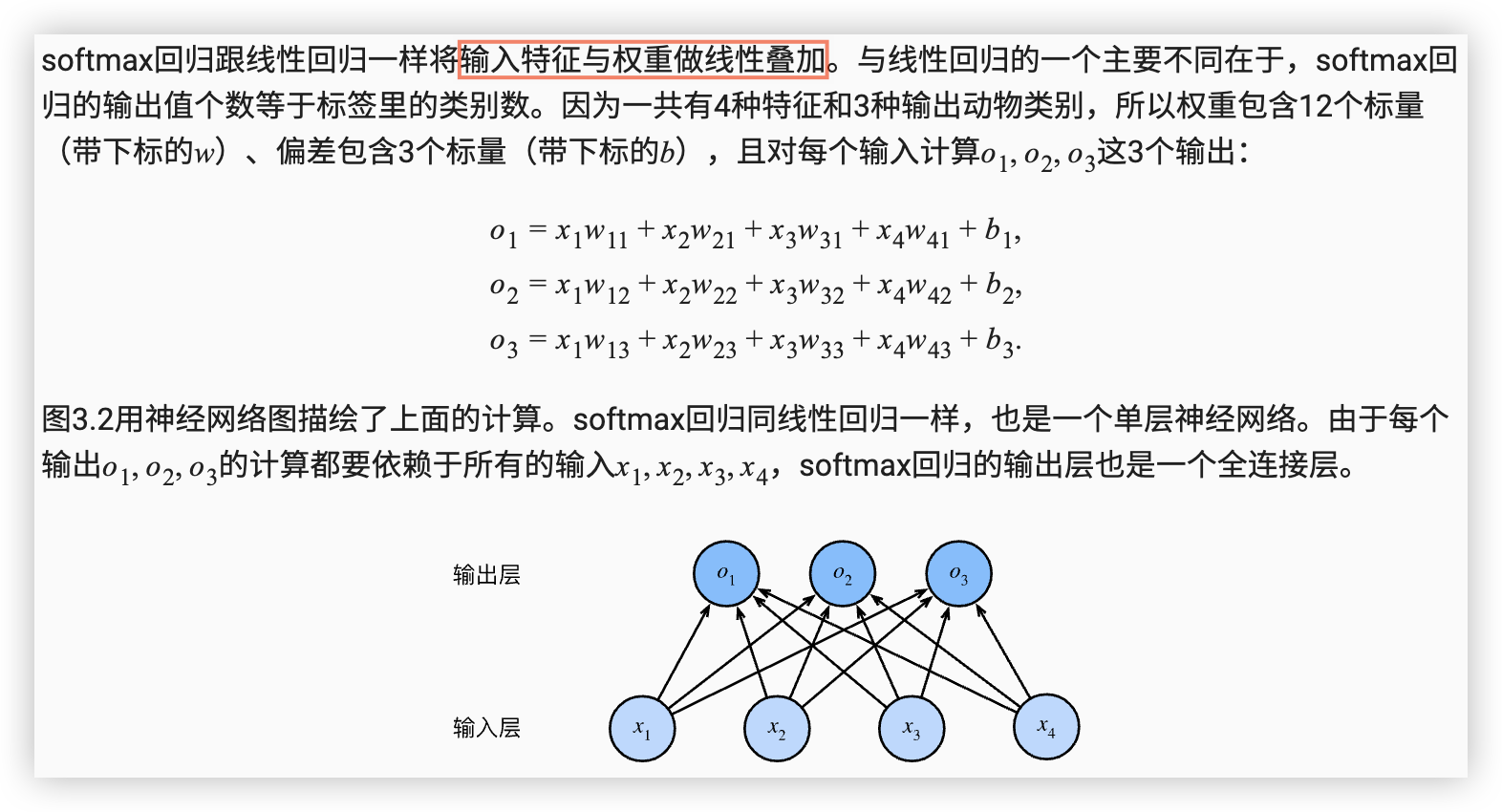
让我们考虑一个简单的图像分类问题,其输入
图像的高和宽均为2像素,且色彩为灰度这样
每个像素值都可以用一个标量表示,我们将图像中的4像素分别记为 x1, x2,x3,x4假设训练数据集中图像的真实标签为狗、猫或鸡(假设可以用4像素表示出这3种动物),这些标签分别对应离散值 y1,y2,y3
我们通常使用离散的数值来表示类别,例如 y1=1, y2=2, y3=3
如此,一张图像的标签为1、2和3,这3个数值中的一个
softmax回归模型
# 2、softmax运算
- Softmax 是一种常
用于分类任务的数学函数,它可以将任意的实数向量转换为概率分布 - 主要用于多分类问题的输出层,使得
所有类别的输出值转换为 0 到 1 之间的概率,并且所有类别的概率总和为 1
Softmax 公式

Softmax 示例计算

# 3、交叉熵损失函数
如果预测概率与真实类别的概率非常接近,则损失较小(更准确)
如果预测概率偏离真实类别概率较远,则损失较大(更不准确)
交叉熵的数学公式如下

假设有 3 个类别的分类任务
