 10.损失函数
10.损失函数
# 01.损失函数
- 损失函数(Loss Function) 是机器学习和深度学习中用于评估模型预测性能的重要工具
- 它的作用是量化模型的预测值与真实标签(目标值)之间的差距,并为模型优化提供指导信号
- 损失函数的输出值越小,表示模型的预测越接近真实值;反之,损失值越大,表示模型的预测差距越大
# 1、损失函数的作用
- 衡量模型预测的准确性:
- 损失函数通过计算模型预测值和真实值之间的差距,帮助我们判断模型的好坏
- 如果模型的预测准确,损失函数值会较小;如果预测不准确,损失函数值会较大
- 提供优化目标:
- 在训练过程中,模型通过最小化损失函数来优化参数(如权重和偏置)
- 优化过程就是通过调整模型的参数,使得损失函数的值越来越小,从而提高模型的预测准确性
- 指导模型训练:
- 损失函数通过梯度下降等优化算法反向传播梯度,逐步更新模型的参数
- 通过损失函数计算梯度并调整参数,模型可以渐渐学习到输入和输出之间的最佳映射关系
# 2、损失函数的形式
- 损失函数的形式取决于具体的任务和目标
- 例如,
- 对于
回归问题,常用的损失函数是均方误差(MSE) - 而对于
分类问题,常用的损失函数是交叉熵损失(Cross-Entropy)
- 对于
# 1)回归问题中的损失函数
回归问题的目标是预测一个连续的数值,损失函数通常用于衡量
预测值与真实值之间的差距均方误差(Mean Squared Error,MSE):
- 这是回归问题中最常用的损失函数,它计算的是预测值和真实值之间的差异的平方和的平均值
- 公式如下:
- MSE通过计算预测误差的平方,确保了大误差的惩罚更大
- 从而使得模型倾向于减少较大的预测误差
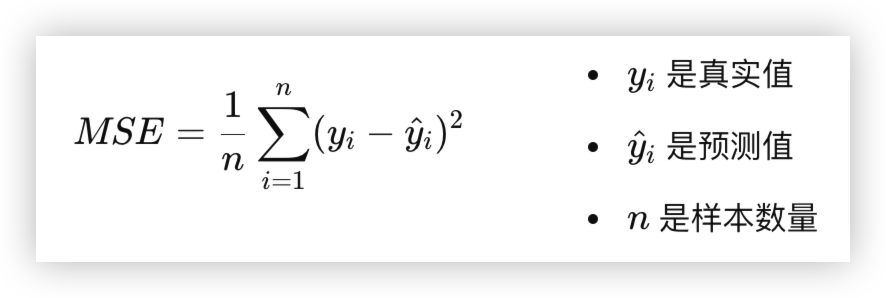
# 2)分类问题中的损失函数
分类问题的目标是将数据划分为不同的类别,损失函数通常用于衡量模型预测类别与真实类别之间的差异
交叉熵损失(Cross-Entropy Loss)
- 交叉熵损失是分类问题中最常用的损失函数,尤其是对于多分类问题
- 它计算的是模型预测的概率分布与真实标签之间的差异
- 公式如下
- 交叉熵损失度量了模型预测的类别概率分布与真实标签之间的不匹配程度
- 交叉熵越小,表示预测概率分布越接近真实标签
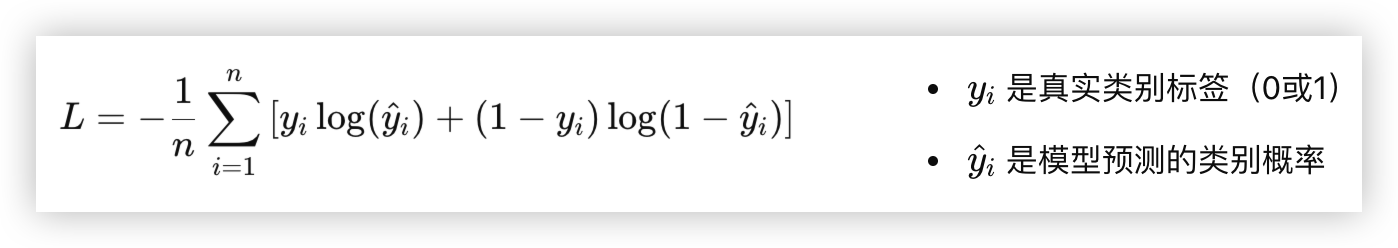
上次更新: 2025/3/13 17:01:28