 03.kafka原理 ✅常识原理
03.kafka原理 ✅常识原理
Kafka是一个分布式消息系统,具有高吞吐量和高可用性
其架构由Broker、Topic、Partition和Offset组成
Producer发送消息到指定Topic,消息存储在分区中,并且按Offset顺序排列
Consumer根据Offset消费消息,并通过Zookeeper管理集群元数据
Kafka支持Replication机制,确保Leader副本失效时能从同步的Follower副本中选出新的Leader
通过索引文件优化查询速度,同时支持批量生产消费,提升系统吞吐量
# 01.kafka原理
# 1、kafka特性
# 1、架构图

broker:Kafka服务器,负责消息存储和转发topic:消息类别,Kafka按照topic来分类消息partition:topic的分区,一个topic可以包含多个partition,topic消息保存在各个partition上offset:消息在日志中的位置,可以理解是消息在partition上的偏移量,也是代表该消息的唯一序号Producer:消息生产者Consumer:消息消费者Consumer Group:消费者分组,每个Consumer必须属于一个groupZookeeper:保存着集群broker、topic、partition等meta数据- 还负责
broker故障发现,partition leader选举,负载均衡等功能
# 2、生产消费流程
1)生产消息生产者
创建消息,该消息包含一个key和一个value生产者将消息发送到Topic
- 如果指定了Partition,消息将被发送到指定的Partition
- 如果没有指定,Kafka会根据key的Hash值或者round-robin策略选择一个Partition
消息到达Broker后,首先会被
写入到Leader副本的本地logFollower副本从Leader副本中拉取消息,写入自己的本地log
当所有的ISR副本都成功写入消息后,消息可以被消费
2)消费消息消费者订阅一个或多个Topic,
从Zookeeper获取每个Topic的Leader副本信息消费者向Leader副本发送fetch请求,拉取消息
Leader副本返回已提交的消息给消费者,消费者处理消息
在处理完消息后,消费者会更新自己的offset,表示已经成功消费了哪些消息
3)Zookeeper作用在整个过程中,
Zookeeper主要负责管理和协调Broker和消费者当Broker或者消费者的状态发生变化时(例如Broker宕机,新的消费者加入等)
Zookeeper会通知相关的Broker和消费者,使它们能够及时地响应这些变化
同时,
Zookeeper还负责存储每个消费者消费的offset以便在
消费者重启时,能够从上次消费的位置继续消费
# 3、路由机制
消费者启动后会
发送请求给任意 Broker,Broker从Zookeeper获取集群元数据返回给消费者这样生产者和消费者就可以
控制消息被推送到哪些partition实现的方式可以是
随机分配、实现一类随机负载均衡算法,或者指定一些分区算法kafka Producer可以将消息在内存中累计到一定数量后作为一个batch发送请求Batch的数量大小可以通过Producer的参数控制(
如500条、100ms、64KB)
# 2、kafka存储设计
# 0、日志分段存储
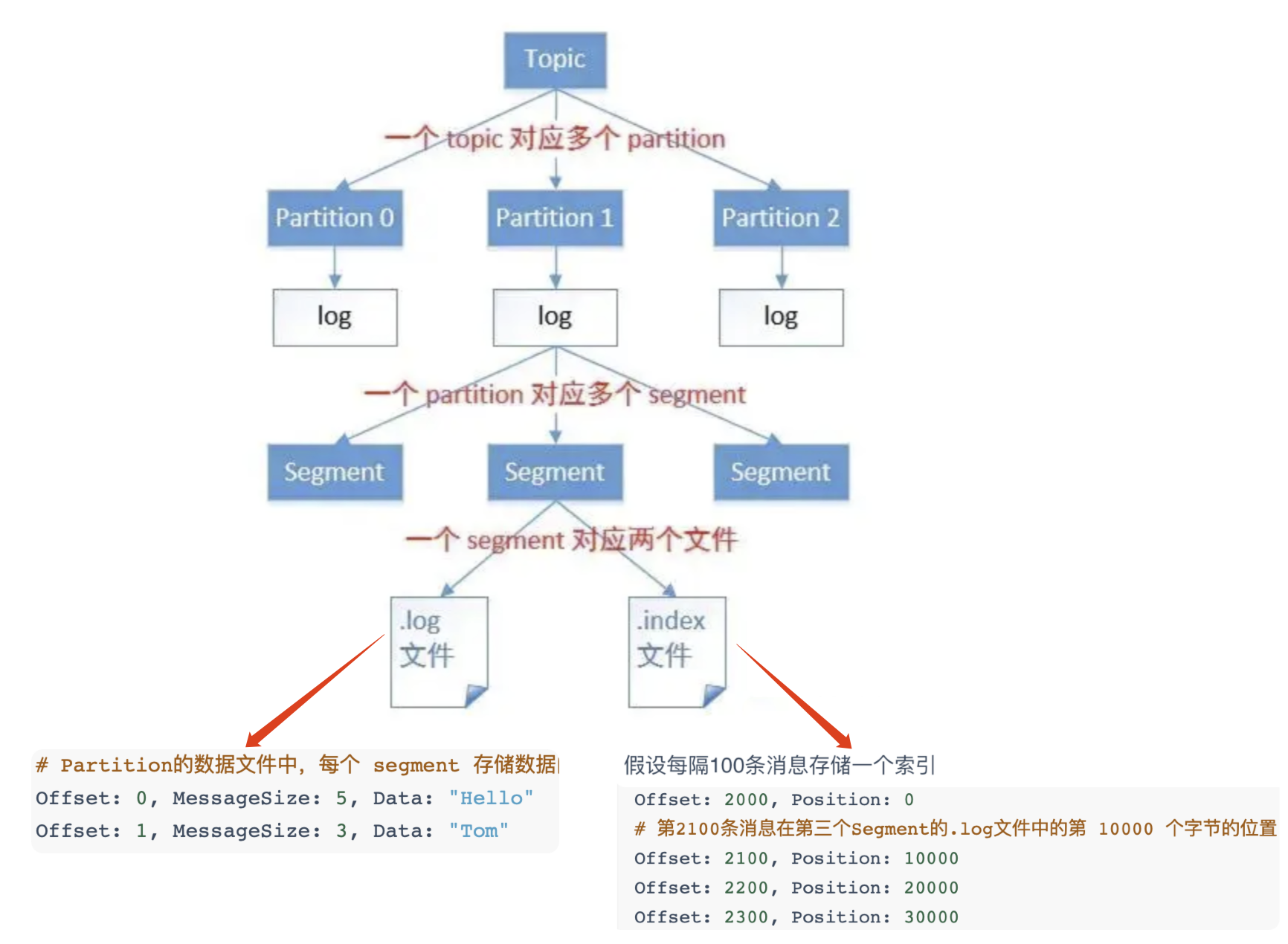
# 1、Topic(主题)
- 在Kafka中,
主题(Topic)会被划分为一个或多个分区(Partition) 每个分区在物理上对应一个文件夹,这个文件夹中包含了多个数据文件(.log文件)和索引文件(.index文件).log文件是存储实际消息数据的文件,每个.log文件的大小是可以配置的,默认情况下为1GB- 当.log文件达到最大大小时,Kafka会创建一个新的.log文件来存储后续的消息,这样就形成了一个按照时间顺序排列的.log文件序列
- 每个
.log文件的文件名是由该文件中第一条消息的偏移量(offset)组成的 .index文件是对应.log文件的索引文件,用于快速定位消息在.log文件中的位置- .index文件的文件名和对应的.log文件相同,只是扩展名不同
- 除了.log和.index文件,每个分区的文件夹中还可能包含一个.timeindex文件和一个.txnindex文件
- .timeindex文件是用于根据时间戳来查找消息的索引文件,.txnindex文件则是用于事务索引的
- Kafka的每个分区都由多个.log文件和相应的索引文件组成,这些文件共同提供了消息的存储和索引功能
# 2、partition(分区)
- partition以文件形式存储在文件系统,目录命名规则:
<topic_name>-<partition_id> - 例如,名为test的topic,其有3个partition,则Kafka数据目录中有3个目录
- test-0, test-1, test-2,分别存储相应partition的数据
.log文件是存储实际的消息数据.index文件是存储对应的偏移量和物理位置,用于快速定位消息在.log文件中的位置.timeindex文件则是存储消息的时间戳和对应的偏移量,用于按照时间戳查找消息
/test-0/
00000000000000000000.index # .index`文件是存储`对应的偏移量和物理位置
00000000000000000000.log # .log文件是存储实际的消息数据
00000000000000000000.timeindex
/test-1/
00000000000000000000.index
00000000000000000000.log
00000000000000000000.timeindex
/test-2/
00000000000000000000.index
00000000000000000000.log
00000000000000000000.timeindex
2
3
4
5
6
7
8
9
10
11
12
# 3、Segment(.log)
- 每个Partition的数据并不是存储在一个大的文件中,而是
被分割成多个较小的文件- 每个
这样的文件就被称为一个Segment
Kafka中,数据被存储在
Topic的Partition中每个Partition对应一个或
多个数据文件(这就是Segment)每个Segment数据文件中包含了
多条消息(Message)(每条消息包含三个属性)1、Offset
- 这是每条消息在Partition中的
唯一标识,可以看作是消息的序号 - 它是
逻辑上的一个值,表示这条消息是Partition中的第几条消息 - Offset是连续的,
从0开始,每写入一条消息,Offset就会增加1 - 消费者在读取消息时,也是根据Offset来读取的,所以Offset的作用就像是消息的ID一样
- 这是每条消息在Partition中的
2、MessageSize:
- 表示消息内容data的大小,单位是字节
3、Data:
- 这是消息的具体内容,也就是要发送的数据
# Partition的数据文件中,每个 segment 存储数据内容就像下面这样
Offset: 0, MessageSize: 5, Data: "Hello"
Offset: 1, MessageSize: 3, Data: "Tom"
Offset: 2, MessageSize: 2, Data: "NB"
2
3
4
# 4、kafka索引(.index)
Kafka通过将部分消息的偏移量和对应的物理位置存储在索引文件中
实现了快速定位数据的能力,从而提高了数据读取的性能
Kafka数据存储在磁盘文件中,
每个文件都对应一个索引文件(用于快速定位数据)Kafka数据文件
(.log)是顺序写入的,每条消息位置都由一个偏移量(offset)标识索引文件
(.index)是存储了部分消息的偏移量和对应在数据文件中的物理位置Kafka的索引文件是
每隔一段偏移量(比如每隔4096个字节)才中添加一条记录查询时,Kafka先在
索引文件中通过二分查找定位到对应位置,然后在数据文件中顺序读取数据- 磁盘顺序读取的性能远高于随机读取,所以Kafka在处理大量数据时能保持高性能
eg: 从下面例子更深入理解索引原理
- 假设我们有一个Kafka Topic,它有一个分区
- 这个分区有三个Segment,每个Segment包含了1000条消息
- 假设每隔100条消息存储一个索引
- 那么第
三个Segment的.index文件可能看起来像这样
# Offset是消息的偏移量,Position是消息在.log文件中的物理位置
# 注意这里的Position是假设的,实际的Position取决于每条消息的大小
Offset: 2000, Position: 0
# 第2100条消息在第三个Segment的.log文件中的第 10000 个字节的位置
Offset: 2100, Position: 10000
Offset: 2200, Position: 20000
Offset: 2300, Position: 30000
Offset: 2400, Position: 40000
Offset: 2500, Position: 50000
Offset: 2600, Position: 60000
Offset: 2700, Position: 70000
Offset: 2800, Position: 80000
Offset: 2900, Position: 90000
2
3
4
5
6
7
8
9
10
11
12
13
现在,我们想要查找offset为2500的消息
- 第三个Segment的起始offset为2000,结束offset为2999,所以offset为2500的消息应该在第三个Segment
- 打开第三个Segment对应的.index文件,然后使用二分查找法在.index文件中查找offset为2500的条目
- 假设我们的.index文件每隔100条消息存储一个索引,那么Kafka可能会找到offset为2400的索引
- 然后,Kafka会根据这个索引条目中存储的物理位置,定位到.log文件中offset为2400的消息
- 由于.log文件中的消息是按照offset连续存储的,所以Kafka只需要顺序读取100条消息,就可以找到offset为2500的消息
# 3、生产者&消费者
# 1、生产者设计
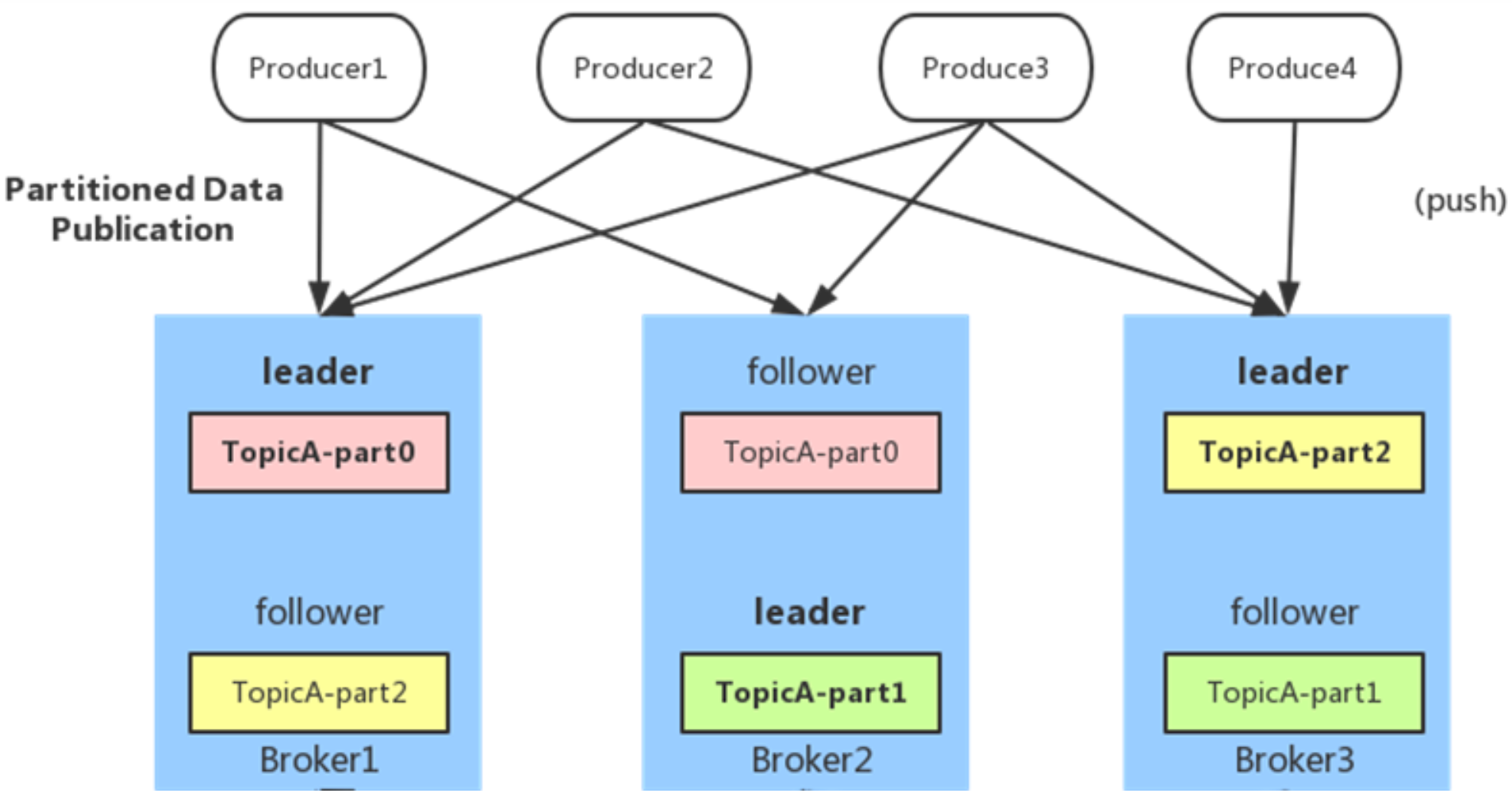
1)负载均衡- 由于消息topic由多个partition组成,且partition会均衡分布到不同broker上
producer可以通过随机或者hash等方式,将消息平均发送到多个partition上,以实现负载均衡
2)批量发送Producer端可以合并多条消息,一次发送批量消息给broker(减少broker存储消息的IO操作次数)- 但也一定程度上影响了消息的实时性,相当于以时延代价,换取更好的吞吐量
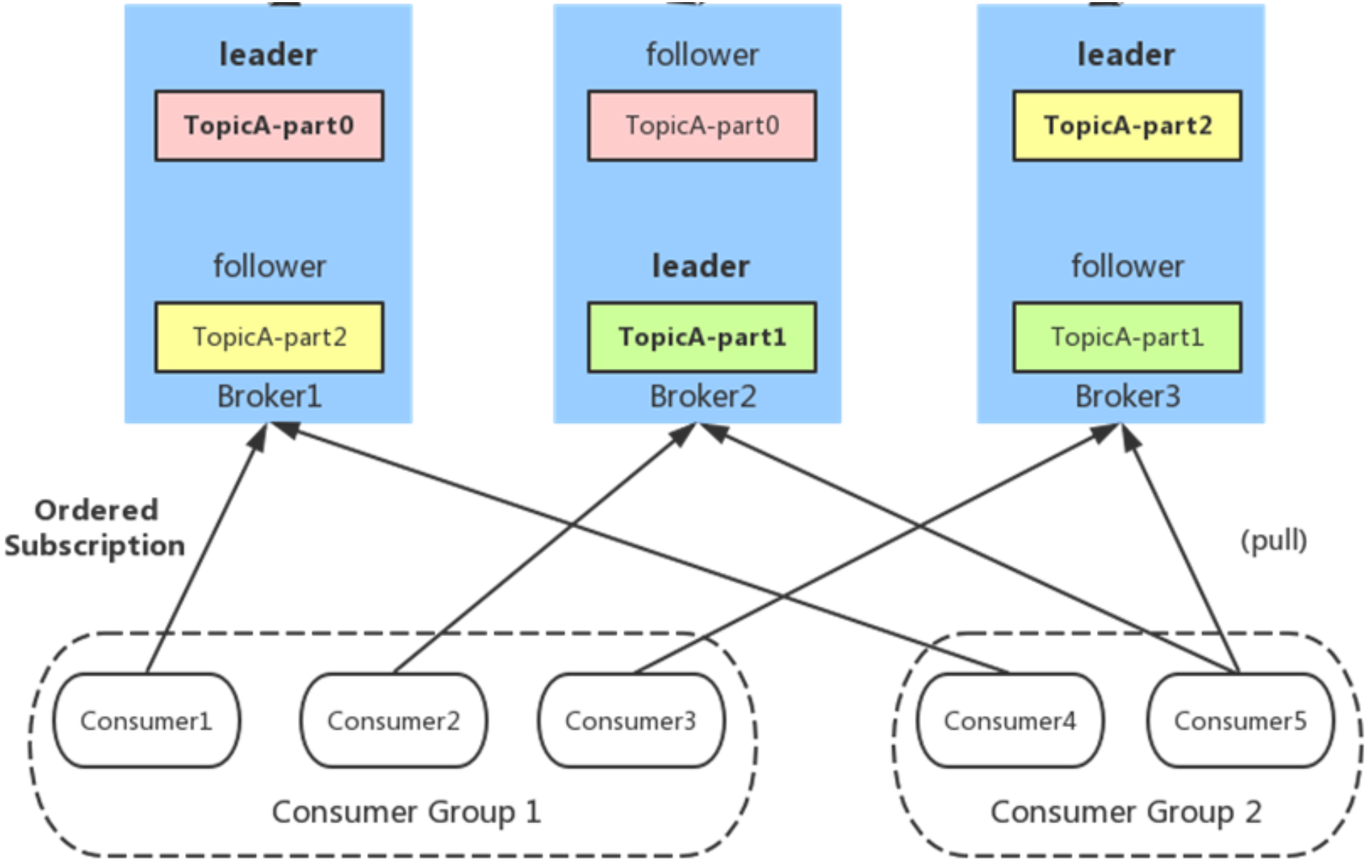
# 2、消费者设计
- 任何Consumer必须属于一个Consumer Group
- 同一Consumer Group中的多个Consumer实例,
不同时消费同一个partition,等效于队列模式Consumer Group 1的三个Consumer实例分别消费不同的partition的消息
- 不同Consumer Group的Consumer实例
可以同时消费同一个partition,等效于发布订阅模式- Consumer1和Consumer4,同时消费TopicA-part0的消息(不同Group)
- partition内消息是有序的,Kafka不删除已消费的消息
# 3、队列模式
- 队列模式,指Kafka保证
同一Consumer Group中只有一个Consumer会消费某条消息
1)保证不重复消费一个partition的数据只会被一个消费者消费
但是一个消费者可以消费多个 partition
对消息分配以partition为单位,而非以条消息作为分配单元
2)Consumer比 partition 多是没有意义的- 如果Consumer的数量与partition数量相同,则正好一个Consumer消费一个partition的数据
- 而如果Consumer的数量多于partition的数量时,会有部分Consumer无法消费该Topic下任何一条消息
设计的优势是:
- 每个Consumer不用都跟大量的broker通信,减少通信开销
- 同时也降低了分配难度,实现也更简单
- 可以保证
每个partition里的数据可以被Consumer有序消费
设计的劣势是:
- 无法保证同一个Consumer Group里的Consumer均匀消费数据
- 且在Consumer实例多于partition个数时导致有些Consumer会饿死
Consumer Rebalance(重平衡)指发生在消费者的数量变化(增减消费者)时,进行partition重新分配
假设Topic它有4个Partition(P0,P1,P2,P3),有一个消费者组,开始只有一个消费者C1
初始状态:所有的Partition都分配给C1,所以C1消费P0,P1,P2和P3
现在假设有一个新的消费者C2加入到消费者组中,此时Kafka会触发一次Rebalance
在Rebalance过程中,首先,
Kafka会停止所有的消费者的数据读取,然后重新计算Partition到消费者的分配在这个例子中,Rebalance的结果可能是:C1消费P0和P1,C2消费P2和P3
最后,消费者会根据新的分配结果,开始消费新分配到的Partition
注:
- Rebalance过程中会停止数据的读取,这可能会导致消费的延迟
- 因此,虽然Rebalance可以保证Partition的均匀分配,但是频繁的Rebalance可能会对性能产生影响
# 4、找Partition Leader
生产者和消费者如何确定 Partition Leader 在那个 Broker
Kafka中,生产和消费消息时,并不是随便选择一个Broker发送请求
而是通过一种叫做
元数据请求的方式来找到自己需要的Partition Leader下面以消费者为例说明(生产者也是这个流程)
1)Producer发送元数据请求- 消费者启动后,会向Kafka集群发送元数据请求(Metadata Request)给任意Broker
2)Broker 返回元数据响应- Broker收到元数据请求后,会返回元数据响应(Metadata Response)
- 响应中包含了集群中所有Topic和Partition的信息,包括每个Partition的Leader是哪个Broker
3)Producer找到Partition Leader- 消费者收到元数据响应后,就知道了每个Partition的Leader在哪个Broker
- 然后就可以直接向这个Broker发送数据拉取请求(Fetch Request)
4)Partition Leaer改变- 如果在消费过程中,某个Partition的Leader发生了变化
- 消费者在发送Fetch Request时会收到一个Leader Not Available的错误
- 此时消费者会再次发送Metadata Request来更新元数据
# 4、Replication 副本
# 1、副本概述
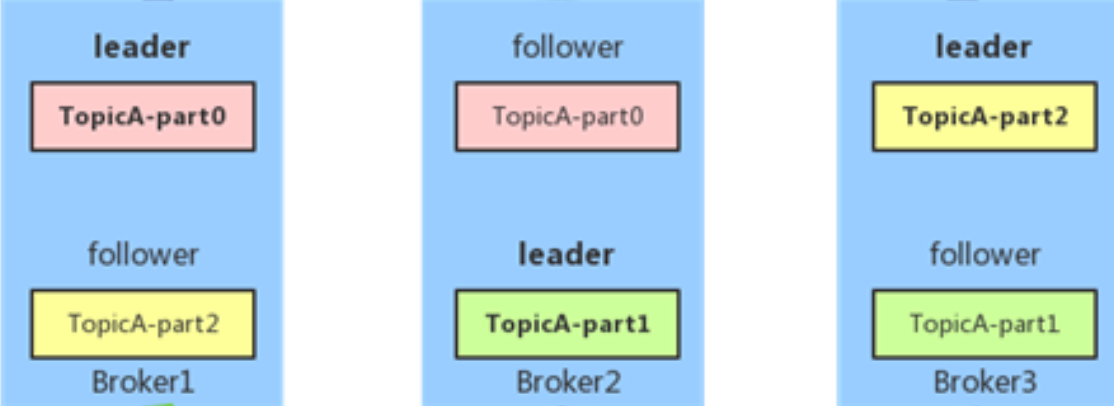
Replication解释在Kafka中,每个Topic的数据被分割成多个Partition
每个
Partition都可以在多个Broker上进行复制,这就是Kafka的Replication(副本)设计副本分为两种:Leader副本和Follower副本
Leader副本负责处理所有的读写请求,而Follower副本则从Leader副本那里复制数据- 如果Leader副本发生故障,就会从Follower副本中选举出新的Leader
但是一般消费者读写都只会使用 Leader 副本,而Followers仅提供容错性和可靠性
- 一致性:副本中可能没有同步到 Leader 的最新数据
- 负载均衡:一个topic被分成多个partition,每个partition分布在不同broker中可以负载均衡
Replication举例说明当一个Producer向一个Topic的Partition写入消息时
这个消息首先会被
发送到该Partition的Leader副本所在的BrokerLeader副本接收到消息后,将
消息写入到本地的日志Follower副本会从Leader副本那里拉取数据,将消息复制到自己的日志当
所有的Follower副本都成功复制了消息,这个消息就被认为是已提交(committed)的只有已提交的消息才能被Consumer消费
如果Leader副本发生故障,Kafka会从ISRs(副本)中选举出新的Leader
In-Sync-Replica(简称ISR)在Kafka中,
ISR是指那些与Leader副本保持同步的Follower副本ISR是Kafka保证数据可靠性的一个重要机制
只有当消息被所有ISR中的副本都写入后,这条消息才被认为是"已提交"的(才可以被消费)
例:
Topic一个Partition有3个副本,R1是Leader副本,R2和R3是Follower副本
在开始时,R1,R2和R3都是同步的,所以
ISR={R1, R2, R3}假设R3出现了问题,不能及时从R1那里拉取数据
此时,R3就会被从ISR中移除,
ISR变为{R1, R2}当有新消息发送时,{R1, R2}写入就算是"已提交”
注:Kafka的Zookeeper维护了每个partition的ISR信息
# 2、副本复制
1)保证消息写入副本- partition的
ISR replicas会定时从leader批量复制数据 - 当所有ISR replicas都返回ack确认写入成功后,leader标记消息为
committed,通知Producer生产成功 - 若某follower超时未响应ack,则被leader剔除出ISR
- 消息
committed后,Consumer才能消费
- partition的
2)副本数据同步原理(不是绝对可靠的不丢失数据)ISR机制:兼顾同步与异步,提升吞吐量,是Kafka的高吞吐关键同步复制:要求所有follower都完成复制才标记为committed,会降低吞吐量异步复制:只要leader写入log就认为committed,但如果leader故障,可能丢数据- Kafka使用ISR均衡了数据可靠性和吞吐量
follower从leader批量复制数据,数据到内存即返回ack,提高性能,但存在一定数据丢失风险
# 3、数据可靠性
1)副本复制(Replication)- Kafka的每个Topic可以被分为多个分区,
每个分区可以有多个副本 - 副本中的Leader负责处理所有客户端请求(包括读和写),Follower副本则从Leader副本复制数据
- 如果Leader副本出现问题,就会从Follower副本中选举出新的Leader,以此来保证数据的可用性
- Kafka的每个Topic可以被分为多个分区,
2)In-Sync Replicas (ISR)- ISR是一组和leader副本保持同步的follower副本
- 只有当
消息被所有ISR中的副本都写入后,这条消息才可以被消费 - 通过ISR,Kafka可以在副本出现问题时,仍然保证数据的可靠性
3)Acknowledgements(消息确认)- 生产者在写入消息时,可以等待Broker的确认
- 生产者
可以设置等待所有ISR中的副本都确认后再返回,这样可以进一步保证数据的可靠性
4)日志持久化- Kafka将所有的消息都保存在日志中,并且可以通过配置将
日志持久化到磁盘 - 即使在系统故障的情况下,只要磁盘数据没有损坏,消息就不会丢失
- Kafka将所有的消息都保存在日志中,并且可以通过配置将
# 5、高可用原理
# 1、partition高可用
leader选过程
当
leader副本故障且与Zookeeper断开心跳连接时,Zookeeper将其从ISR列表移除并触发选举Zookeeper从剩余的ISR列表中选择新的leader,默认策略为
选择副本ID最小的节点选举策略可通过
unclean.leader.election.enable参数配置- 若为
true,允许非ISR副本作为leader,可能导致数据丢失 - 若为
false(推荐生产环境),仅允许ISR副本成为leader,以确保数据完整性
- 若为
# 2、broker高可用
Zookeeper负责选举一个broker作为controller,负责全局的partition leader选举、topic管理、partition副本重新分配等- controller监控所有broker状态,
若broker宕机,其Zookeeper临时节点消失,controller为该broker上的partition重新分配leader 若controller宕机,Zookeeper会选出新的controller并继续进行leader分配
# 6、kafka 可靠性
# 1、消息投递可靠性
消息确认指 producer要求leader partition 收到确认的副本个数
1)acks 配置acks = 0:Producer不等待 Broker 响应,最高吞吐,但可能丢失消息acks = 1:Producer 在leader partition 收到消息后得到确认acks = -1:所有备份的 partition收到消息后 Producer 得到确认,提供最高可靠性
2)事务性消息- 自 Kafka 0.11 引入,实现
Exactly-Once语义 - Producer 使用事务性消息,Consumer 通过幂等性和事务实现 Exactly-Once
- 自 Kafka 0.11 引入,实现
# 2、重复消费
1)唯一标识符(Message Key)- 消息包含唯一 Key,Kafka 保证相同 Key 的消息进入同一分区,消费时根据 Key 防止重复
2)消费者位移(Consumer Offset)- Kafka会为
每个消费者维护一个位移(Offset),表示消费者已经消费的消息位置 - 当消费者重启或者发生故障时,可以根据位移的信息来恢复消费进度
- Kafka会为
3)消费者组(Consumer Group)每个消息只会被消费者组中的一个消费者消费,这样可以实现负载均衡和水平扩展
- 4)幂等性和Exactly-Once语义
生产者可以通过设置幂等性参数,确保相同Key的消息只会被写入一次- 即使发生重试或者重发也不会导致消息的重复
- At most once:消息可能会丢失,但不会重复传输
- At least once:消息不会丢失,但可能重复传输
Exactly once:消息保证会被传输一次且仅传输一次
出现重复消费场景举例
1)消费者提交位移失败- 当消费者在
消费消息后,未能成功提交位移给Kafka时
- 当消费者在
2)消费者组重平衡当消费者组发生重平衡时,Kafka会重新分配分区给消费者- 在重平衡期间,
消费者可能会同时消费属于不同分区的消息,从而导致重复消费
3)消费者异常重启- 当消费者发生异常重启时,可能会导致
消费者重新从上次提交的位移处开始消费
- 当消费者发生异常重启时,可能会导致
4)生产者消息重试- 当生产者发送消息时发生错误,生产者可能会进行消息的重试
# 3、Exactly-Once
Exactly once:消息保证会被传输一次且仅传输一次- Exactly-Once语义在Kafka中是通过两个主要机制实现的
Producer端的幂等性(重复发送消息结果不变)事务性消息处理(实质实现了原子性,要么全部成功要么全部失败)
1)Producer端的幂等性- Producer 分配唯一 ID,消息带序列号,Broker 通过 ID 和序列号避免重复处理
2)事务性消息处理- Producer 可以将
多条消息和偏移量提交包含在一个事务中,保证消息处理的原子性
- Producer 可以将
- 实现Exactly-Once的具体流程如下
Producer
开始事务并发送消息Producer
结束事务,标记完成Kafka 将事务中的消息写入日志,消费者仅消费已提交事务中的消息,
确保每条消息仅处理一次
# 4、事务原理
- Kafka的事务支持确保了Producer发送到多个分区的消息以及Consumer消费的位移的原子性
初始化事务:Producer
生成唯一事务 ID发送消息:事务内的消息初始为“未决”,
消费者不可见位移提交:消费时提交位移,
确保消息发送和位移提交同一事务中提交/中止事务:
提交后消息对消费者可见,若中止事务则消息丢弃消费事务消息:
仅消费已提交的事务消息,确保消费一致性
# 7、Zookeeper
Zookeeper 是一个分布式、开放源码的分布式应用程序协调服务,是 Google 的 Chubby 开源实现
分布式应用程序可以基于它实现统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等工作
在基于 Kafka 的分布式消息队列中,Zookeeper 的作用有
Broker 注册、Topic 注册Producer 和 Consumer 负载均衡- 维护 Partition 与 Consumer 的关系
记录消息消费的进度以及 Consumer 注册
# 1、Broker注册到 ZK
- Zookeeper 是一个共享配置中心,我们可以将一些信息存放入其中,比如 Broker 信息,本质上就是
存放一个文件目录 - 这个配置中心是共享的,分布式系统的
各个节点都可以从配置中心访问到相关信息 - 同时,Zookeeper 还具有
Watch 机制,一旦注册信息发生变化,比如某个注册的 Broker 下线 - Zookeeper 就会
删除与之相关的注册信息,其它节点可以通过Watch 机制监听到这一变化,进而做出响应
# 2、Topic注册到 ZK
所有 Topic 信息都注册在 Zookeeper 的节点路径/brokers/topics/{topic_name}分区的
Leader 副本接收 Producer 消息后,会同步数据到其他副本,副本发生故障时,会重新选举 Leader在 Kafka 中,所有 Topic 与 Broker 的对应关系都由 Zookeeper 来维护
在 Zookeeper 中,通过建立专属的节点来存储这些信息,其路径为
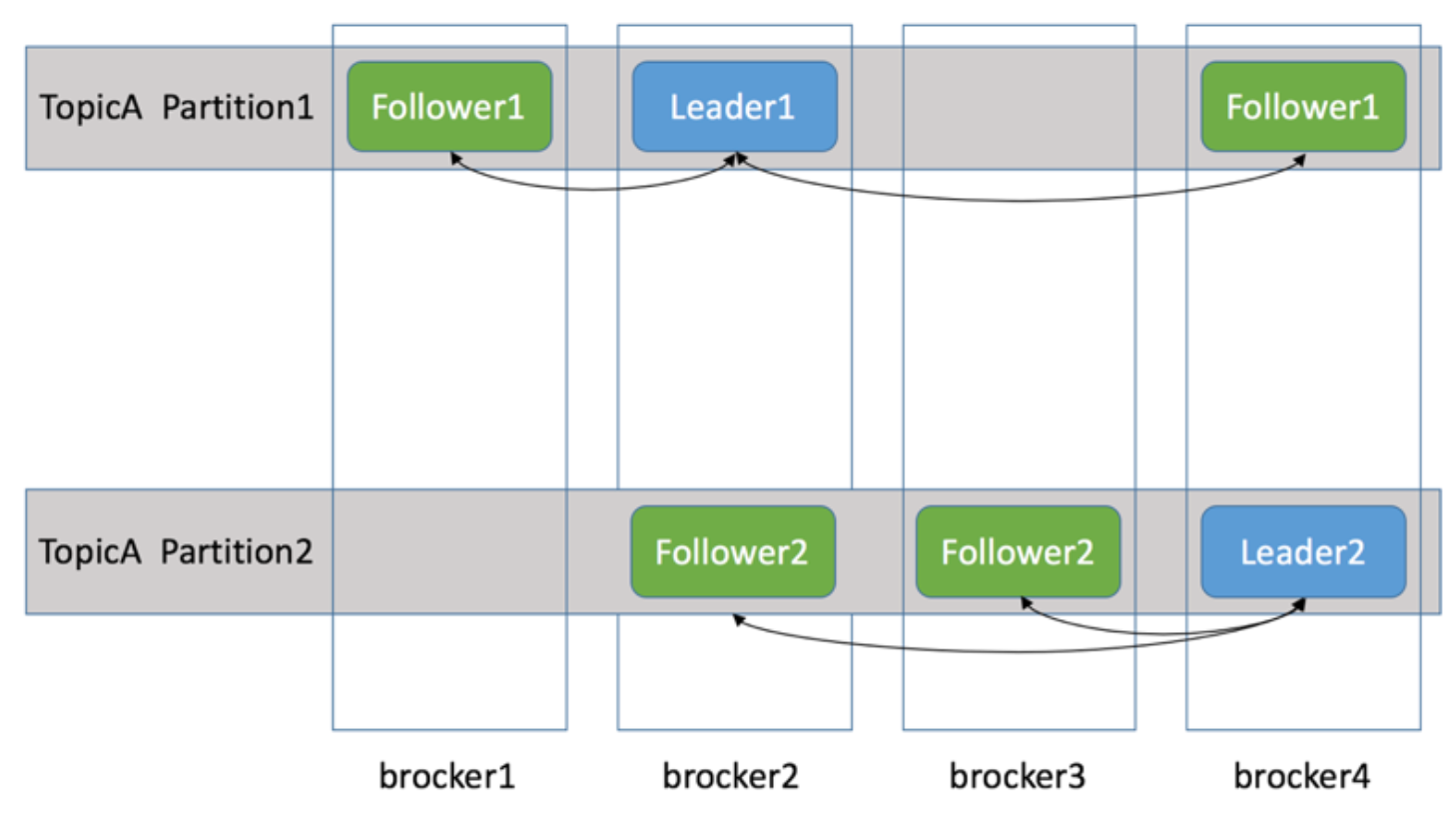
/brokers/topics/{topic_name}下图中 TopicA 被分为两个Partition(Partition1 和 Partition2)
- Partition1有一个Leader 副本在 broker2 中
- 其余两个副本分别在:broker1 和 broker4
当 Producer Push 的消息写入 Partition(分区)时,作为 Leader 的 Broker(Kafka 节点)会将消息写入自己的分区
同时还会将此消息复制到各个 Follower,实现同步
如果某个 Follower 挂掉,Leader 会再找一个替代并同步消息
如果 Leader 挂了,Follower 们会选举出一个新的 Leader 替代,继续业务,这些都是由 Zookeeper 完成的
# 3、Consumer Group注册
与 Broker、Topic 注册类似,Consumer Group 注册本质上也是在 Zookeeper 中创建专属的节点,以记录相关信息
其路径为
/consumers/{group_id}的一个目录既然是目录,在记录信息时,就可以根据信息的不同,进一步创建子目录(子节点),分别记录不同类别的信息
对于 Consumer Group 而言,有三类信息需要记录,因此,
/consumers/{group_id}下还有三个子目录ids:Consumer Group 中有多个 Consumer,ids 用于记录这些 Consumerowners:记录该 Consumer Group 可消费的 Topic 信息offsets:记录 owners 中每个 Topic 的所有 Partition 的 Offset
- Consumer 注册
- 原理同 Consumer Group 注册,不过需要注意的是,其节点路径比较特殊
- 需在路径
/ consumers/{group_id}/ids下创建专属子节点,它是临时的 - 比如,某 Consumer 的临时节点路径为
/ consumers/{group_id}/ids/my_consumer_for_test-1223234-fdfv1233df23
- 负载均衡
- 我们知道,对于一条消息,订阅了它的 Consumer Group 中只能有一个 Consumer 消费它
- 那么就存在一个问题:一个 Consumer Group 中有多个 Consumer,如何让它们尽可能均匀地消费订阅的消息呢(也就是负载均衡)
- 这里不讨论实现细节,但要实现负载均衡,实时获取 Consumer 的数量显然是必要的
- 通过 Watch 机制监听
/ consumers/{group_id}/ids下子节点的事件便可实现
# 4、Producers 负载均衡
为了负载均衡和避免连锁反应,Kafka 中,
同一个 Topic 的 Partition 会尽量分散到不同的 Broker 上那么,如何将消息均衡地 Push 到各个 Partition 呢?这便是 Producers 负载均衡的问题
为了负载均衡,
Producers会通过Watcher 机制监听 Brokers 注册节点的变化一旦
Brokers 发生变化,如增加、减少,Producers 可以收到通知并更新自己记录的 Broker 列表Producer 向 Kafka 集群 Push 消息的时候,
必须指定 Topic,不过,Partition 却是非必要的通常有两种方式用于指定 Partition
低级接口
- 在指定 Topic 的同时,需指定 Partition 编号(0、1、2……N),消息数据将被 Push 到指定的 Partition 中
高级接口
- 不支持指定 Partition,隐藏相关细节,内部则采用轮询
- 对传入 Key 进行 Hash 等策略将消息数据均衡地发送到各个 Partition
# 5、Consumer 负载均衡
- 高级 API 自动分配 Topic 下的 Partition,低级 API 需手动指定
对 Topic 和 Consumer 进行排序后,将 Partition 均匀分配到各 Consumer,确保负载均衡
# 6、记录消费进度 Offset
- Kafka 的 Consumer 采用 Pull 模式消费消息,需记录消费的 Offset 避免重复消
- Kafka 2.0 后,Offset 信息不再存储在 Zookeeper,而是存储于 Kafka 内部的
__consumer_offsetsTopic
# 7、记录Partition Consumer关系
- Partition 与 Consumer 的关系通过
/consumers/{group_id}/owners/{topic}/{broker_id-partition_id}记录,重启时会进行更新 - 此路径为临时节点,Rebalance 时被删除,再按新的分配关系重建
# 8、全程解析
# 1、Producer发布消息
1)消息发布- Producer 根据
负载均衡算法选择 Partition,查找对应 Leader Broker - Producer 从 Zookeeper 的
/brokers/.../state节点找到该 Partition 的 Leader - Producer 将消息发送给该 Leader
- Producer 根据
2)Leader 写入- Leader Broker 写入消息到本地日志,Follower 从 Leader Pull 消息后发送 ACK
3)确认成功- Producer 接收到 ACK,确认消息发送成功
# 2、Broker存储消息
Topic 是逻辑概念,而 Topic 对应的Partition 则是物理概念,每个Partition 在存储层面都对应一个文件夹(目录)- 由于 Partition 并不是最终的存储粒度,
该文件夹下还有多个 Segment(消息索引和数据文件,它们是真正的存储文件)
# 3、Consumer消费消息
目前采用的高级 API,Consumer 在消费消息时,
只需指定 Topic 即可,API 内部实现负载均衡,并将 Offset 记录到 Zookeeper 上Consumer 采用 Pull 模式从 Broker 中读取数据,这是一种异步消费模式,与 Producer 采用的 Push 模式全然不同
Push 模式追求速度,越快越好,当然它取决于 Broker 的性能,而 Pull 模式则是追求自适应能力,Consumer 根据自己的消费能力消费