14.百亿规模浏览记录
14.百亿规模浏览记录
# 00.系统介绍
# 1、系统介绍
- 浏览记录系统主要用来记录京东用户的实时浏览记录,并提供实时查询浏览数据的功能
- 在线用户访问一次商品详情页,浏览记录系统就会记录用户的一条浏览数据,并针对该浏览数据进行商品维度去重等一系列处理并存储
- 然后用户可以通过我的京东或其他入口查询用户的实时浏览商品记录,实时性可以达到毫秒级
- 目前本系统可以为京东每个用户提供最近200条的浏览记录查询展示
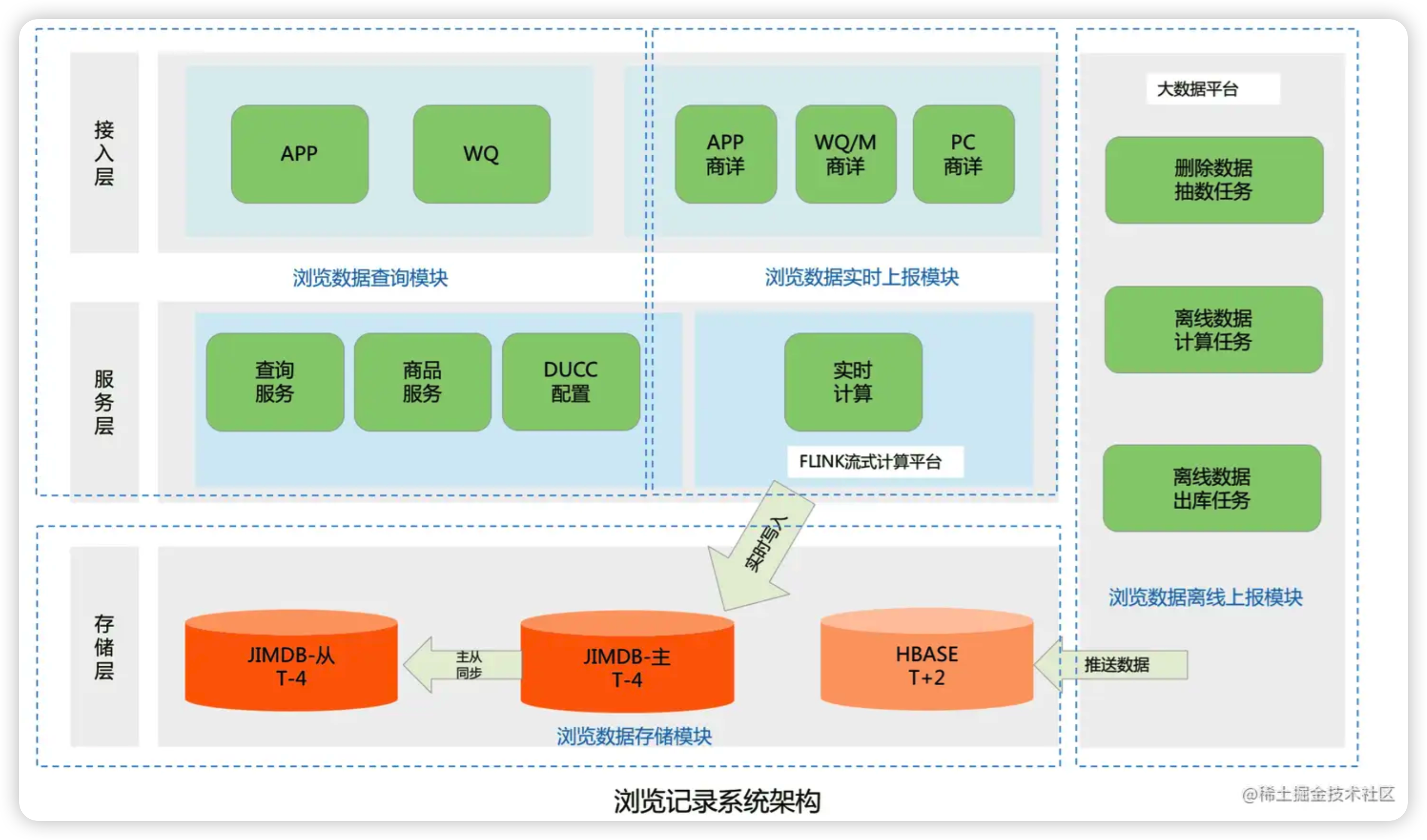
# 2、系统架构
整个系统架构主要分为四个模块
浏览数据存储模块- 主要用来存储京东用户的浏览历史记录,目前京东有近5亿的活跃用户
- 按照每个用户保留最少200条的浏览历史记录,需要设计存储近千亿条的用户浏览历史数据
浏览数据查询模块- 主要为前台提供微服务接口,包括查询用户的浏览记录总数量
- 用户实时浏览记录列表和浏览记录的删除操作等功能
浏览数据实时上报模块- 主要处理京东所有在线用户的实时PV数据,并将该浏览数据存储到实时数据库;
浏览数据离线上报模块- 主要用来处理京东所有用户的PV离线数据,将用户历史PV数据进行清洗
- 去重和过滤,最后将浏览数据推送到离线数据库中
# 01.数据存储模块设计
# 1、冷热数据存储
- JIMDB是京东自主研发的基于Redis的分布式缓存与高速键值存储服务
考虑到需要存储近千亿条的用户浏览记录,并且还要满足京东在线用户的毫秒级浏览记录实时存储和前台查询功能,我们将浏览历史数据进行了冷热分离
Jimdb纯内存操作,存取速度快,所以我们将用户的
(T-4)浏览记录数据存储到Jimdb的内存中,可以满足京东在线活跃用户的实时存储和查询而(T+4)以外的离线浏览数据则
直接推送到Hbase中,存储到磁盘上,用来节省存储成本如果有不活跃的用户查询到了冷数据,则
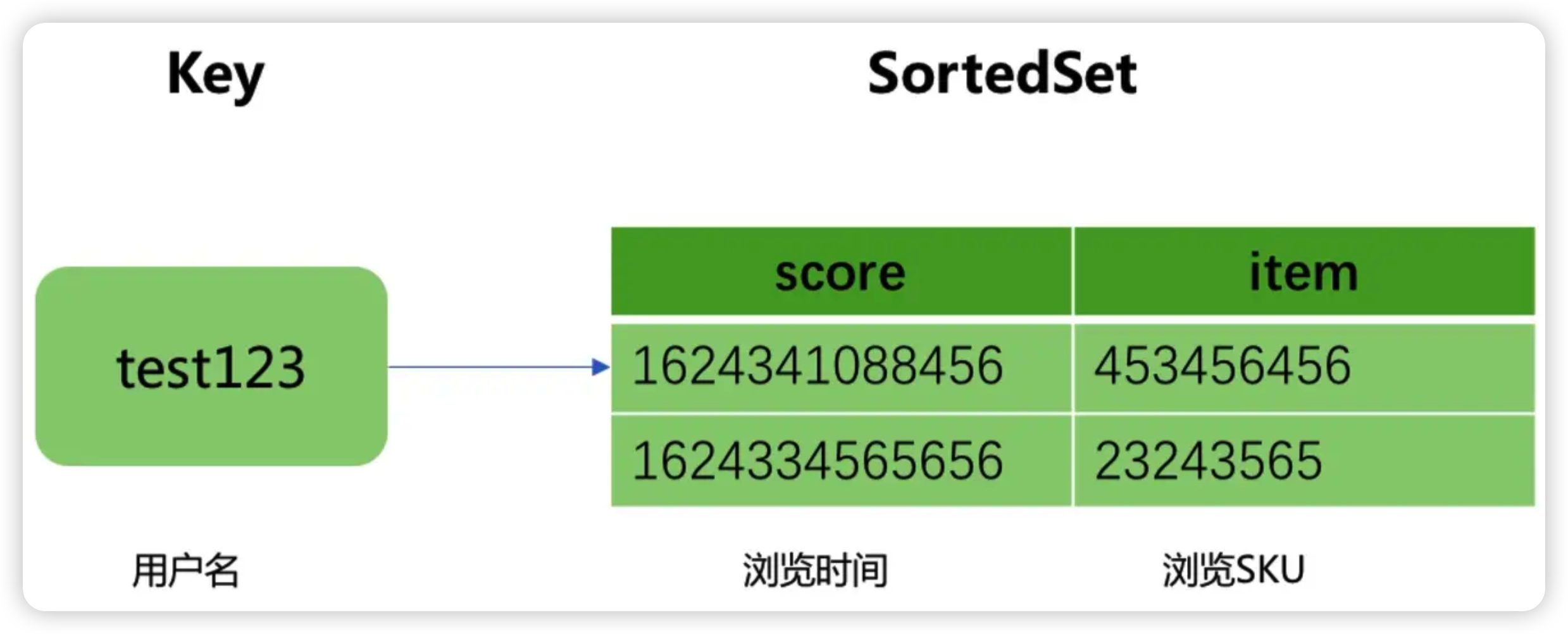
将冷数据复制到Jimdb中,用来提高下一次的查询性能热数据采用了JIMDB的有序集合来存储用户的实时浏览记录,使用用户名做为有序集合的KEY
浏览商品SKU作为有序集合的元素,浏览商品的时间戳作为元素的分数,然后针对该KEY设置过期时间为4天
# 2、过期时间选择4天
1)热数据存储
这是因为大数据平台离线浏览数据都是T+1上报汇总的,等开始处理用户的离线浏览数据的时候已经是第二天
在加上业务流程处理和数据清洗过滤过程,到最后推送到Hbase中,也需要执行消耗十几个小时
热数据的过期时间最少需要设置2天,考虑到大数据任务执行失败重试过程,所以热数据过期时间设置为4天
2)冷数据存储
所以当
用户4天内都没有浏览新商品时,用户查看的浏览记录则是直接从Hbase中查询展示冷数据使用用户名作为KEY,用户浏览商品和浏览时间对应Json字符串做为Value进行存储
存储时需要保证用户的浏览顺序,避免进行二次排序
3)数据倾斜问题
其中使用用户名做KEY时,由于大部分用户名都有相同的前缀,会出现数据倾斜问题
所以我们针对用户名进行了MD5处理,然后
截取MD5后的中间四位作为KEY的前缀,从而解决了Hbase的数据倾斜问题最后在针对KEY设置过期时间为62天,实现离线数据的过期自动清理功能
数据倾斜- 数据倾斜是指在分布式系统中某些节点或分片上的数据量远远超过其他节点或分片的现象
- 这可能导致性能不均衡,某些节点负载过重,而其他节点相对空闲
- 数据倾斜可能影响整个系统的性能和稳定性,因此需要谨慎处理
4)存储结构

# 02.查询服务模块设计
查询服务模块主要包括三个微服务接口,包括查询用户浏览记录总数量,查询用户浏览记录列表和删除用户浏览记录接口
# 1、限流防刷
- 基于Guava的RateLimiter限流器和Caffeine本地缓存实现方法
全局、调用方和用户名三个维度的限流 - 具体策略是当调用发第一次调用方法时,会生成对应维度的限流器,并将该限流器保存到Caffeine实现的本地缓存中
- 然后设置固定的过期时间,当下一次调用该方法时,生成对应的限流key然后从本地缓存中获取对应的限流器
- 该限流器中保留着该调用方的调用次数信息,从而实现限流功能
# 2、查询用户浏览记录总数量
- 首先查询用户浏览记录总数缓存,如果缓存命中,直接返回结果
- 如果缓存未命中则需要从Jimdb中查询用户的实时浏览记录列表,然后在批量补充商品信息
- 由于用户的浏览SKU列表可能较多,此处可以进行分批查询商品信息,分批数量可以动态调整,防止因为一次查询商品数量过多而影响查询性能
- 由于前台展示的浏览商品列表需要针对同一SPU商品进行去重,所以需要补充的商品信息字段包括商品名称、商品图片和商品SPUID等字段
- 针对SPUID字段去重后,在判断是否需要查询Hbase离线浏览数据
- 如果去重后的时候浏览记录数量已经满足系统设置的用户最大浏览记录数量,则不再查询离线记录
- 如果不满足则继续查询离线的浏览记录列表,并与用户的实时浏览记录列表进行合并,并过滤掉重复的浏览SKU商品
- 获取到用户完整的浏览记录列表后,在过滤掉用户已经删除的浏览记录,然后
count列表的长度,并与系统设置的用户最大浏览记录数量做比较取最小值 - 就是该用户的浏览记录总数量,获取到用户浏览记录总数量后可以根据缓存开关来判断是否需要异步写入用户总数量缓存

# 03. 浏览数据实时上报
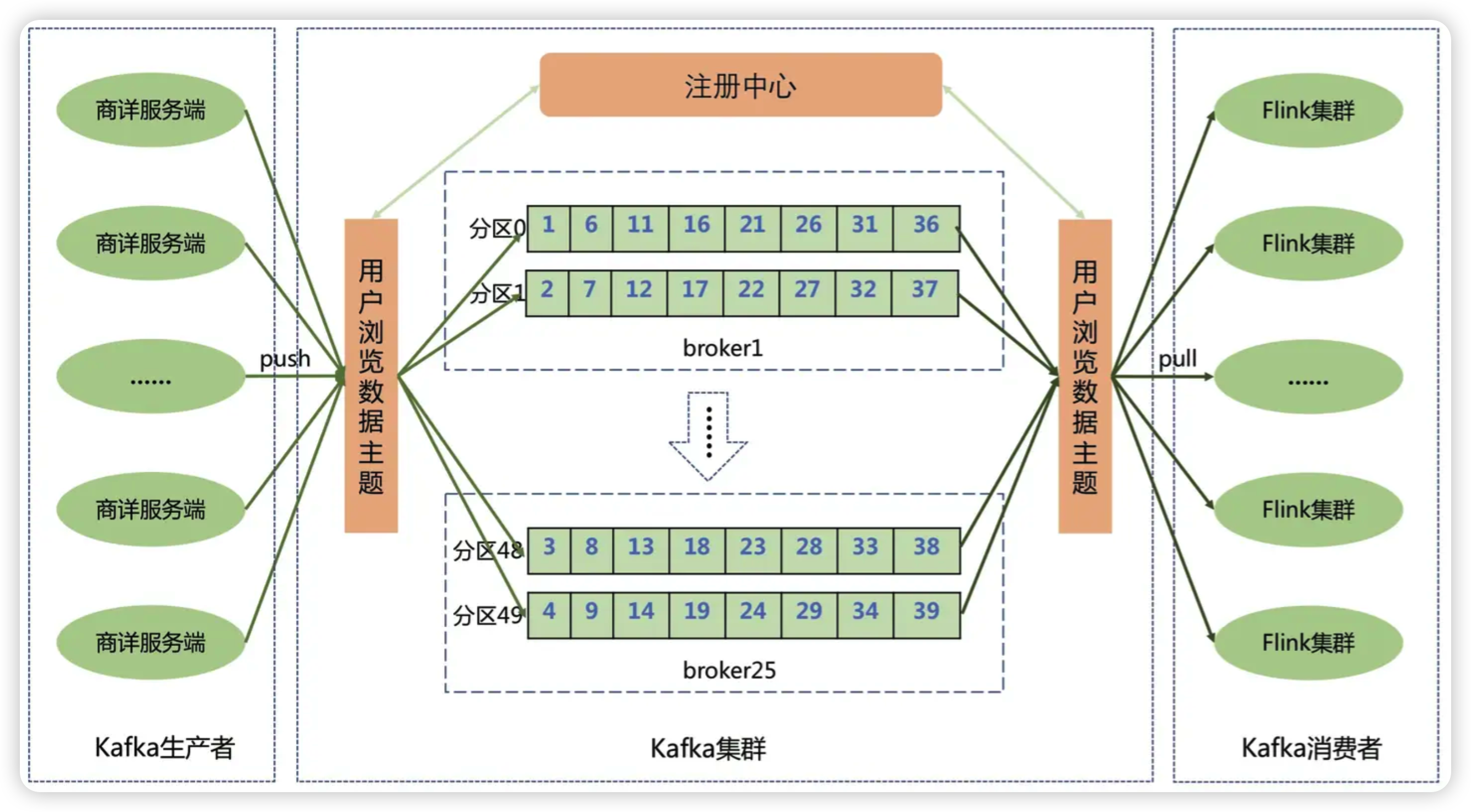
# 1、上报数据流程图
- 商详服务端将用户的实时浏览数据通过Kafka客户端上报到Kafka集群的消息队列中
- 为了提高数据上报性能,用户浏览数据主题分成了50个分区
- Kafka可以将用户的浏览消息均匀的分散到50个分区队列中,从而大大提升了系统的吞吐能力
# 2、为什么选Kafka
1)
Kakfa的特性
高吞吐、低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒
高伸缩性: 每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中
持久性、可靠性:
- Kafka能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失
- Kafka底层的数据存储是基于Zookeeper存储的,Zookeeper我们知道它的数据能够持久存储
容错性: 允许集群中的节点失败,某个节点宕机,Kafka集群能够正常工作
高并发: 支持数千个客户端同时读写
2)
Kafka为什么这么快
Kafka通过零拷贝原理来快速移动数据,避免了内核之间的切换
Kafka可以将数据记录分批发送,从生产者到文件系统到消费者,可以端到端的查看这些批次的数据
批处理的同时更有效的进行了数据压缩并减少I/O延迟
Kafka采取顺序写入磁盘的方式,避免了随机磁盘寻址的浪费
基本实现了毫秒级的处理能力,方法性能TP999达到了11ms
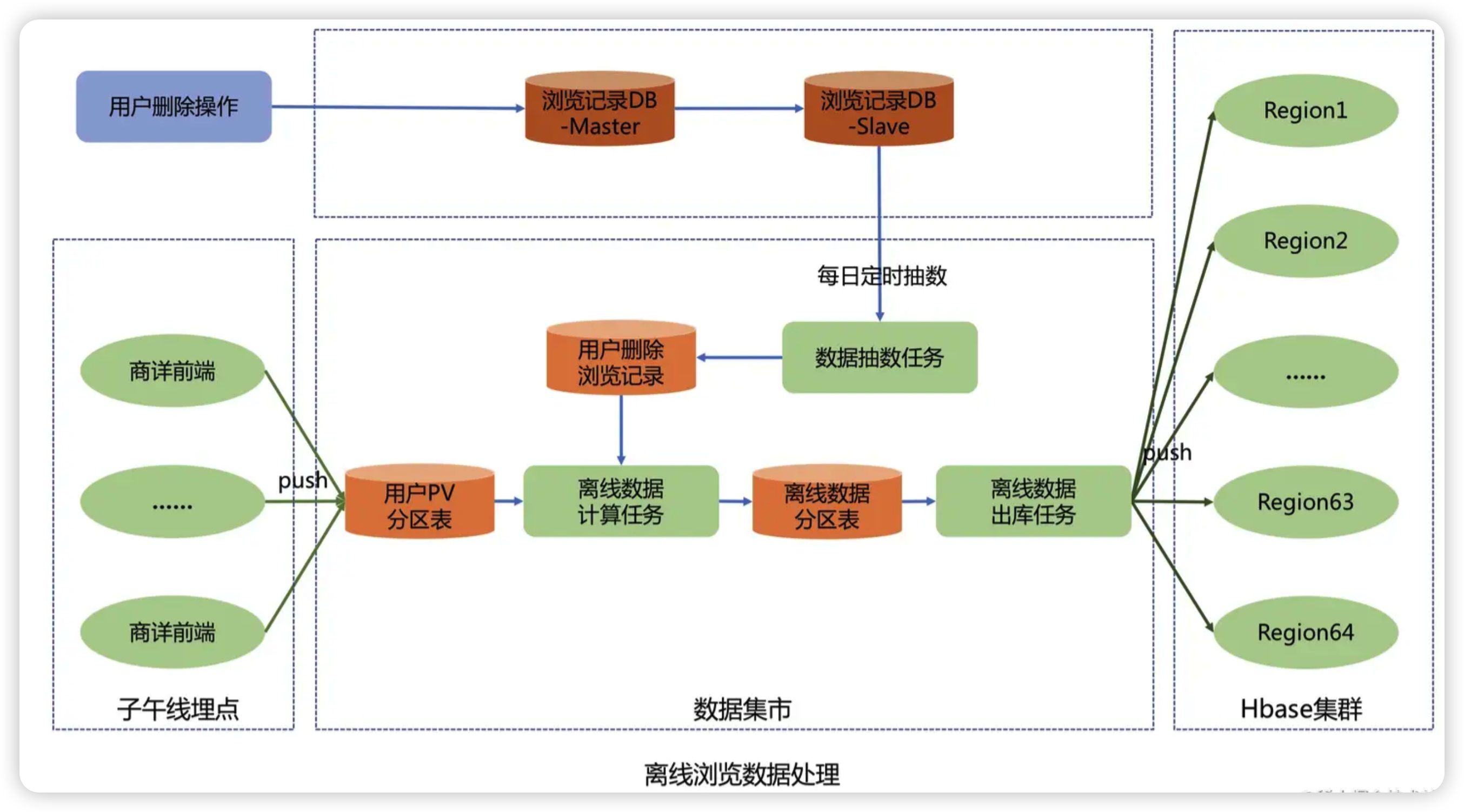
# 04.浏览数据离线上报
商详前端通过子午线的API将用户的PV数据进行上报,子午线将用户的PV数据写入到数据集市的用户PV分区表中
数据抽数任务每天凌晨2点33分从浏览记录系统Mysql库的用户已删除浏览记录表抽数到数据集市,并将删除数据写入到用户删除浏览记录表
离线数据计算任务每天上午11点开始执行,先从用户PV分区表中提取近60天、每人200条的去重数据
然后根据用户删除浏览记录表过滤删除数据,并计算出当天新增或者删除过的用户名,最后存储到离线数据分区表中
离线数据出库任务每天凌晨2点从离线数据分区表中将T+2的增量离线浏览数据经过数据清洗和格式转换,将T+2活跃用户的K-V格式离线浏览数据推送到Hbase集群