 09.mutex锁原理
09.mutex锁原理
# 01.Mutex
# 1、mutex结构体
- 源码包src/sync/mutex.go:Mutex定义了互斥锁的数据结构
type Mutex struct {
state int32 // 表示互斥锁的状态,比如是否被锁定等
sema uint32 // 表示信号量,协程阻塞等待该信号量,解锁的协程释放信号量从而唤醒等待信号量的协程
}
1
2
3
4
2
3
4
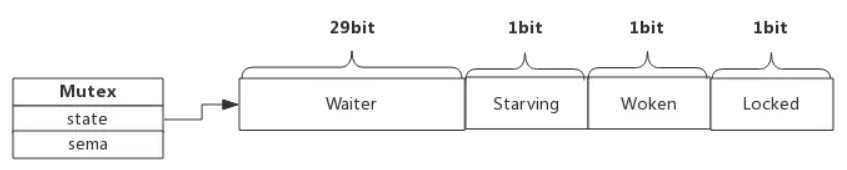
我们看到Mutex.state是32位的整型变量,内部实现时把该变量分成四份,用于记录Mutex的四种状态
下图展示Mutex的内存布局
Locked: 表示该Mutex是否已被锁定,0:没有锁定 1:已被锁定Woken: 表示是否有协程已被唤醒,0:没有协程唤醒 1:已有协程唤醒,正在加锁过程中Starving:表示该Mutex是否处理饥饿状态, 0:没有饥饿 1:饥饿状态,说明有协程阻塞了超过1msWaiter: 表示阻塞等待锁的协程个数,协程解锁时根据此值来判断是否需要释放信号量
# 2、简单加锁
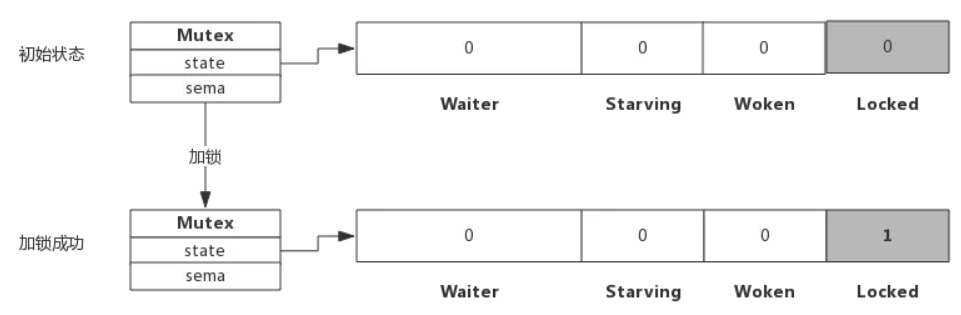
假定当前只有一个协程在加锁,没有其他协程干扰,那么过程如下图所示
加锁过程会去判断Locked标志位是否为0,如果是0则把Locked位置1,代表加锁成功
从上图可见,加锁成功后,只是Locked位置1,其他状态位没发生变化
# 3、加锁被阻塞
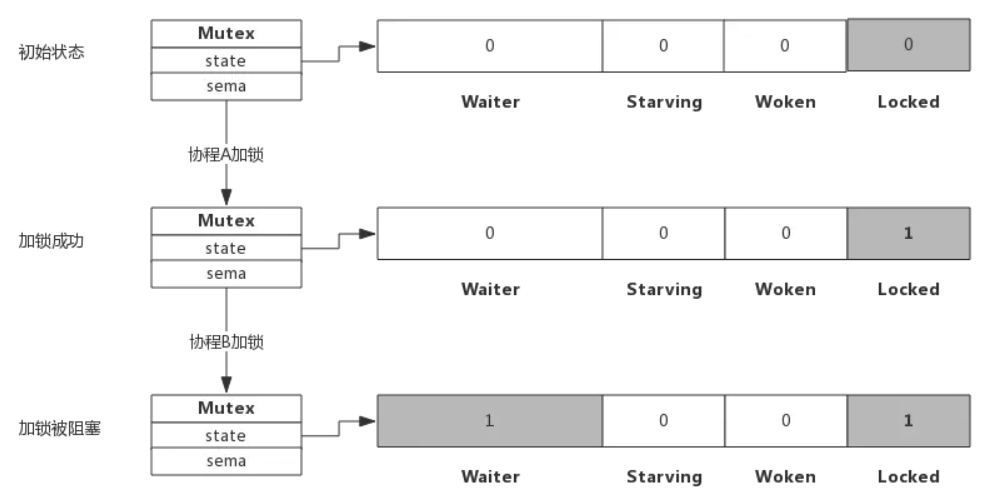
- 假定加锁时,锁已被其他协程占用了,此时加锁过程如下图所示
- 当协程B对一个已被占用的锁再次加锁时,Waiter计数器增加了1
- 此时协程B将被阻塞,直到Locked值变为0后才会被唤醒
# 4、解锁并唤醒协程
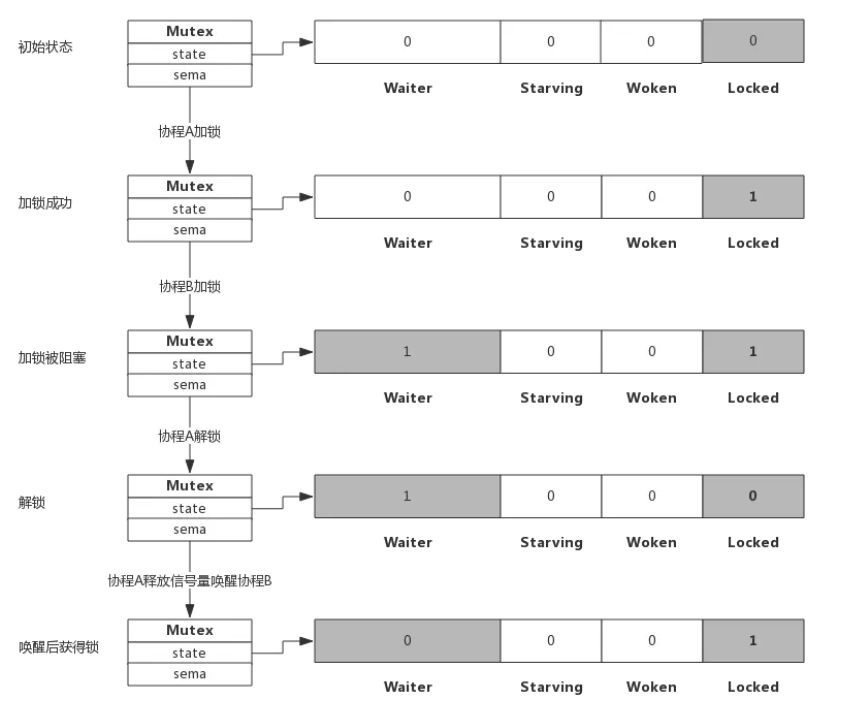
假定解锁时,有1个或多个协程阻塞,此时解锁过程如下图所示:
协程A解锁过程分为两个步骤,一是把Locked位置0,二是查看到Waiter>0
所以释放一个信号量,唤醒一个阻塞的协程,被唤醒的协程B把Locked位置1,于是协程B获得锁
# 5、自旋过程
加锁时,如果当前Locked位为1,说明该锁当前由其他协程持有,尝试加锁的协程并不是马上转入阻塞
而是会持续的探测Locked位是否变为0,这个过程即为自旋过程
自旋时间很短,但如果在自旋过程中发现锁已被释放,那么协程可以立即获取锁此时即便有协程被唤醒也无法获取锁,只能再次阻塞
自旋的好处是,当加锁失败时不必立即转入阻塞,有一定机会获取到锁,这样可以避免协程的切换
自旋条件
- 自旋次数要足够小,通常为4,即自旋最多4次
- CPU核数要大于1,否则自旋没有意义,因为此时不可能有其他协程释放锁
- 协程调度机制中的Process数量要大于1,比如使用GOMAXPROCS()将处理器设置为1就不能启用自旋
- 协程调度机制中的可运行队列必须为空,否则会延迟协程调度
# 02.原子操作
# 1、sync/atomic
- Go语言的
sync/atomic包提供了一组原子操作,保证要么都执行,要么都不执行 atomic包中的原子操作则由**底层硬件指令**直接提供支持,这些指令在执行的过程中是不允许中断的
# 2、atomic 与 mutex 区别
- 使用目的:
互斥锁是用来保护一段逻辑,原子操作用于对一个变量的更新保护
Mutex:
- 在Go中,
sync.Mutex用于保护共享资源的并发访问,防止数据竞争(data race) - Mutex是通过
操作系统的调度器来实现的 - 当一个线程获取了Mutex时,其他尝试访问相同资源的线程会被阻塞,直到Mutex被释放
- 这个过程涉及到操作系统的调度机制,可能引发上下文切换,导致一定的性能开销
- 在Go中,
atomic:
- 相比之下,
atomic的操作完全依赖于CPU提供的原子性指令 - 它们
不需要操作系统参与,因此称为锁自由(lock-free) - 硬件提供的原子性指令能确保操作在多核处理器环境中不会被中断,从而实现并发安全
- 相比之下,
# 3、底层硬件指令
- 不同的平台和处理器架构可能有不同的原子操作指令和实现方式
- Go的
sync/atomic包在不同平台上会做相应的适配,以利用平台提供的最优原子操作支持
Compare-and-Swap (CAS):- 这是最常用的原子指令,
比较变量的当前值是否与期望值相同,如果相同则交换新值 - 这种操作是原子的,即在比较和交换的过程中,其他线程无法访问这个变量
- Go中的
atomic.CompareAndSwapXXX就是通过这个指令实现的
- 这是最常用的原子指令,
Fetch-and-Add (FAA):- 这是一种在硬件级别实现的加法操作,能够以原子的方式读取变量的值并加上一个给定的值
- 在Go中,对整数的原子加法操作(如
atomic.AddInt32,atomic.AddInt64)就是通过FAA指令实现的
Load-Link/Store-Conditional (LL/SC):- 这是另一种原子操作实现方式,主要用于部分RISC架构的CPU
LL用于加载一个值并监视它是否被其他处理器修改,SC用于条件性地存储这个值
LOCK前缀指令:- 在x86架构中,很多原子操作通过
LOCK前缀来实现,例如LOCK XADD用于加法操作,LOCK CMPXCHG用于比较交换操作 - 这个
LOCK前缀指令告诉处理器在执行该指令时锁定总线,确保其他处理器在此期间无法访问共享变量
- 在x86架构中,很多原子操作通过
- 示例:Compare-And-Swap (CAS) 实现
- 读取当前值,比较当前值是否等于期望值
- 如果相等,则将当前值替换为新值,并返回
true- 如果不相等,则不做任何操作,返回
false
var counter int32
atomic.CompareAndSwapInt32(&counter, 10, 20) //尝试将 counter 从 10 修改为 20
1
2
2
# 4、原子操作不可中断性
- CPU会确保在执行这些指令时,其他线程或进程无法访问被操作的内存区域
- 在多核处理器中,CPU会通过缓存一致性协议(如MESI协议)来确保多个CPU核对同一内存地址的访问是同步的
- 即使
多个核心同时尝试对相同的变量进行操作,硬件层面也能确保只有一个核心能成功执行操作
# 5、Mutex使用atomic
sync.Mutex使用了sync/atomic的CAS(Compare And Swap),来进行状态值的读写操作CAS(Compare And Swap) 的做法类似操作数据库时常见的乐观锁机制该操作在进行交换前首先确保被操作数的值未被更改,满足此前提条件下才进行交换操作
eg: 获取锁时的状态检查
- 在这段代码中,
atomic.CompareAndSwapInt32会比较m.state的当前值是否为0(表示锁未被占用) - 如果是,则将
state置为mutexLocked(表示锁已经被占用)
func (m *Mutex) Lock() {
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return // 如果锁未被占用,直接获取锁
}
// 如果锁已经被占用,进行进一步的操作
}
1
2
3
4
5
6
2
3
4
5
6
上次更新: 2025/2/25 11:09:45