 01.Langchain基础
01.Langchain基础
# 00.python环境
- Mac 安装 python
jupyter lab
http://localhost:8888/lab
1
2
2
# -------------------------------
# Step 1: 安装依赖组件
# -------------------------------
brew update
brew install openssl readline sqlite3 xz zlib git
# -------------------------------
# Step 2: 安装 pyenv
# -------------------------------
git clone https://github.com/pyenv/pyenv.git ~/.pyenv
# 写入 ~/.zshrc 或 ~/.bashrc(zsh 用户请使用 zshrc)
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc
echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc
echo 'eval "$(pyenv init --path)"' >> ~/.zshrc
echo 'eval "$(pyenv init -)"' >> ~/.zshrc
source ~/.zshrc
# 验证 pyenv 安装成功
pyenv --version
# -------------------------------
# Step 3: 安装 Python 3.10.13
# -------------------------------
pyenv install 3.10.13
pyenv global 3.10.13
# 验证版本
python --version # 应输出 Python 3.10.13
# -------------------------------
# Step 4: 安装 pyenv-virtualenv(可选但推荐)
# -------------------------------
git clone https://github.com/pyenv/pyenv-virtualenv.git ~/.pyenv/plugins/pyenv-virtualenv
echo 'eval "$(pyenv virtualenv-init -)"' >> ~/.zshrc
source ~/.zshrc
# 创建虚拟环境
pyenv virtualenv 3.10.13 langagent-env
pyenv activate langagent-env
# -------------------------------
# Step 5: 安装核心依赖
# -------------------------------
pip install --upgrade pip setuptools
pip install langchain langgraph openai tiktoken requests
# 安装 deepseek-api 支持(按你之前使用方式)
pip install langchain-openai python-dotenv
# -------------------------------
# Step 6: 验证环境配置
# -------------------------------
python -c "import langchain; import langgraph; print('✅ 环境配置成功!')"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
# 01.Langchain
# 1、LangChain 作用
- LangChain 是一个用于开发大语言模型(LLM)应用的开源框架
- 核心目标是简化 LLM 与外部组件(数据、工具、系统)的集成过程
- 模块化抽象
将 LLM 应用拆解为可复用的组件(模型、提示词、链、记忆、索引等)- 提供标准化接口,降低集成复杂度
- 上下文增强
- 突破模型固有知识限制,
支持接入外部数据源(文档、数据库、API) 实现动态信息检索(如 RAG 架构)
- 突破模型固有知识限制,
- 复杂任务编排
- 通过 "
链(Chains)"将多个步骤串联(如:查询 → 检索 → 生成) - 支持条件分支、循环等逻辑控制
- 通过 "
- 状态管理
维护对话历史(Memory 模块)- 实现多轮对话上下文保持
- 工具集成
- 连接外部 API、计算器、搜索引擎等工具
- 支持智能体(Agents)自主选择工具解决问题
# 2、核心架构
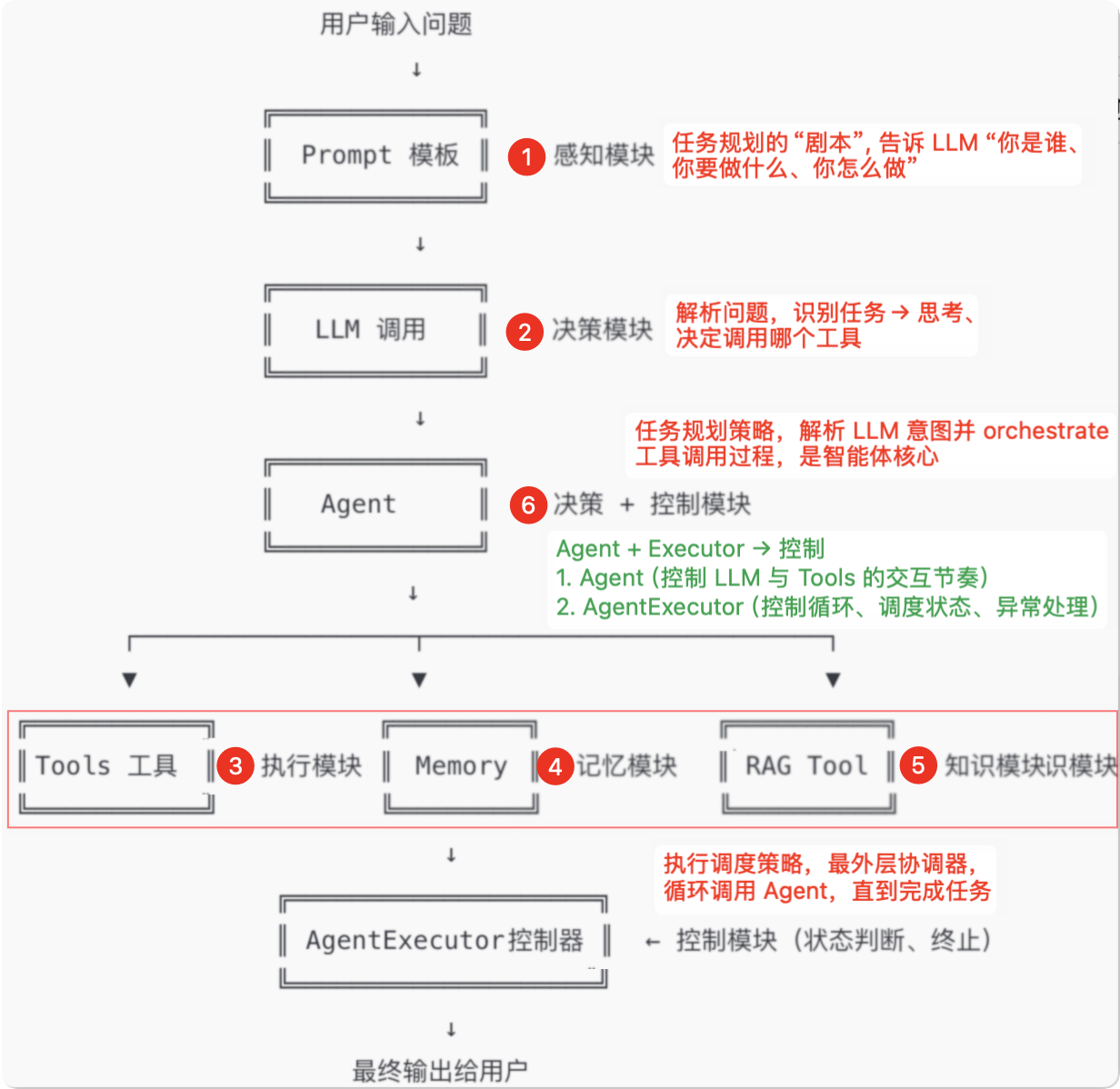
# 1)核心层
| 模块 | 作用 | 示例组件 |
|---|---|---|
| Models | 统一不同 LLM 的调用接口 | OpenAI, HuggingFace, Anthropic |
| Prompts | 动态提示词管理 | PromptTemplate, FewShotPrompt |
| Indexes | 文档加载/分割/向量化 | TextSplitter, Vectorstores |
| Memory | 对话状态维护 | ConversationBufferMemory |
| Output Parsers | 结构化输出解析 | PydanticOutputParser |
# 2)链层(Chains)
原理:将多个组件串联成工作流
类型:
LLMChain:基础链(提示词 + LLM)SequentialChain:顺序执行多链TransformChain:自定义数据处理
# 3)代理层(Agents)
- 原理:LLM 作为 "大脑",动态选择工具执行
- 工作流程:
用户输入 → LLM 决策 → 调用工具 → 观察结果 → 生成最终响应
# 4)关键机制图解
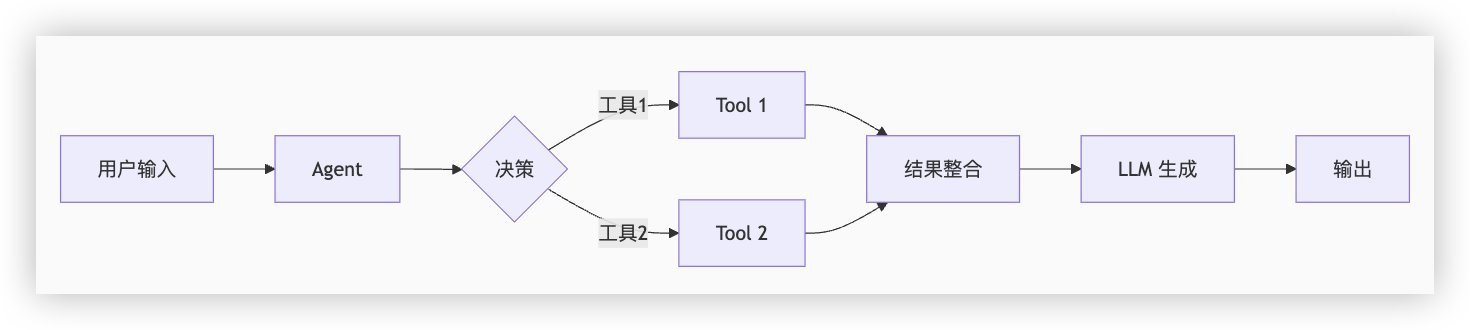
# 3、调用deepseek
pip install langchain langchain-openai python-dotenv # 安装库1
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from dotenv import load_dotenv
DEEPSEEK_API_KEY="xxx"
DEEPSEEK_BASE_URL="https://api.deepseek.com/v1" # DeepSeek API 地址
# 加载环境变量
load_dotenv()
# 初始化 DeepSeek 模型
model = ChatOpenAI(
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
model="deepseek-chat", # 或 "deepseek-coder"
temperature=0.7,
)
# 定义对话模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的人工智能助手"),
("user", "{input}")
])
# 创建链式调用
chain = prompt | model
# 提问并获取响应
response = chain.invoke({"input": "解释量子计算的基本原理"})
print(response.content)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 02.Langchain提示词工程
# 1、提示词模块与历史对话
- 对话系统需要记忆上下文时(如多轮问答),传统单轮Prompt无法保持对话连贯性
- 适用场景:
- 需要参考历史对话的咨询场景(客服机器人需要记住用户之前的问题)
- 实现原理
MessagesPlaceholder预留历史消息位置- 将历史对话以
HumanMessage/AIMessage格式存储 - 新问题触发时,自动拼接完整对话上下文
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
from langchain_community.chat_models import DeepSeekChat
# 创建包含历史记录的提示词
prompt = ChatPromptTemplate.from_messages([
("system", "你是DeepSeek助手,擅长上下文对话"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}")
])
# 模拟历史对话
history = [
HumanMessage(content="Python怎么创建列表?"), # 用户历史提问
AIMessage(content="用方括号[]或list()函数创建,例如: lst = [1,2,3]") # 模型历史回答
]
# 调用DeepSeek
chain = prompt | DeepSeekChat(model="deepseek-chat", temperature=0.7)
# 新问题"那怎么添加元素呢?"会连同历史记录一起发送
response = chain.invoke({
"input": "那怎么添加元素呢?",
"history": history
})
print(response.content)
# 输出:可以使用append()方法添加元素到列表末尾,例如: lst.append(4)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 2、选择器
# 1)长度选择器
- 动态控制提示词长度,避免因示例过多导致token超限
- 适用场景
- 示例数量不确定时,需要根据输入问题长度调整示例数量
- 在有限token预算下最大化信息量
- 例:数学计算器,短问题"1+1"展示3个示例,长问题"请详细解释微积分基本定理"只展示1个示例
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.example_selector import LengthBasedExampleSelector
examples = [
{"input": "2+2", "output": "4"},
{"input": "3*5", "output": "15"},
{"input": "10/2", "output": "5"},
{"input": "2^8", "output": "256"}
]
selector = LengthBasedExampleSelector(
examples=examples,
max_length=30 # 最大token长度, 当输入问题较短时自动多保留示例,较长时少保留
)
dynamic_prompt = FewShotPromptTemplate(
example_selector=selector,
example_prompt=ChatPromptTemplate.from_template("{input} -> {output}"),
prefix="解决数学问题:",
suffix="问题: {question}\n答案:",
input_variables=["question"]
)
print(dynamic_prompt.format(question="100-50"))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 2)相似度选择器
pip install -U langchain-huggingface sentence-transformers chromadb
1
- 从大量示例中快速找到最相关的案例,提升回答准确性
- 适用场景
- 客服机器人
- 用户问:"订单怎么退款" → 自动匹配"退货流程"示例
- 编程助手
- 用户问:"Python怎么连接数据库" → 匹配"MySQL连接示例"
- 客服机器人
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain_community.vectorstores import Chroma
from langchain_huggingface import HuggingFaceEmbeddings # 使用最新版 HuggingFaceEmbeddings
from langchain.prompts import FewShotPromptTemplate, ChatPromptTemplate
# 1. 准备示例数据集(问题-答案对)
examples = [
{"query": "怎么用Python打印Hello World", "answer": "print('Hello World')"},
{"query": "Python如何创建函数", "answer": "def 函数名():\\n [函数体]"},
{"query": "列表怎么排序", "answer": "使用 lst.sort() 或 sorted(lst)"},
{"query": "字典如何按键排序", "answer": "sorted(dict.items())"},
# {"query": "Python读取文件", "answer": "with open('file.txt') as f:\\n content=f.read()"}
]
# 2. 使用 HuggingFace Embeddings(最新版)
embeddings = HuggingFaceEmbeddings(
model_name="shibing624/text2vec-base-chinese", # 中文文本向量化模型
model_kwargs={"device": "cpu"} # 如果没有 GPU,使用 CPU
)
# 3. 创建相似度选择器
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, # 示例列表
embeddings, # 嵌入模型
Chroma, # 向量数据库
k=1 # 返回最相似的1个示例
)
# 4. 构建动态Prompt模板
dynamic_prompt = FewShotPromptTemplate(
example_selector=example_selector, # 使用选择器
example_prompt=ChatPromptTemplate.from_template(
"用户问: {query}\nAI答: {answer}" # 单个示例的格式
),
prefix="根据相似问题回答以下提问:", # 固定前缀
suffix="用户问: {input}\nAI答:", # 固定后缀
input_variables=["input"] # 用户输入变量
)
# 5. 测试不同问题
questions = [
"如何输出一段文字", # 应匹配"打印Hello World"示例
# "怎么让列表倒序", # 应匹配"列表排序"示例
# "处理文本文件的方法" # 应匹配"读取文件"示例
]
for question in questions:
print("=" * 50)
print(f"【用户问题】{question}")
selected_example = example_selector.select_examples({"input": question})
print(f"【匹配到的示例】{selected_example}")
print(f"【最终Prompt】\n{dynamic_prompt.format(input=question)}")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# 3、ChromaDB向量数据库
- 轻量级向量数据库:专为存储和检索向量嵌入(Embeddings)优化,支持相似度搜索
- 核心功能
- 存储文本、图像等数据的向量表示
- 快速检索最相似的条目(基于余弦相似度、欧氏距离等)
- 适用场景
- 轻量、易用、支持持久化,适合中小规模向量搜索场景
- 例:语义搜索(如问答系统)
import chromadb
from sentence_transformers import SentenceTransformer
# 初始化 ChromaDB
client = chromadb.Client() # 内存模式(持久化需指定路径)
collection = client.create_collection("docs")
# 准备数据
documents = [
"Python是一种流行的编程语言",
"机器学习需要大量数据",
"LangChain用于构建LLM应用"
]
# 生成嵌入向量(用 Sentence-Transformers 替代 OpenAI)
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
embeddings = model.encode(documents).tolist()
# 存储到 ChromaDB
collection.add(
documents=documents,
embeddings=embeddings,
ids=["id1", "id2", "id3"]
)
# 相似度查询
query = "如何学习编程?"
query_embedding = model.encode(query).tolist()
results = collection.query(
query_embeddings=[query_embedding],
n_results=2
)
print("最相似的文档:", results["documents"][0])
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 4、对话形式提示词工程
- 对话式提示词工程就是通过精心设计
SystemMessage、HumanMessage、历史AIMessage结构,引导 LLM 精准执行任务 设定角色,使用SystemMessage定义模型身份(如“你是法律顾问”)控制语气风格,通过对 Prompt 编写,控制回复风格、语气、格式引导行为,精准控制模型是否回答、是否引导提问、是否遵循格式
from langchain.chat_models.base import SimpleChatModel
from langchain.schema import HumanMessage, SystemMessage
import requests
# 定义一个简单的 DeepSeek 调用类
class DeepSeekChat(SimpleChatModel):
def __init__(self, api_key: str):
self.api_key = api_key
self.endpoint = "https://api.deepseek.com/v1/chat/completions"
self.model = "deepseek-chat" # 或 "deepseek-coder"
def _generate(self, messages, **kwargs):
# 将 LangChain 格式的消息转为 OpenAI API 风格
msg_payload = []
for msg in messages:
if isinstance(msg, SystemMessage):
role = "system"
elif isinstance(msg, HumanMessage):
role = "user"
else:
role = "assistant"
msg_payload.append({"role": role, "content": msg.content})
payload = {
"model": self.model,
"messages": msg_payload,
"temperature": 0.7
}
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
resp = requests.post(self.endpoint, json=payload, headers=headers)
result = resp.json()
return result["choices"][0]["message"]["content"]
# 初始化模型
llm = DeepSeekChat(api_key="your_api_key_here")
# 构建对话式提示词
messages = [
SystemMessage(content="你是一个风趣幽默的中文老师,善于用生动的例子解释词语。"),
HumanMessage(content="请解释“望梅止渴”的意思。")
]
# 执行对话
reply = llm._generate(messages)
print("模型回复:\n", reply)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 5、模板中的模板
- 例:“根据用户提供的信息,生成一段背景介绍,并让模型基于背景进行角色扮演。”
- 这就包含两层 Prompt:
- 第一层:根据用户信息生成背景(背景生成 Prompt)
- 第二层:基于这个背景进行对话(角色扮演 Prompt)
- 你不希望把两个模板写死在一起,而是希望分开组合、灵活替换 —— 这就是 模板中的模板 的典型场景
from langchain.prompts import PromptTemplate
# 第一层模板:背景描述生成
background_template = PromptTemplate(
input_variables=["name", "job"],
template="以下是{name}的背景资料:\n他是一位{job}。"
)
# 第二层模板:角色扮演对话
conversation_template = PromptTemplate(
input_variables=["background", "question"],
template="""
你需要扮演下列背景中的人物:
{background}
现在回答用户提出的问题:
问题:{question}
回答:
"""
)
# 嵌套执行
background_prompt = background_template.format(name="李白", job="唐朝诗人")
final_prompt = conversation_template.format(
background=background_prompt,
question="你最喜欢的作品是哪一首?"
)
print(final_prompt)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 6、LangChain管道提示词
- 将多个提示词(Prompt)
串联成一个链条或管道(Pipeline) - 每一个提示词用于 LLM 的一个阶段输出,然后把它的输出作为下一个提示词的输入
- 这是一种构建复杂语言处理流程的方式,常用于
- 多步问答
- 数据提取 + 重写
- 多轮对话预处理
- Agent 子任务组合执行
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SimpleSequentialChain
# 第一个 Prompt:生成摘要
summary_prompt = PromptTemplate(
input_variables=["content"],
template="请根据下面的内容生成一段简洁的摘要:\n\n{content}"
)
# 第二个 Prompt:生成标题
title_prompt = PromptTemplate(
input_variables=["summary"],
template="请根据以下摘要起一个吸引人的中文标题:\n\n{summary}"
)
llm = OpenAI(temperature=0.7)
# 第一步链:内容 ➝ 摘要
summary_chain = LLMChain(llm=llm, prompt=summary_prompt)
# 第二步链:摘要 ➝ 标题
title_chain = LLMChain(llm=llm, prompt=title_prompt)
# 顺序链:先摘要再标题
pipeline = SimpleSequentialChain(chains=[summary_chain, title_chain], verbose=True)
# 输入一段文本内容
article_content = "李白是中国唐代著名的浪漫主义诗人,以豪放不羁、想象丰富的诗风著称。他的作品充满了对自然的热爱、对自由的向往和对现实的感慨。"
result = pipeline.run(article_content)
print("\n最终生成的标题:", result)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 03.Langchain大模型输出解析
# 1、缓存加速
- 在 LangChain 中引入缓存机制可以有效
加速响应速度、降低成本、减少重复调用大模型 - 同样的问题多次调用时直接命中缓存返回,避免重复调用 LLM
- 这个示例展示了如何使用
SQLiteCache来缓存响应以加速后续请求
from langchain_openai import ChatOpenAI
from langchain.cache import SQLiteCache
from langchain.globals import set_llm_cache
from langchain_core.prompts import ChatPromptTemplate
from dotenv import load_dotenv
import time
# 设置DeepSeek API配置
DEEPSEEK_API_KEY = "xxx" # 替换为你的实际API密钥
DEEPSEEK_BASE_URL = "https://api.deepseek.com/v1"
# 加载环境变量
load_dotenv()
# 设置SQLite缓存(会在当前目录创建.langchain.db文件)
set_llm_cache(SQLiteCache(database_path=".langchain.db"))
# 初始化DeepSeek模型
model = ChatOpenAI(
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL,
model="deepseek-chat",
temperature=0.7,
)
# 定义对话模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的人工智能助手"),
("user", "{input}")
])
# 创建链式调用
chain = prompt | model
# 测试问题
questions = [
"解释量子计算的基本原理",
"Python中如何实现快速排序?",
"解释Transformer架构的核心思想"
]
for question in questions:
print(f"\n问题: {question}")
# 第一次请求(会调用API并缓存)
start_time = time.time()
response = chain.invoke({"input": question})
elapsed_time = time.time() - start_time
print(f"首次响应时间: {elapsed_time:.2f}秒")
print(f"回答: {response.content[:100]}...") # 只打印前100字符
# 第二次请求(会从缓存读取)
start_time = time.time()
cached_response = chain.invoke({"input": question})
elapsed_time = time.time() - start_time
print(f"缓存响应时间: {elapsed_time:.2f}秒")
print(f"缓存回答: {cached_response.content[:100]}...")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# 2、修复大模型错误输出
import json
from datetime import datetime
from enum import Enum, auto
from langchain_openai import ChatOpenAI
from langchain.cache import SQLiteCache
from langchain.globals import set_llm_cache
from langchain_core.prompts import ChatPromptTemplate
import time
import re
# 1. 设置枚举类型(表示不同的问题类别)
class QuestionType(Enum):
SCIENCE = auto()
PROGRAMMING = auto()
BUSINESS = auto()
def get_system_role(self):
roles = {
QuestionType.SCIENCE: "你是一位资深科学家,请用严谨的学术语言回答",
QuestionType.PROGRAMMING: "你是一位高级程序员,回答需包含可执行的代码示例",
QuestionType.BUSINESS: "你是一位商业顾问,回答需包含可落地的商业策略"
}
return roles.get(self, "你是一个专业助手")
# 2. 配置DeepSeek和缓存
DEEPSEEK_API_KEY = "xxx"
set_llm_cache(SQLiteCache(database_path=".langchain.db"))
model = ChatOpenAI(
api_key=DEEPSEEK_API_KEY,
base_url="https://api.deepseek.com/v1",
model="deepseek-chat",
temperature=0.7,
)
# 3. 错误修正函数
def fix_common_errors(text):
"""修正大模型常见输出问题"""
# 修复Markdown代码块格式
text = re.sub(r"```(?!\w)", "```python", text)
# 移除多余的空行
text = re.sub(r"\n{3,}", "\n\n", text)
# 修正错误单位 (示例: 把1GB=1000MB改为1GB=1024MB)
text = text.replace("1GB=1000MB", "1GB=1024MB")
return text.strip()
# 4. 创建对话链
def build_chain(question_type):
prompt = ChatPromptTemplate.from_messages([
("system", f"{question_type.get_system_role()}。若涉及专业术语请中英文对照说明"),
("user", "{input}")
])
return prompt | model
# 5. 测试问题集
questions = [
("量子计算比传统计算机快多少?", QuestionType.SCIENCE),
("用Python写快速排序并解释", QuestionType.PROGRAMMING),
("初创公司如何获得天使轮融资?", QuestionType.BUSINESS),
]
# 6. 处理问题并生成JSON结果
results = []
for question, q_type in questions:
chain = build_chain(q_type)
start_time = time.time()
try:
response = chain.invoke({"input": question})
content = fix_common_errors(response.content)
except Exception as e:
content = f"API错误: {str(e)}"
elapsed_time = time.time() - start_time
results.append({
"metadata": {
"timestamp": datetime.now().isoformat(),
"question_type": q_type.name,
"processing_time": f"{elapsed_time:.2f}s",
"is_cached": getattr(response, "from_cache", False)
},
"input": question,
"output": content,
"analysis": {
"response_length": len(content),
"has_code_block": "```" in content,
"term_pairs": len(re.findall(r"\(([A-Za-z]+)\)", content)) # 统计中英文术语对
}
})
# 7. 输出JSON结果
json_output = {
"engine": "deepseek-chat",
"cache_enabled": True,
"results": results
}
# 保存到文件
with open("ai_responses.json", "w", encoding="utf-8") as f:
json.dump(json_output, f, indent=2, ensure_ascii=False)
print("JSON结果已保存,示例输出结构:")
print(json.dumps(json_output["results"][0], indent=2, ensure_ascii=False))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
# 3、自定义大模型的输出解析器
解析和标准化大模型的输出,使其符合你的应用需求,例如:
结构化输出(如提取关键信息、自动修正错误)
格式统一(如确保代码块、术语一致性)
增强可读性(如去除冗余内容、优化排版)
应用场景
聊天机器人 → 让回答更简洁、专业
知识库问答 → 自动提取关键信息(如日期、代码示例)
from langchain_core.output_parsers import BaseOutputParser
class SimpleParser(BaseOutputParser[str]):
def parse(self, text: str) -> str:
"""只保留第一段,并移除多余空格"""
first_paragraph = text.split("\n\n")[0] # 取第一段
return " ".join(first_paragraph.split()) # 移除多余空格
# 使用示例
raw_output = " 量子计算是一种... \n\n 详情参考:某论文 "
parser = SimpleParser()
clean_output = parser.parse(raw_output)
print(clean_output) # 输出: "量子计算是一种..."
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14