01.GMP模型 ✅核心原理
01.GMP模型 ✅核心原理
早期操作系统为单进程架构,进程串行执行,造成低效。
多进程/线程操作系统改进了并发能力,但带来高内存占用和调度开销问题。
Go语言引入了轻量级的Goroutine,一个goroutine仅占几KB内存,并由用户态调度协作式执行。
Go采用GMP模型:G代表goroutine,M代表线程,P代表调度器。
P的数量与CPU核数匹配,通过全局队列、局部队列和偷取机制调度goroutine,减少调度开销,实现高效并发。
# 01.线程调度
# 1、早期单线程操作系统
一切的软件都是跑在操作系统上,真正用来干活(计算)的是CPU
早期的操作系统每个程序就是一个进程,直到一个程序运行完,才能进行下一个进程,就是“单进程时代”
一切的程序只能串行发生
# 2、多进程/线程时代
在多进程/多线程的操作系统中,就解决了阻塞的问题,因为一个进程阻塞cpu可以立刻切换到其他进程中去执行
而且调度cpu的算法可以保证在运行的进程都可以被分配到cpu的运行时间片
这样从宏观来看,似乎多个进程是在同时被运行
但新的问题就又出现了,进程拥有太多的资源,进程的创建、切换、销毁,都会占用很长的时间
CPU虽然利用起来了,但如果
进程过多,CPU有很大的一部分都被用来进行进程调度了大量的进程/线程出现了新的问题
- 高内存占用
- 调度的高消耗CPU
- 进程虚拟内存会占用4GB[32位操作系统], 而线程也要大约4MB

# 3、Go协程goroutine
Go中,协程被称为goroutine,它非常轻量,一个goroutine只占几KB,并且这几KB就足够goroutine运行完
这就能在有限的内存空间内支持大量goroutine,支持了更多的并发
虽然一个goroutine的栈只占几KB,但实际是可伸缩的,如果需要更多内容,
runtime会自动为goroutine分配Goroutine特点:
- 占用内存更小(几kb)
- 调度更灵活(runtime调度)
# 4、协程与线程区别
- 协程跟线程是有区别的,线程由CPU调度是抢占式的
- 协程由用户态调度是协作式的,一个协程让出CPU后,才执行下一个协程

# 5、普通线程与goroutine
# 1)普通线程缺点
1)创建和切换太重
- 操作系统
线程的创建和切换都需要进入内核,而进入内核所消耗的性能代价比较高,开销较大;
- 操作系统
2)内存占用大
- 系统线程默认分配较大的栈内存,以防止极端情况下栈溢出
- 虽然只是虚拟地址空间,实际物理内存不会立即分配,但大多数线程并不需要这么多内存,导致浪费
- 线程的栈空间在创建时固定,无法动态调整,因此在某些场景仍可能面临栈溢出风险
# 2)goroutine为什么轻量
用户态线程
- Goroutine 是用户态的,创建和切换无需进入内核,开销远小于操作系统线程。
灵活的栈内存管理
- Goroutine 启动时默认栈大小仅为 2KB,大多数情况下足够用
- 如果需要更多空间,栈会自动扩展;当栈空间不再需要时,还能自动缩小
- 这样既避免了栈溢出的风险,也减少了内存浪费
# 02.调度器GMP模型 🔴
G:goroutine(协程:待执行的任务)M:thread(内核线程,不是用户态线程)由操作系统的调度器调度和管理P:processer(调度器)可以被看做运行在线程上的本地调度器
# 1、GM模型
G(协程),通常在代码里用go关键字执行一个方法,那么就等于起了一个GM(内核线程),操作系统内核其实看不见G和P,只知道自己在执行一个线程G和P都是在用户层上的实现并发量小的时候还好,当并发量大了,这把大锁,就成为了性能瓶颈

- GPM由来
- 基于没有什么是加一个中间层不能解决的思路,
golang在原有的GM模型的基础上加入了一个调度器P - 可以简单理解为是在
G和M中间加了个中间层 - 于是就有了现在的
GMP模型里的P
- 基于没有什么是加一个中间层不能解决的思路,
# 2、GMP模型
# 1)GMP概述
P和M的数量问题
- P的数量:环境变量
$GOMAXPROCS;在程序中通过runtime.GOMAXPROCS()来设置- M的数量:GO语言本身限定
一万(但是操作系统达不到)
G:goroutine(协程:待执行的任务)M:thread(内核线程,不是用户态线程)由操作系统的调度器调度和管理- 操作系统线程,负责真正执行代码,M 在运行时必须绑定一个 P 来调度 Goroutine
- M 的数量没有直接的上限,可以动态创建或销毁
P:processer(调度器)可以被看做运行在线程上的本地调度器- P 负责调度 Goroutine,它有自己的 Goroutine 队列,但 P 不能直接执行代码,它必须绑定一个 M
- P 的数量等于当前机器的 CPU 核数,默认值是
GOMAXPROCS = ncpu - 所以最多只有
GOMAXPROCS个 Goroutine 并发执行,其他 Goroutine 必须等待
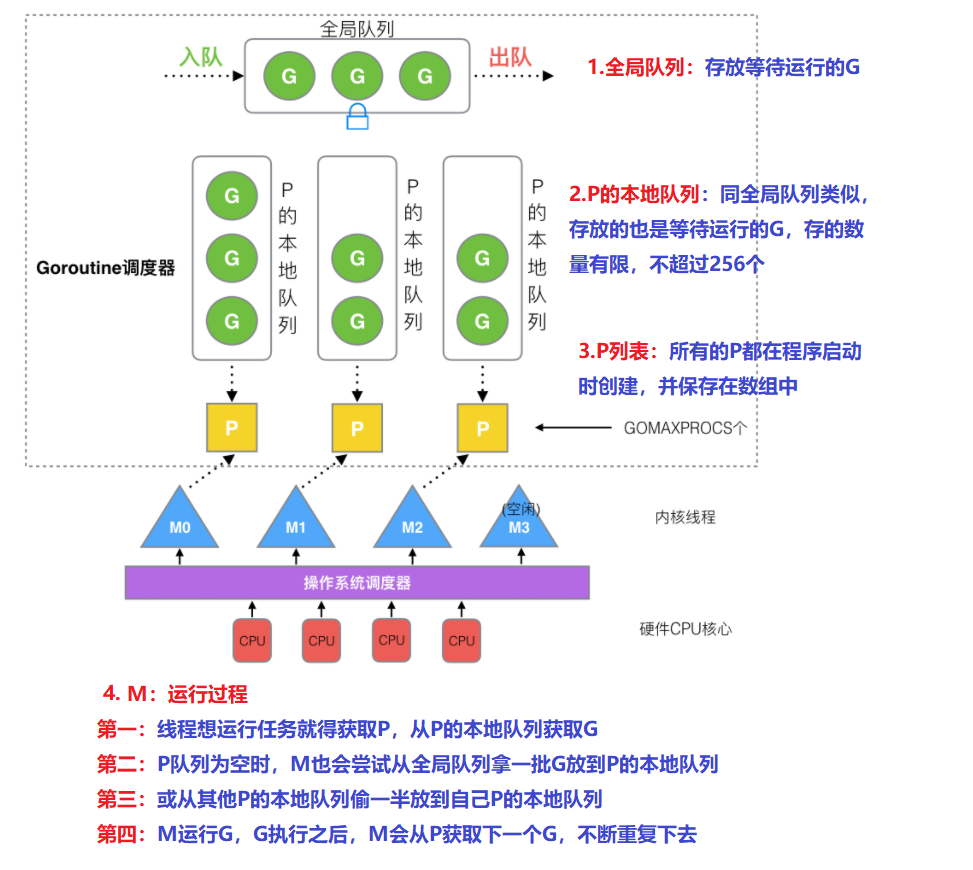
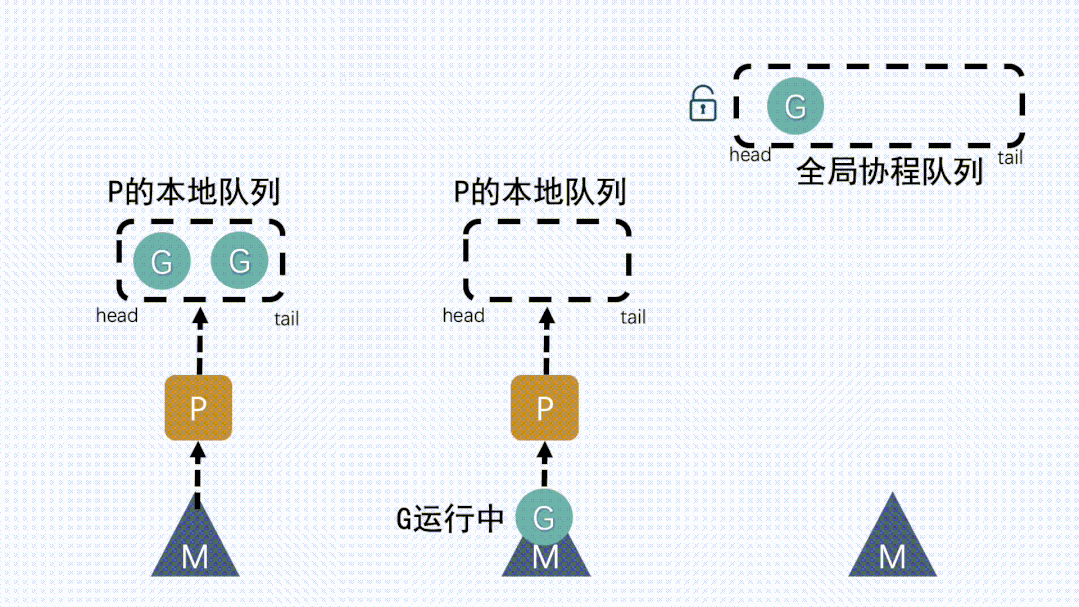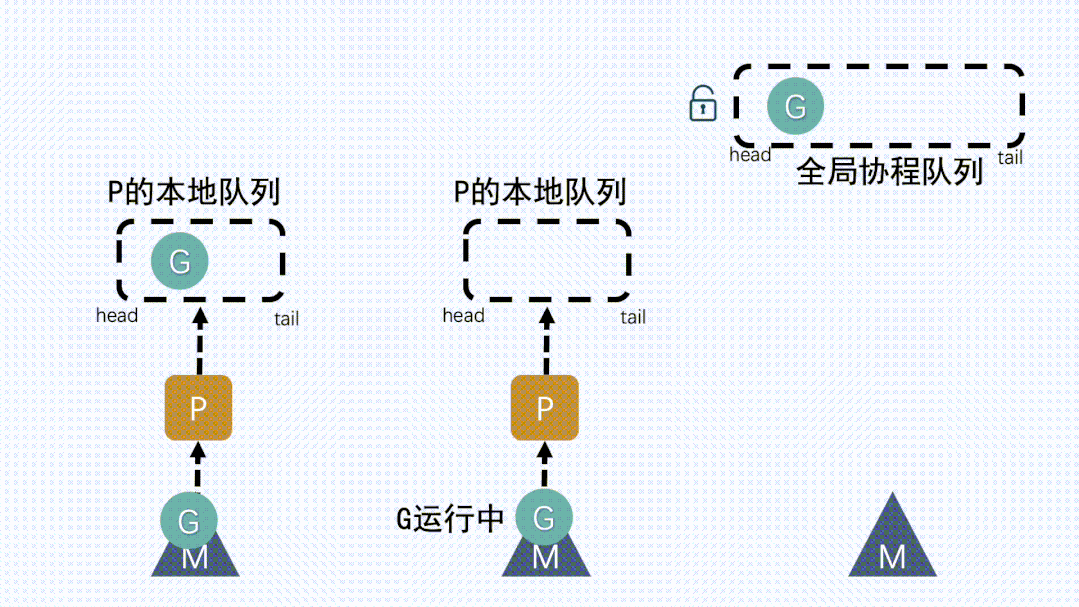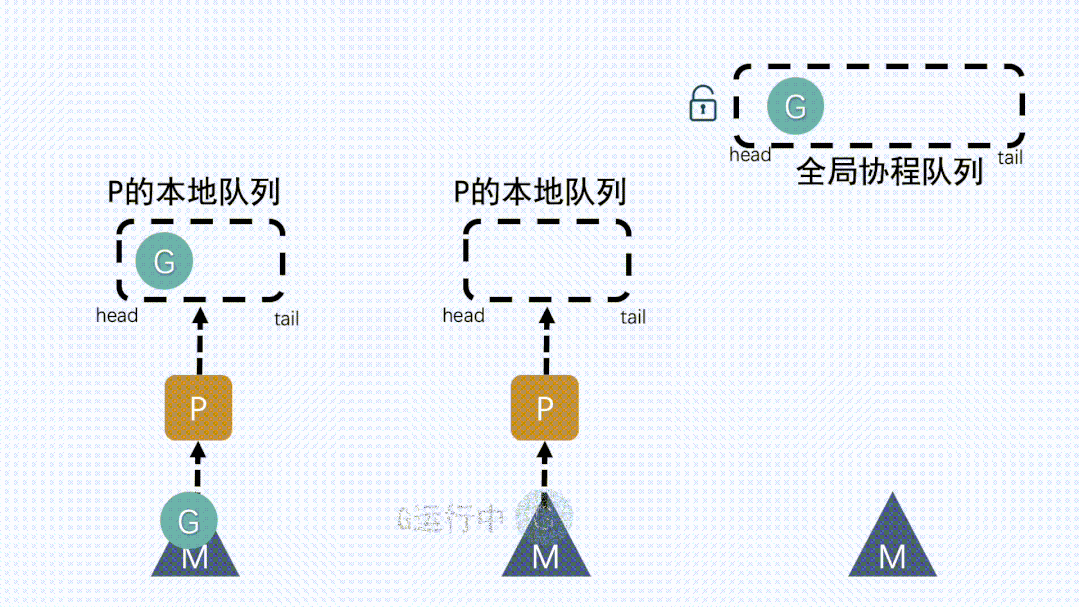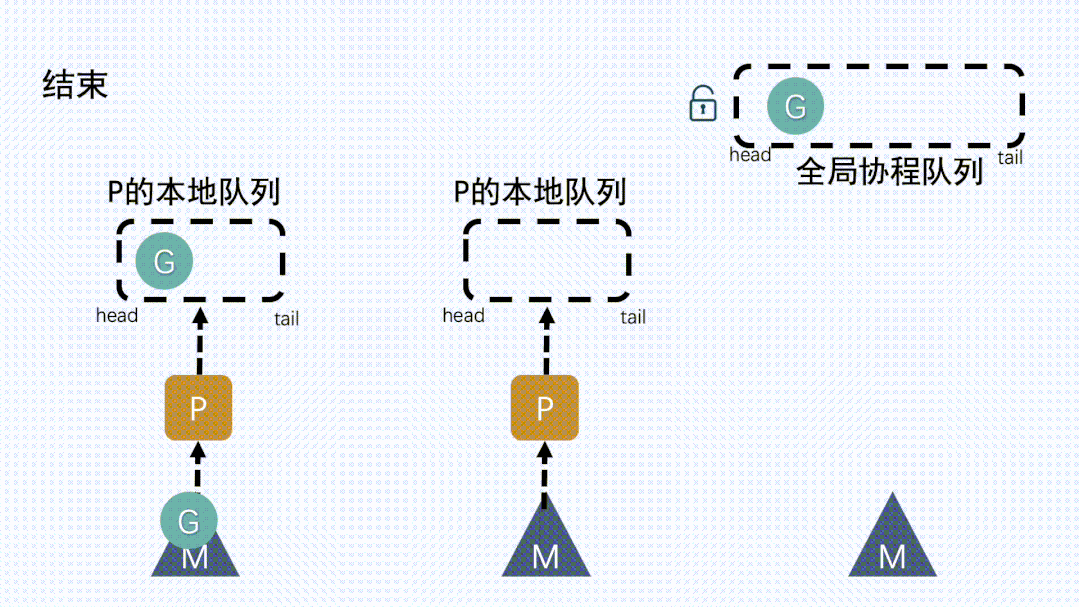
- 全局队列(Global Queue):存放等待运行的
G - P的本地队列:同全局队列类似,存放的也是等待运行的
G,存的数量有限,不超过256个
# 2)获取G
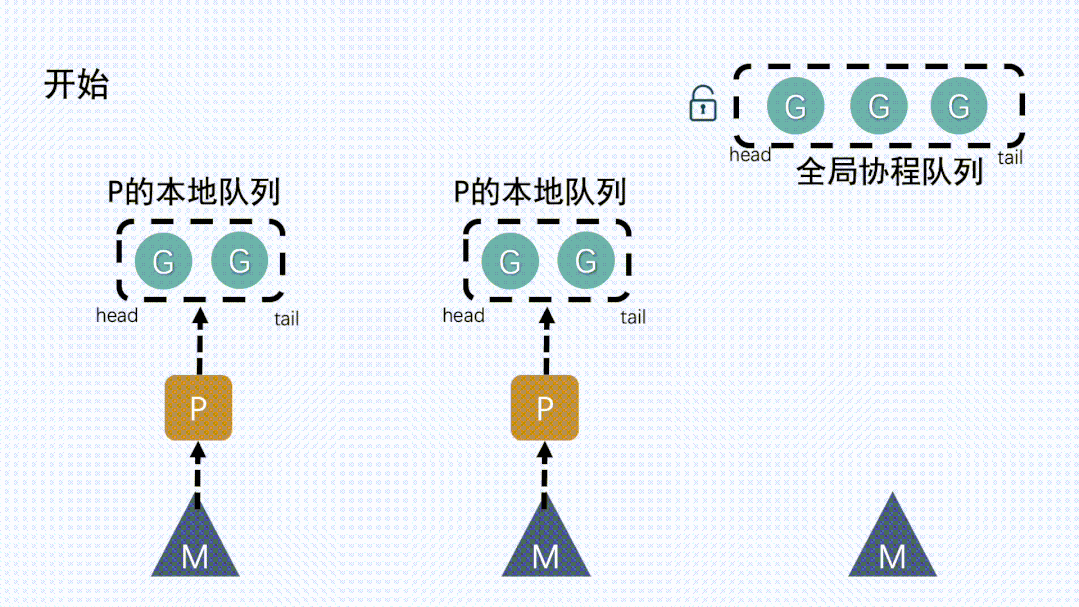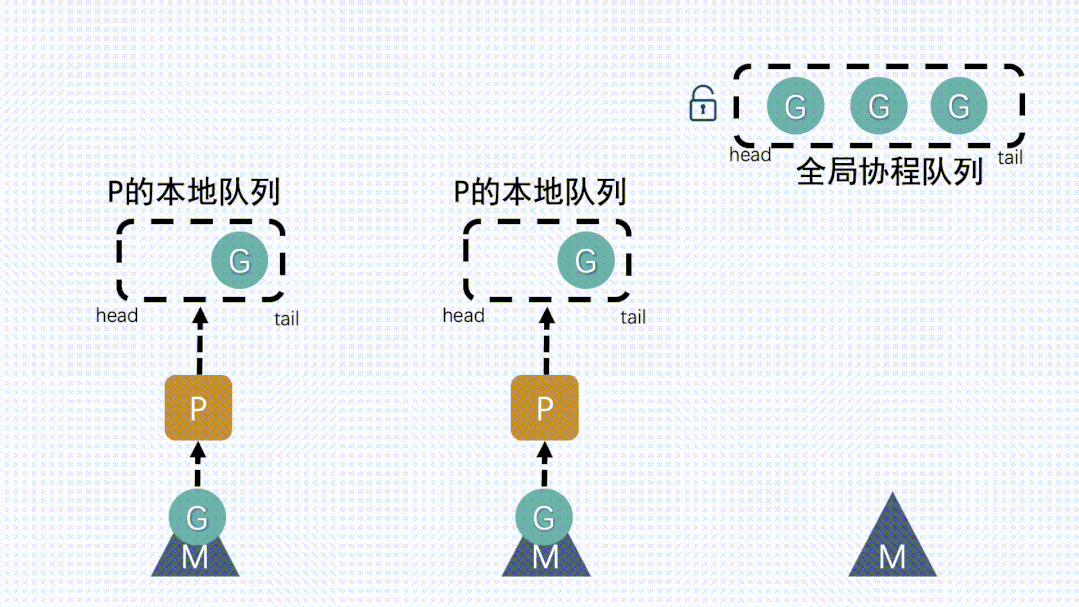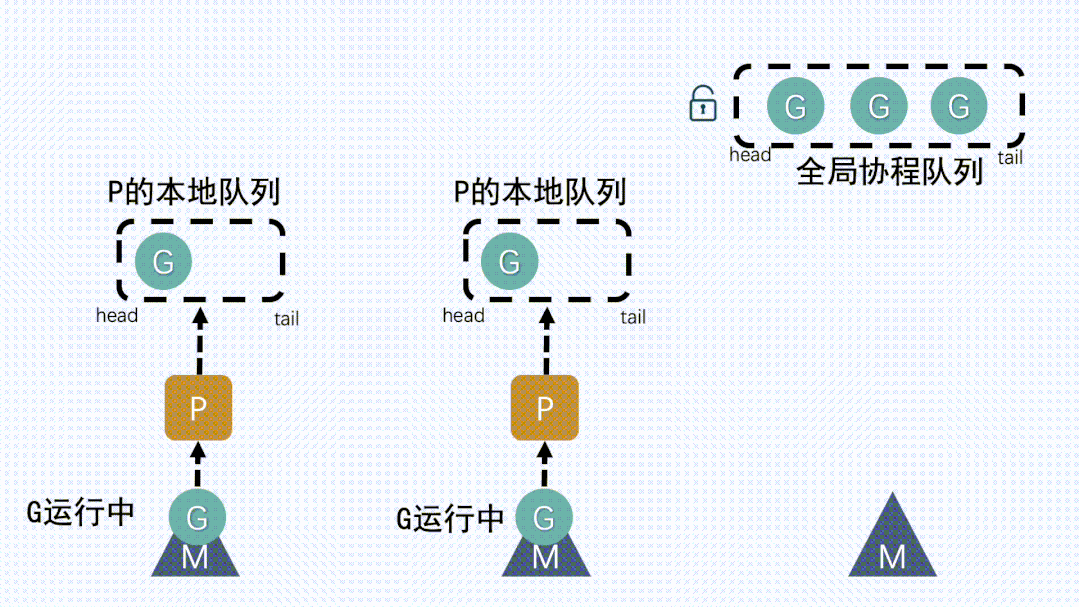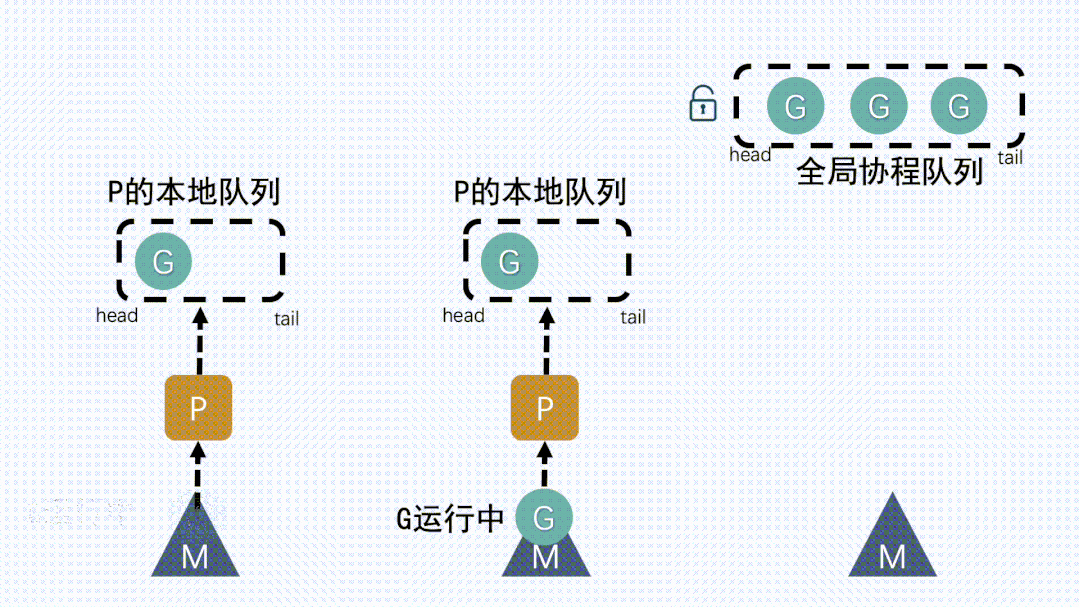
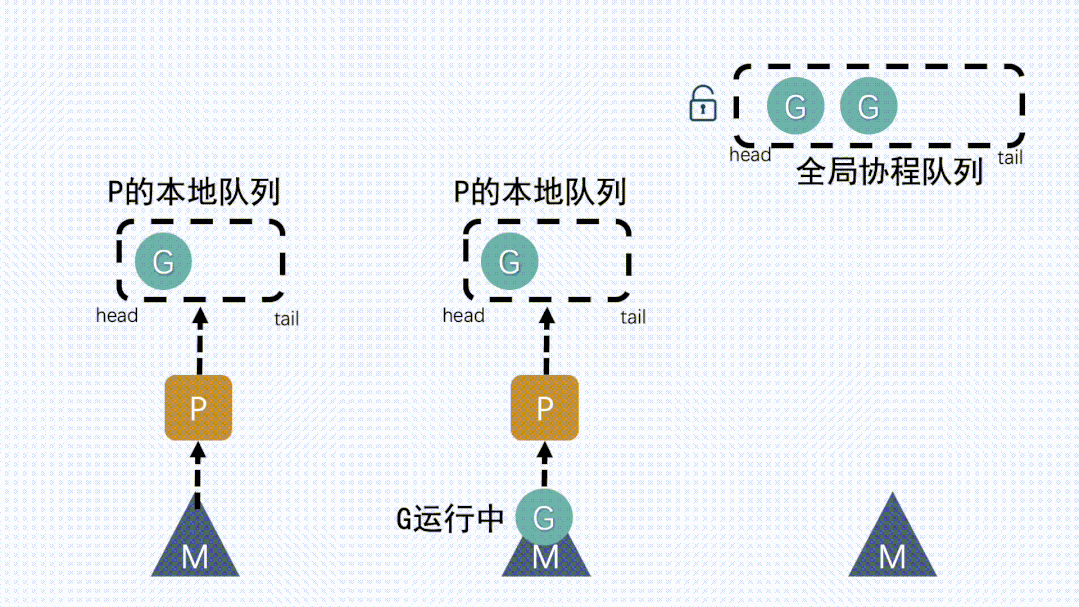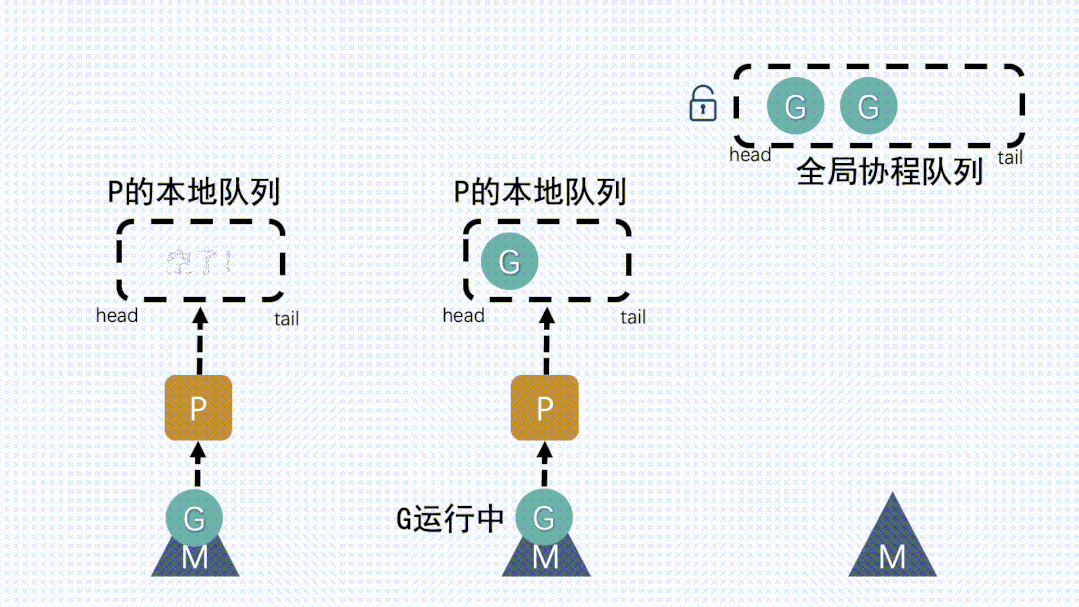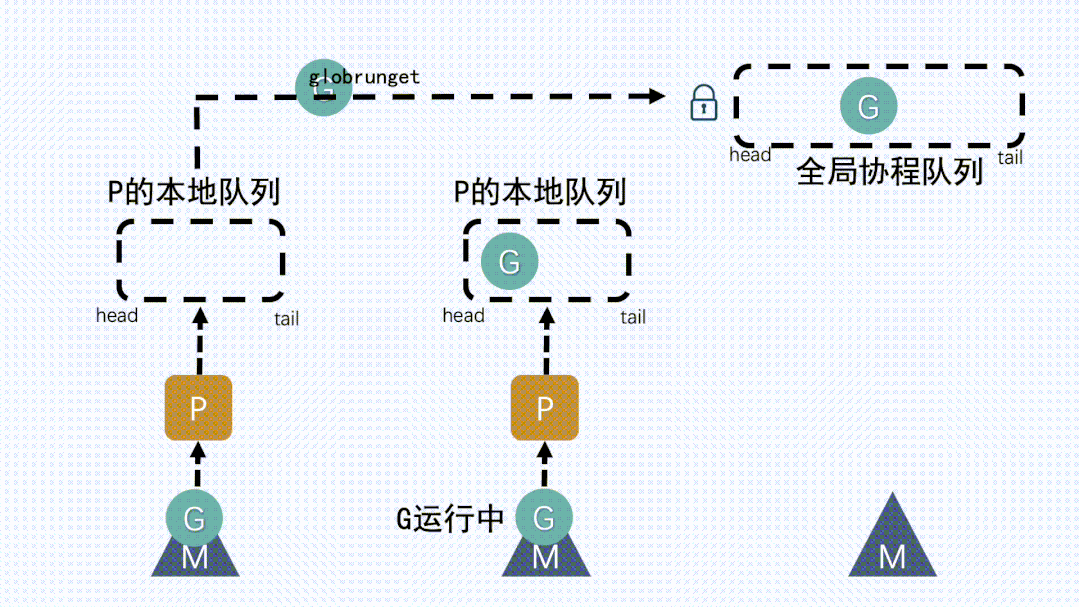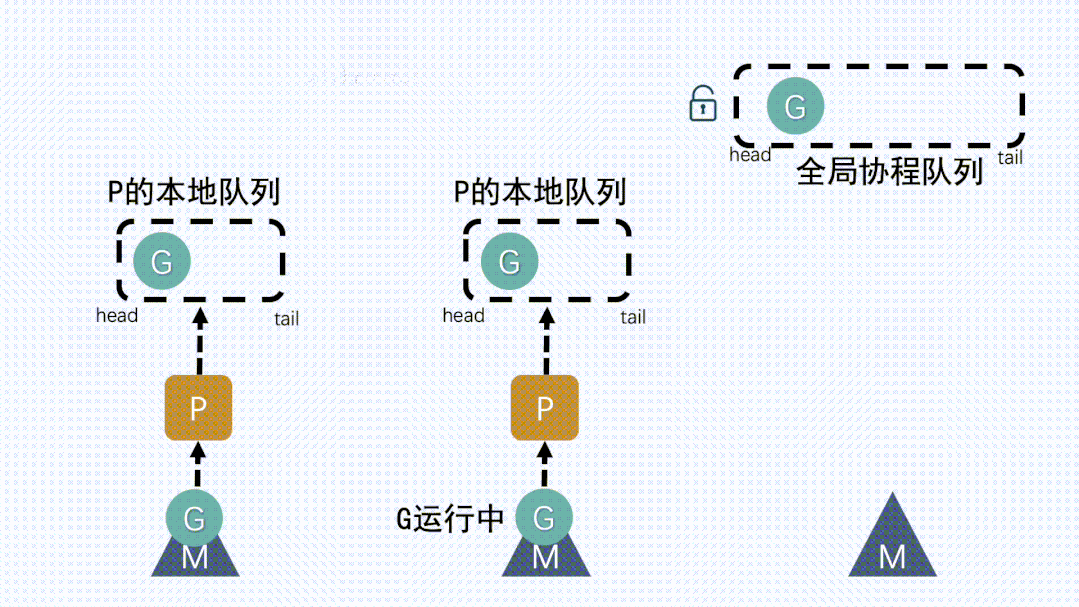
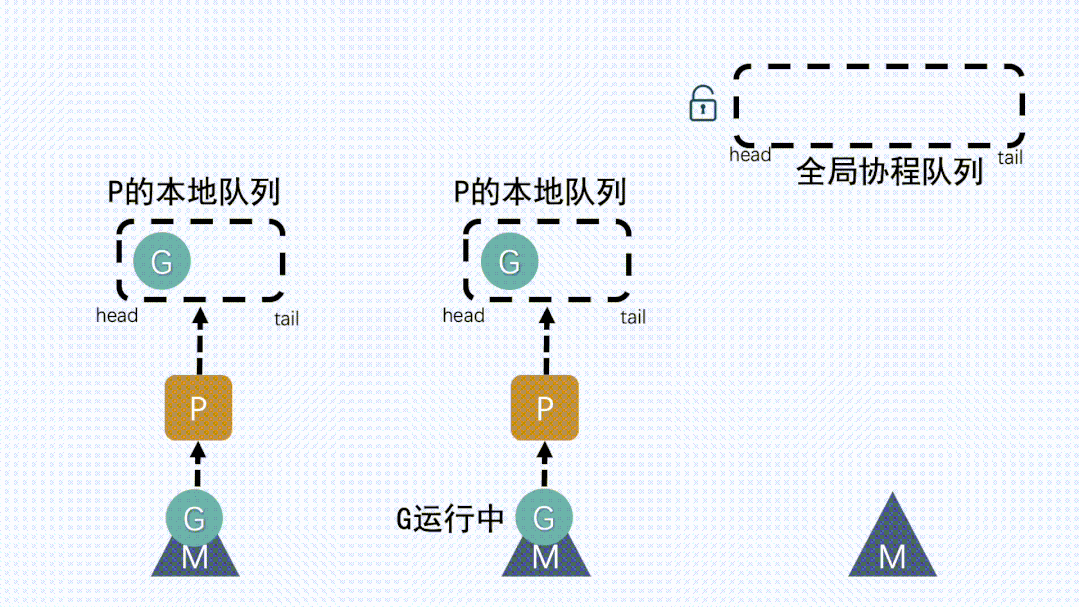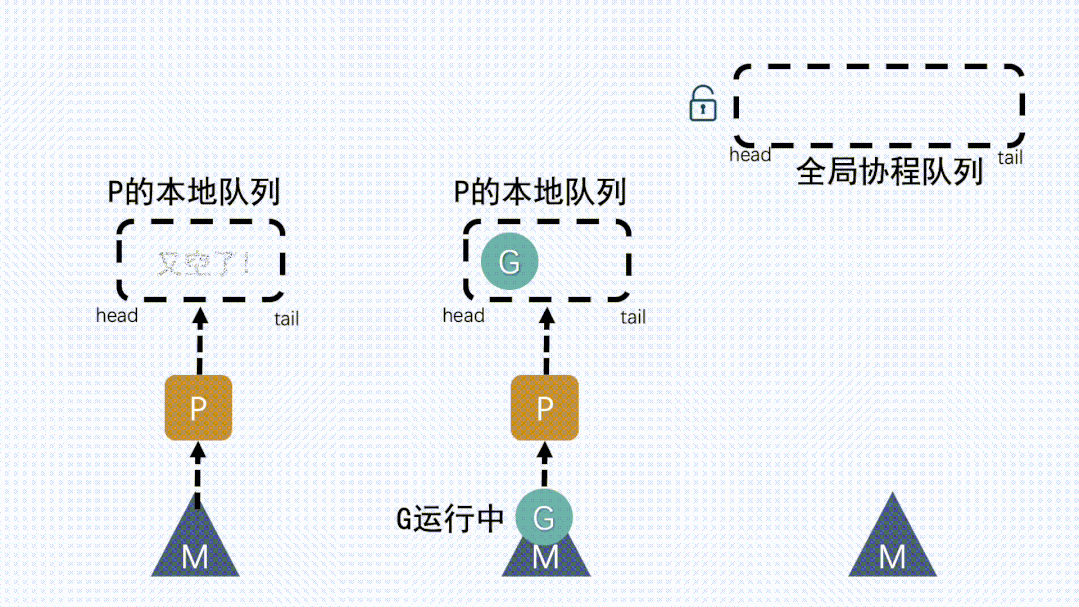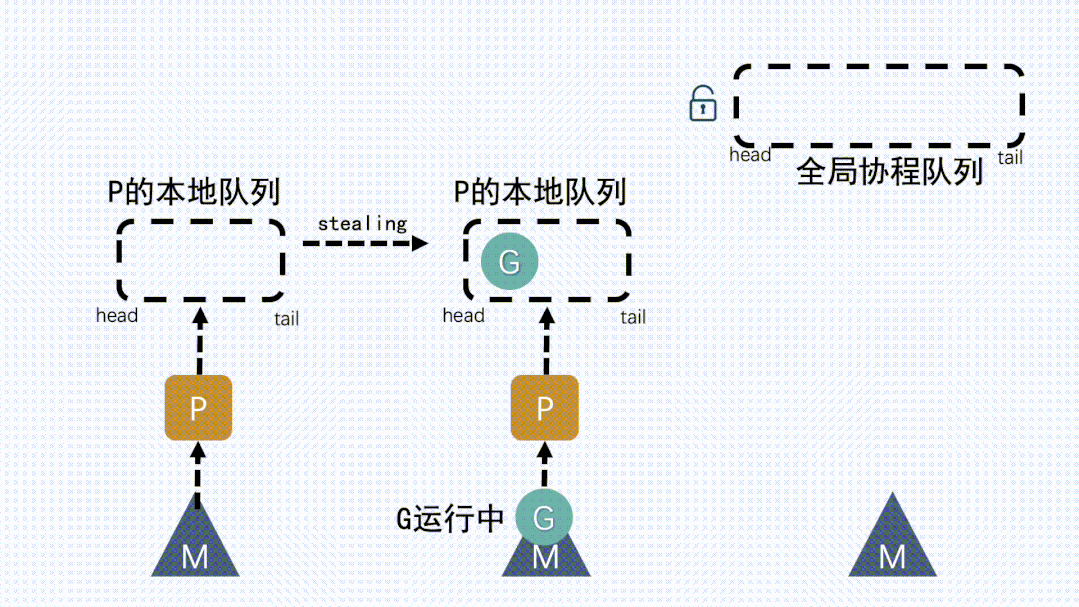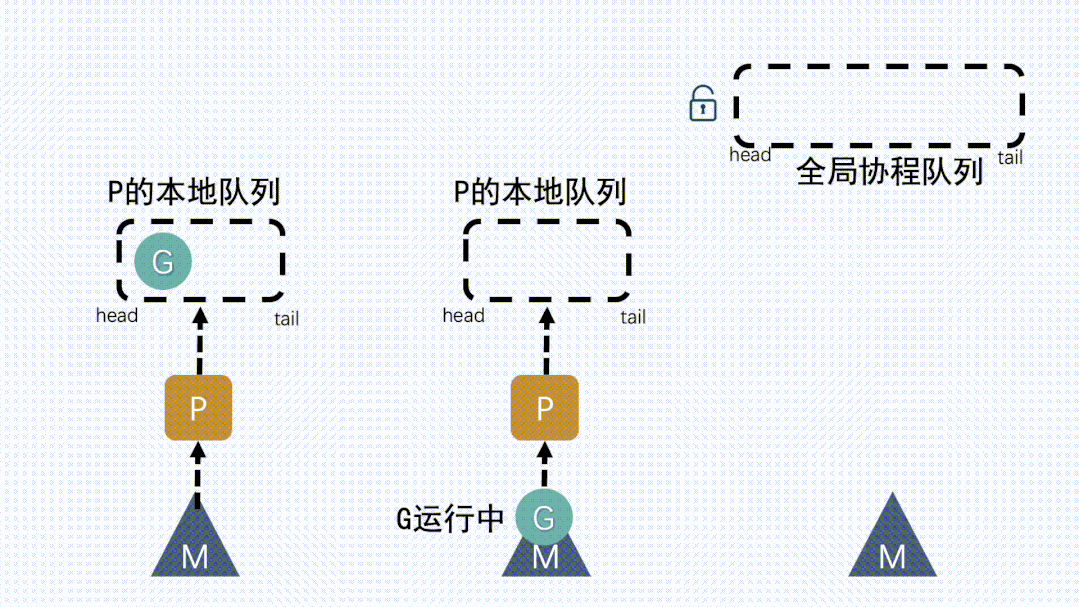
① P本地队列获取G- M
想要运行G,就得先获取P,然后从P的本地队列获取G
- M
② 本地队列中G移动到全局队列新建
G时,新G会优先加入到P的本地队列;如果本地队列满了,则会把本地队列中一半的
G移动到全局队列
③ 从其他P本地队列的G放到自己P队列- 如果全局队列为空时,
M会从其他P的本地队列偷(stealing)一半G放到自己P的本地队列
- 如果全局队列为空时,
④ M从P获取下一个G,不断重复M运行G,G执行之后,M会从P获取下一个G,不断重复下去
# 03.数据结构 🔴
# 1、g 结构体
- 当执行用户代码时
- 工作线程的栈指针指向当前正在执行的 Goroutine 的栈(执行代码的运行环境是g结构体提提供的栈空间)
- 这时,
M.curg指向当前正在执行的 Goroutine,执行用户代码指令- 当goroutine进行I/O操作或者其他阻塞时,会调度其他goroutine执行
- 当执行调度逻辑时
- 工作线程切换到
g0栈上,调度器代码运行在g0栈上(执行调度时使用g0栈空间)- 调度逻辑完成后,线程会根据需要切换到新的 Goroutine 的栈
# 1)g 结构体
g结构体g结构体用于代表一个goroutine,该结构体保存了goroutine所有运行状态及相关信息,执行上下文(包括寄存器、栈等)- 每当一个 Goroutine 被调度到 CPU 上运行时,调度器会从
g.sched中恢复寄存器状态,以便恢复上次的执行现场 - 执行代码的运行环境是
g结构体提提供的栈空间g.stack,在这个空间里执行具体的用户指令 - 当goroutine进行I/O操作或者其他阻塞时,当前 Goroutine 被挂起
- 当调度器决定挂起一个 Goroutine 时,它会将该 Goroutine 的寄存器状态保存到
g.sched中 - 并设置
g.preempt为true,以标识这个 Goroutine 需要被抢占
- 当调度器决定挂起一个 Goroutine 时,它会将该 Goroutine 的寄存器状态保存到
- 当该 Goroutine 再次被调度器选中时,调度器会从
g.sched中恢复寄存器状态,并继续执行
// 前文所说的g结构体,它代表了一个goroutine
type g struct
stack stack // 栈内存范围 [stack.lo, stack.hi)
sched gobuf // 保存调度信息,主要是几个寄存器的值
m *m // 该字段指向正在执行该 Goroutine 的工作线程(M)
preempt bool // 抢占调度标志,如果需要抢占调度,设置preempt为true
stackguard0 uintptr // 用于调度器抢占式调度
atomicstatus uint32 // Goroutine 的状态
// schedlink字段指向全局运行队列中的下一个g,所有位于全局运行队列中的g形成一个链表
schedlink guintptr
}
2
3
4
5
6
7
8
9
10
11
12
13
# 2)g结构体字段详解
1)stack- 该字段表示 Goroutine 的栈内存范围,Goroutine 在该栈上运行它的代码
- 场景:
- 当 Goroutine 运行时,会在该栈空间中分配局部变量和执行函数调用
- 当调度器需要挂起或恢复 Goroutine 时,它会使用这个栈范围来保存或恢复相关信息
2)schedsched保存了当前 Goroutine 的调度信息,主要是 CPU 寄存器的状态gobuf结构体包含了 PC(程序计数器)、SP(栈指针)等寄存器值- 这些值用于在 Goroutine 被挂起和恢复时记录和恢复其执行状态
- 场景:
- 当调度器挂起一个 Goroutine 时,它会将当前 CPU 寄存器的值保存到
sched中 - 然后,在 Goroutine 被重新调度时,调度器会从
sched恢复寄存器的状态
- 当调度器挂起一个 Goroutine 时,它会将当前 CPU 寄存器的值保存到
3)m- 该字段指向正在执行该 Goroutine 的工作线程(M),这表明当前
g是由哪个m绑定并正在运行 - 场景:
- 在 Go 的 GMP 模型中,M 负责执行 G,当一个 M 被分配一个 G 时,
g.m会指向对应的 M - 此字段用于追踪 Goroutine 和工作线程的关系
- 在 Go 的 GMP 模型中,M 负责执行 G,当一个 M 被分配一个 G 时,
- 该字段指向正在执行该 Goroutine 的工作线程(M),这表明当前
4)preempt- 当调度器检测到某个 Goroutine 长时间占用 CPU 时,可能会设置
preempt为true - 以强制中断该 Goroutine 并执行其他等待中的 Goroutine
- 当调度器检测到某个 Goroutine 长时间占用 CPU 时,可能会设置
5)stackguard0这是一个栈保护机制的标志,用于防止栈溢出
场景: 当 Goroutine 使用到栈空间时,如果超过了
stackguard0,调度器会检测到栈空间不足并进行处理
6)atomicstatus保存了当前 Goroutine 的状态,这是一个原子变量,用于记录 Goroutine 是处于运行、等待、停止等状态
调度器在对 Goroutine 进行调度时,会根据
atomicstatus来决定如何处理 Goroutine例如将其标记为可运行或将其放入等待队列
7)schedlinkschedlink用于将当前 Goroutine 链接到全局运行队列中的下一个 Goroutine全局运行队列中的 Goroutine 通过
schedlink字段形成一个链表结构调度器可以通过该链表遍历所有待运行的 Goroutine
场景:
- 当 Goroutine 处于全局运行队列中等待被调度时,
schedlink将其与下一个等待调度的 Goroutine 链接起来 - 调度器会使用该链表来管理全局的待运行 Goroutine
- 当 Goroutine 处于全局运行队列中等待被调度时,
# 2、m 结构体
# 1)m 结构体
m执行 Go 代码时,必须先绑定一个p
m通过p的runq获取本地队列中的 Goroutine
m将从runq中取出的 Goroutine 加载到curg字段,并开始执行该 Goroutine
// 结构关系图
m (工作线程)
└── p (逻辑处理器) // m.p 来访问 P
└── runq (局部运行队列) // 再从 P 的 runq 中取出 Goroutine
2
3
4
- 作用:通过
m可以找到当前正在运行的 Goroutine和工作线程的局部运行队列 m结构体:- m结构体用来代表
工作线程,它保存了m自身使用的栈信息 m.p可以访问处理器P,p.runq就是工作线程的局部运行队列m.curg可以找到当前运行的 Goroutinem.g0记录工作线程使用的栈起止位置
- m结构体用来代表
type m struct {
g0 *g // g0记录工作线程使用的栈信息
tls [6]uintptr // 实现m结构体与工作线程绑定(存储每个线程独有的数据)
curg *g // 指向工作线程正在运行的goroutine的g结构体对象
p puintptr // 记录与当前工作线程绑定的p处理器结构体对象
alllink *m // 记录所有工作线程的一个链表
nextp puintptr
oldp puintptr
spinning bool // 标记当前 M 是否处于“空闲状态”
blocked bool // 当前 M 是否处于阻塞状态
park note // 没有goroutine需要运行时,工作线程睡眠在这个park成员上
schedlink muintptr
thread uintptr // 存储了 M 对应的操作系统线程 ID
freelink *m // 链接到空闲的 M 链表上,等待被再次利用
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 2)m 结构体字段详解
1)g0- 工作线程在执行调度器代码时需要一个栈,但这个栈不应该和正在执行的 Goroutine 的栈混用,因此需要一个专用的栈,即
g0 - 执行用户代码时,工作线程切换到当前 Goroutine 的栈,调度代码会切换回
g0的栈 - 场景: 当 M 需要执行调度动作,比如切换 Goroutine 时,切换到
g0栈执行这些任务
- 工作线程在执行调度器代码时需要一个栈,但这个栈不应该和正在执行的 Goroutine 的栈混用,因此需要一个专用的栈,即
2)tlstls是线程局部存储(Thread-Local Storage),用于线程之间独立保存信息- 在 x86 架构下,这通过外部寄存器实现
- TLS 的目的是在不干扰其它线程的情况下,存储每个线程独有的数据
- 场景: 它
绑定了工作线程和 M 结构体对象,并确保调度器能快速找到当前线程的调度状态
3)pp是指向与当前 M 绑定的 P 结构体的指针,一个 M 需要有一个 P 才能执行 Go 代码- P 代表“处理器”,是 Go 运行时调度器用来分配 Goroutine 的逻辑执行上下文
- 每个
p维护自己的本地运行队列(即存放 Goroutine 的队列),并负责调度本地的 Goroutine 给m执行 - 场景: M 获取到 P 后,就可以从 P 的本地队列中取出待运行的 Goroutine,并开始执行
4)curgcurg指向当前 M 正在运行的 Goroutine- 这是 M 的主要工作,从调度器获取 Goroutine 并执行它们,
curg记录了当前被执行的 Goroutine - 场景: M 执行的用户代码是通过
curg对应的 Goroutine 运行的,调度器会不断切换 M 和不同的 G
5)alllinkalllink是一个指针,连接到所有 M 的链表上- Go 运行时会维护一个所有 M 线程的链表,
alllink是链表中的一环 - 场景: Go 运行时通过这个链表管理和跟踪所有的 M 实例
# 3、局部队列 P
局部队列:每个工作线程有自己的
局部 Goroutine 队列,以减少对全局队列的锁竞争(就是上图的局部队列)优先使用:工作线程首先操作自己的局部队列,只有在必要时才访问全局队列,提升并发性能
结构体位置:局部队列包含在
p结构体中,每个工作线程都关联一个p结构体实例
type p struct {
// 本地 Goroutine 运行队列
runqhead uint32 // 队列头索引
runqtail uint32 // 队列尾索引
runq [256]guintptr // 循环队列实现
runnext guintptr // 下一个待运行的 Goroutine
lock mutex // 用于保护 p 结构体的锁
status uint32 // p 的状态,如空闲、运行中等
link puintptr // 链接到下一个 p 结构体的指针
schedtick uint32 // 调度器调用次数计数器
syscalltick uint32 // 系统调用次数计数器
sysmontick sysmontick // 系统监控的最后观察时间
m muintptr // 关联的工作线程(M),空闲时为 nil
gFree struct {
gList // 已退出 Goroutine 的链表
n int32 // 当前缓存的 Goroutine 数量
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 4、全局队列 schedt
作用:存放所有可运行的 Goroutine 和调度器的状态信息
全局实例:
每个 Go 程序中有一个全局schedt实例(就是上图中全局队列)功能:它保存一个
全局运行队列,所有工作线程都能访问并操作这个队列
type schedt struct {
// Goroutine 全局运行队列
runq gQueue // 全局 Goroutine 运行队列
runqsize int32 // 运行队列的大小
midle muintptr // 由空闲的工作线程组成链表
nmidle int32 // 空闲工作线程数量
}
2
3
4
5
6
7
8
# 5、全局私有变量
allgs []*g // 全局数组,保存所有的g(Goroutine创建时加入到allgs中)
allm *m // 所有的m构成的一个链表,包括下面的m0
allp []*p // 保存所有的p处理器,len(allp) == gomaxprocs
ncpu int32 // 系统中cpu核的数量,程序启动时由runtime代码初始化,决定 P 的数量
gomaxprocs int32 // p的最大值,默认等于ncpu,但可以通过GOMAXPROCS修改
sched schedt // 调度器结构体对象,记录了调度器的工作状态
m0 m // 是主线程的 M 结构体,用于初始化调度器和运行时的其余部分
g0 g // g0 负责执行与 Goroutine 调度相关的底层操作,例如切换上下文、栈切换等
// 每个 M 都有自己的 g0,专门用于调度工作,而不运行普通的用户代码
2
3
4
5
6
7
8
9
10
11
12
1)allgs []*gallgs是一个全局的 Goroutine 数组,保存了所有已经创建的G结构体- 当一个 Goroutine 被创建时,它的
g结构体会被加入到allgs数组中,方便 Go 运行时追踪和管理所有的 Goroutine - 在垃圾回收(GC)过程中,调度器需要遍历所有的
G以便正确处理 Goroutine 的栈和上下文信息
2)allm *mallm是一个链表,用于管理所有的 M 结构体(也就是所有的操作系统线程)- 每当一个新的操作系统线程(
M)被创建时,它会被加入到allm链表中,方便调度器进行线程的追踪和管理 - 当某个线程不再需要执行任务时,调度器可以通过
allm链表复用这些线程,减少频繁创建和销毁线程的开销
3)allp []*pallp是一个保存所有P处理器的全局数组,P是 Go 调度模型的核心
4)sched schedt- 它管理全局队列
schedt,即当P的本地队列满时,Goroutine 会溢出到全局队列 - 当
P的本地队列为空时,也可以从全局队列中获取 Goroutine 执行
- 它管理全局队列
5)m0 mm0是程序启动时由操作系统创建的第一个M,是所有线程的起点,保存在全局变量中m0在完成初始化任务后与其他M没有区别,会参与正常的 Goroutine 调度和执行
6)g0 gg0是每个M都有的一个特殊 Goroutine,专门用于执行调度器的底层操作,而不执行用户代码- 每当
M需要执行调度任务(例如从一个G切换到另一个G)时,它会切换到g0的栈来执行这些底层任务 - 避免在用户 Goroutine 的栈上进行调度操作,以防止混乱
# 6、g0
g0是一个特殊的 Goroutine,绑定在m0上每个工作线程(
M)都有一个专门用于调度的 Goroutine,称为g0(g0是在用户空间中运行的)g0的作用是为m0提供调度环境,而不直接执行用户代码g0负责处理调度器的任务,比如上下文切换、保存和恢复 M 的状态等场景: 当 M 需要执行调度动作,比如切换 Goroutine 时,切换到
g0栈执行这些任务为什么需要g0?- 工作线程 (
M) 不能继续在用户 Goroutine 的栈上执行调度器的逻辑,否则会导致混乱
- 工作线程 (
切换 Goroutine 时g0上具体操作是什么?- 保存 Goroutine A 的上下文(寄存器状态、栈帧等)
- 然后从 Goroutine B 的
g结构体中恢复上下文
# 7、 m0
m0是Go 程序启动时由操作系统创建的第一个主线程,它是程序执行的起点负责
执行初始化操作(如堆的初始化、GMP 模型的初始化、创建P、启动调度器等)m0负责启动 Go 程序,并调用main.main()函数m0还会负责其他一些系统级别的任务,如垃圾回收初始化、系统资源管理等(普通m不会做这些)m0不会被销毁,它作为主线程保持整个程序的生命周期,直到程序终止(其他m可销毁)
# 04.调度器执行
# 1、调度器启动
- 在 Go 程序启动时,调度器会通过
runtime.schedinit函数进行初始化 主要就是 创建P处理器,并加入到 全局队列 allp 中
func schedinit() {
_g_ := getg() // 获取当前 Goroutine 的 g 结构体
sched.maxmcount = 10000 // 设置最大线程数为 10000
sched.lastpoll = uint64(nanotime()) // 获取当前时间戳,用于调度器的运行时记录
procs := ncpu // 默认使用系统 CPU 核数作为处理器数量
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
} // 如果环境变量 GOMAXPROCS 被设置且大于 0,则使用其值作为处理器数量
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
① 处理器数量 allp 扩容- 如果
allp切片中的处理器数量少于期望数量,会对allp进行扩容 - 调度器会根据 CPU 核心数(或
GOMAXPROCS的设置)扩容全局allp数组
- 如果
② 创建新的 P 结构体 和 p本地队列- 使用
new创建新的处理器结构体,并调用runtime.p.init初始化扩容的处理器 - 处理器
P是 Goroutine 调度的核心,每个P都维护自己的本地队列,用于存储待执行的 Goroutine
- 使用
③ m0 和 allp[0] 绑定- 每个
P都会通过new创建并初始化,其本地维护一个 Goroutine 队列(本地队列) - 这个本地队列就是上图中的局部p队列,用于存储待执行的 Goroutine
- 每个
④ P 加入 全局空闲队列中- 将除
allp[0]之外的处理器P全部设置为_Pidle状态,并加入到全局的空闲队列中 - 当有新的 Goroutine 被创建或需要调度时,调度器可以从空闲队列中取出处理器,确保资源高效利用
- 将除
# 2、M 和 G 的创建
# 1) m0
m0是Go 程序启动时由操作系统创建的第一个主线程,它是程序执行的起点负责
执行初始化操作(如堆的初始化、GMP 模型的初始化、创建P、启动调度器等)m0负责启动 Go 程序,并调用main.main()函数m0还会负责其他一些系统级别的任务,如垃圾回收初始化、系统资源管理等(普通m不会做这些)m0不会被销毁,它作为主线程保持整个程序的生命周期,直到程序终止(其他m可销毁)
# 2)g0
g0是一个特殊的 Goroutine,绑定在m0上- 每个工作线程(
M)都有一个专门用于调度的 Goroutine,称为g0(g0是在用户空间中运行的) g0主要作用是在M执行调度操作时提供栈空间,处理上下文切换,而不直接执行用户代码- 场景: 当 M 需要执行调度动作,比如切换 Goroutine 时,切换到
g0栈执行这些任务 为什么需要g0?- 工作线程 (
M) 不能继续在用户 Goroutine 的栈上执行调度器的逻辑,否则会导致混乱
- 工作线程 (
切换 Goroutine 时g0上具体操作是什么?- 保存 Goroutine A 的上下文(寄存器状态、栈帧等
- 然后从 Goroutine B 的
g结构体中恢复上下文
- 每个工作线程(
# 3)allm 作用
- Go 运行时中,所有的
M(操作系统线程)通过allm链表管理 - 每当需要新的
M,调度器会复用空闲的M或创建新的M,并加入到allm链表中 allm链表是 Go 调度器管理所有操作系统线程(M)的数据结构
# 3、Goroutine 创建
① 创建G结构体 加入P本地队列- 当调用
go func()创建新的 Goroutine 时,调度器会首先为其创建一个新的G结构体实例 G代表一个 Goroutine,包含其栈空间、寄存器状态及上下文信息- 新创建的
G被放入P绑定的本地队列中,等待调度执行
- 当调用
② 调度器分配执行资源(M、P、G 绑定)- 一个活跃的
M会从其绑定的P 的队列中取出 Goroutine 执行 - 每个
P绑定一个M,当M执行完一个 Goroutine 时,会检查其本地队列是否还有未完成的任务 - 如果有,会继续取出下一个 Goroutine 执行;如果没有,则可能
从其他 P 窃取Goroutine 执行
- 一个活跃的
③ 全局队列 schedt- 如果
P的本地队列为空且未能从其他P中窃取到任务,则会从全局队列schedt中获取 Goroutine 执行 - 全局队列用于存储从各
P溢出的 Goroutine,确保负载均衡
- 如果
④ M 的动态创建- 当所有
P都在工作而任务仍然较多时,调度器会根据需要创建更多的M,并将其绑定到空闲的P上 - 这些
M会通过allm链表管理,确保 Goroutine 调度的并发性
- 当所有
⑤ G 执行过程- 每个
G都在其分配的栈上执行具体的任务 - 当
G执行结束或因阻塞(如 I/O)需要挂起时,调度器会通过g0的栈保存G的上下文信息,并切换到其他待执行的G
- 每个
# 4、调度源码
- 在 Go 源码中,Goroutine 的选择和调度主要发生在
runtime包中 - 最核心的部分是
schedule()函数,它是调度的主循环,用于选择下一个要运行的Goroutine - 以下是源码中调度器选择 Goroutine 的相关代码流程简化解释
// runtime/proc.go
func schedule() {
_g_ := getg() // 尝试从当前 `P` 的本地队列中获取一个待执行的 `G`
// 循环查找下一个可运行的 Goroutine
for {
// 检查当前线程是否需要被抢占
if _g_.m.spinning {
// 如果 M 处于 spinning 状态,尝试窃取其他 P 的 Goroutine
_g_.m.spinning = false
}
// 从本地 P 的队列中查找可运行的 G
gp := runqget(_g_.m.p.ptr())
if gp != nil {
// 找到可运行的 G,准备执行
execute(gp, false)
continue
}
// 如果本地队列为空,尝试从全局队列或其他 P 窃取 Goroutine
gp, inheritTime := findrunnable()
if gp != nil {
// 找到可运行的 G,执行
execute(gp, inheritTime)
continue
}
// 如果没有找到可运行的 G,当前 M 会被挂起,等待新的任务
stopm()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
① runqget():- 尝试从当前
P的本地队列中获取一个待执行的G - 如果本地队列中有
G,它将被返回并由当前M执行
- 尝试从当前
② findrunnable():如果本地队列中没有
G,则调用findrunnable(),该函数会尝试通过以下几种方式找到下一个待执行的G尝试从其他
P的队列中窃取一个G从全局队列
schedt中获取一个待执行的Gfunc findrunnable() (*g, bool) { // 窃取其他 P 的 G 或从全局队列获取 G gp := globrunqget(_g_.m.p.ptr(), false) if gp != nil { return gp, false } // 继续其他查找逻辑,比如 timer 或 network I/O // 略去其他部分... }1
2
3
4
5
6
7
8
9
10
③ execute():一旦找到了一个
G,调用execute()函数,开始运行该Gfunc execute(gp *g, inheritTime bool) { // 设置当前的 Goroutine 为 gp 并开始执行 _g_.m.curg = gp // 切换到目标 Goroutine 的上下文 gogo(&gp.sched) }1
2
3
4
5
6
# 5、举例分析
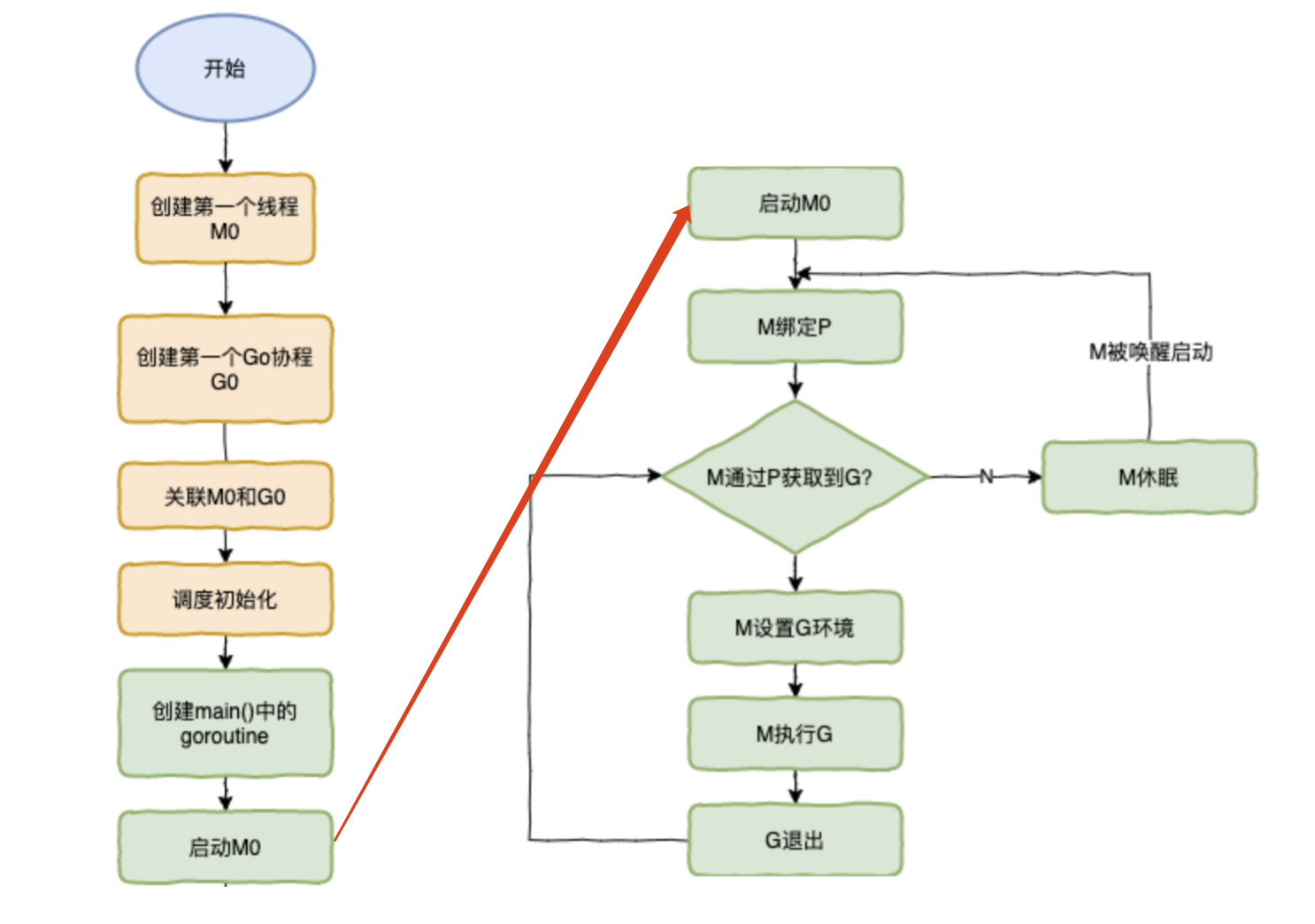
- 执行下面这段go代码时具体做了哪些操作
func main() {
fmt.Println("Hello world")
}
2
3
1)创建m0和g0关联- 当 Go 程序启动时,Go 运行时首先会创建第一个操作系统线程(
M0),并为该线程分配一个特殊的 Goroutineg0m0是主线程,它代表最初的操作系统线程,m0会负责初始化调度器和垃圾回收等核心任务g0是一个特殊的 Goroutine,不运行用户代码,而是用于处理调度操作和栈切换
- 通过
m0.g0的方式,将两者关联在一起
- 当 Go 程序启动时,Go 运行时首先会创建第一个操作系统线程(
2)初始化P列表- 在程序启动的早期阶段,Go 运行时会初始化调度器,设置一些全局变量和数据结构
- 创建对应数量的
P处理器和p本地队列,并把 P 处理器存储到allp 全局数组中
3)把main goroutine加入队列- 在程序启动时,Go 运行时会创建一个特殊的
mainGoroutine,它对应runtime.main函数 - 这个
G结构体会加入到P的本地队列中, 等待调度器调度执行
- 在程序启动时,Go 运行时会创建一个特殊的
4)P绑定m执行main goroutine- 在程序启动时,
M0会被绑定到一个P - 调度器将
M0和P绑定后,M0会从P的本地队列中获取mainGoroutine,准备开始执行用户代码
- 在程序启动时,
5)g0设置运行环境M0执行调度操作时,会使用g0来进行上下文切换- 此时,
g0会负责设置运行环境,确保M0能正确切换到mainGoroutine 并执行用户代码。
6)M运行G- 当
M0切换到mainGoroutine 时,M0开始执行用户的main.main函数 - 此时,用户代码中的
fmt.Println("Hello world")会输出到标准输出 M0执行mainGoroutine 的栈帧,直到main.main函数结束runtime.main的作用:- 在
main.main函数执行完后,runtime.main还负责一些资源清理操作,包括垃圾回收、Panic 处理和关闭程序
- 在
- 当
7)重复下去- G退出,再次回到M获取可运行的G,这样重复下去,直到
main.main退出 runtime.main执行Defer和Panic处理,或调用runtime.exit退出程序
- G退出,再次回到M获取可运行的G,这样重复下去,直到