 03.k8s与容器底层
03.k8s与容器底层
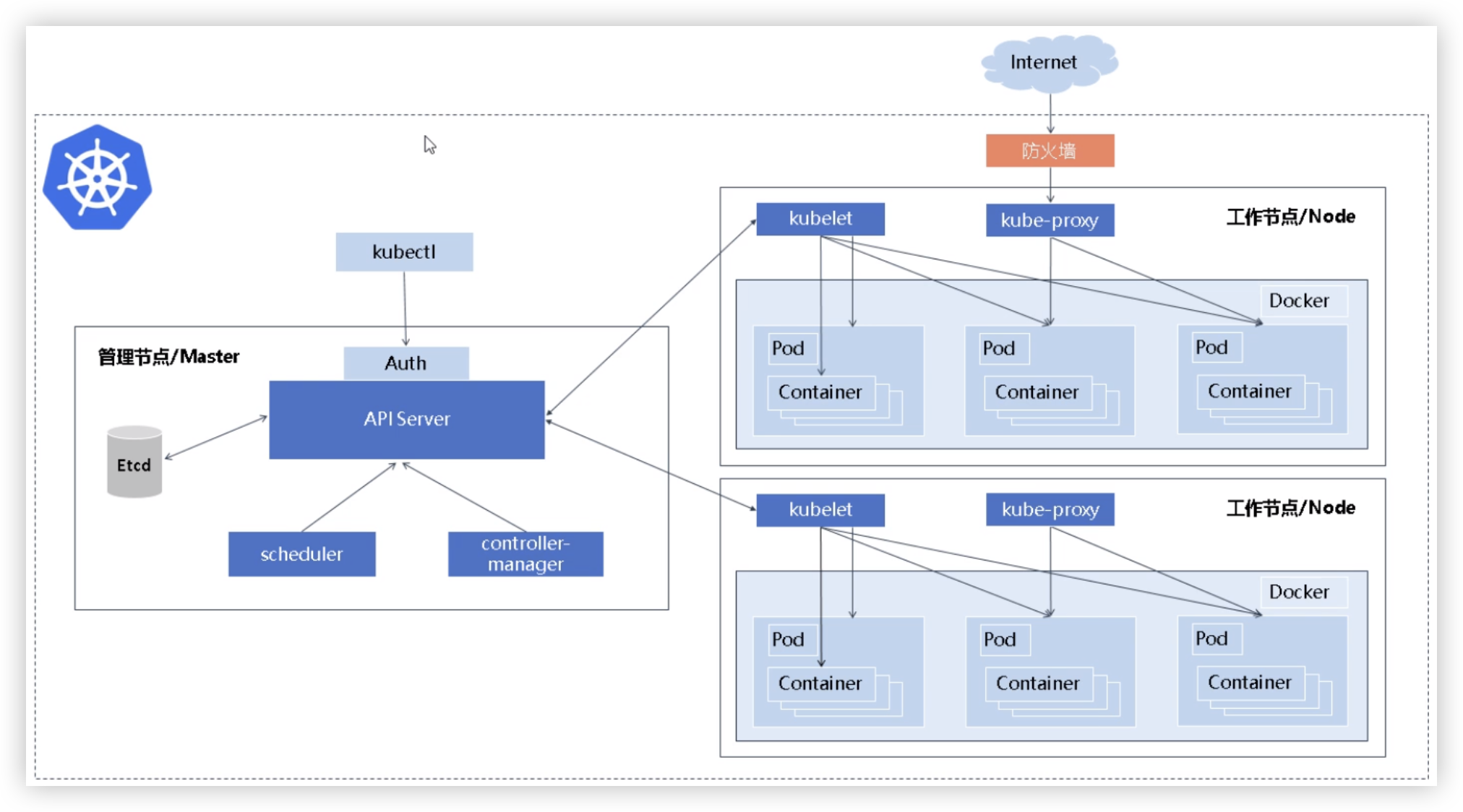
# 01.Kubernetes 与容器底层
# 1、K8S工作原理
① 部署应用:
- 开发者提交应用描述文件(YAML格式)到API Server
- 指定Pod、Service、ConfigMap等资源的期望状态
② API Server处理请求:
- API Server 接收到请求后,首先将应用描述文件中的信息存储在etcd中,确保集群状态数据的一致性
③ 调度器决定节点分配:
- Scheduler 读取etcd中存储的应用期望状态
- 并根据当前集群中节点的资源利用情况,选择最合适的节点运行Pod
④ Kubelet拉起容器:
- Kubelet接收到Scheduler的指令后
- 通过容器运行时(如Docker或containerd)拉取指定镜像并启动容器
⑤ 服务发现与负载均衡:
- Kube-proxy设置相应的网络规则
- 使应用服务能够被外部访问或在内部Pod之间进行通信
⑥ 自动扩缩容和故障恢复:
- Controller Manager持续监控Pod的运行状态
- 并在Pod故障或节点失效时自动创建新的副本或迁移Pod
# 2、Pod生命周期
一、用户触发创建请求
1.用户提交 Pod 创建请求
入口:通过
kubectl、controller(如 Deployment)或直接调用API Server 接口操作对象:创建一个新的
Pod对象,状态初始为Pending
2.API Server 处理请求
校验后将 Pod 对象存入 etcd,Pod 初始状态为
Pending若无
NodeName字段,则表示该 Pod 尚未调度
二、调度阶段(Scheduler)
3.Scheduler 监听未调度的 Pending Pod
通过
Informer + Watch从 API Server 监听新创建但未调度的 Pod(.spec.nodeName == nil)将其加入调度队列
4.预选(Filtering)阶段
基于 Pod 的资源请求(CPU/内存)、污点容忍、亲和性、NodeSelector 等规则
剔除不满足条件的节点,留下候选节点列表
5.优选(Scoring)阶段
为候选节点打分,考虑
- 副本均衡分布(Anti-Affinity)
- 最小资源使用率
- 节点负载、拓扑感知等
选择得分最高的目标节点
6.绑定(Binding)阶段
Scheduler 调用
API Server的Bind接口,将NodeName写入 Pod 的.spec.nodeName字段API Server 更新 etcd 中的 Pod 对象,完成调度
事件链:Pending → Binding → Bound
三、节点侧容器创建(Kubelet)
7.kubelet 监听本节点上的 bound Pod
每个节点的
kubelet通过watch/list监听 etcd 中与本节点绑定的 Pod 信息发现新 Pod 后开始拉取镜像、准备启动容器
8.容器运行准备
拉取容器镜像(镜像缓存优化)
创建 sandbox(Pause 容器)进行网络/namespace 设置
启动业务容器
执行探针(liveness/readiness)初始化
9.Pod 状态上报
kubelet 通过
PodStatus上报运行状态给 API ServerPod 状态从
Pending转为Running
四、生命周期的事件
10.Pod 生命周期状态机(状态更新路径)
Pending:Pod 对象已存在,尚未完成调度或容器未创建Running: Pod 已调度,至少一个容器正在运行Succeeded所有容器成功退出(退出码为 0,且restartPolicy != Always)Failed有容器异常终止(非 0),不会重启Unknown: 控制平面无法联系节点,Pod 状态未知
11.Pod 生命周期中的关键事件链
用户提交创建请求 ↓ API Server 存入 etcd ↓ Scheduler 监听发现 Pending Pod ↓ 过滤、打分、绑定节点 ↓ API Server 更新绑定信息至 etcd ↓ Kubelet 监听并创建容器 ↓ 容器运行,状态回写 API Server ↓ Pod 状态转为 Running ↓ (后续由容器运行结果决定是否转为 Succeeded/Failed)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 3、预选/优选
- Scheduler 的整体流程和工作机制(预选/优选)?
1.调度器的触发机制- 调度器通过 Informer 监听 API Server 中的新建、未绑定(
.spec.nodeName为空)的 Pod,当发现新的调度请求后,会进入主调度流程 - 在源码中,这一过程是通过
scheduleOne()函数驱动的
- 调度器通过 Informer 监听 API Server 中的新建、未绑定(
2.预选阶段(Filtering,也叫 Predicates)- 这个阶段的目标是过滤掉不合适的节点,从而得到一个候选节点列表
- 例如,会基于以下条件做过滤:
- 资源是否足够(如 CPU、内存)
- 节点是否有污点(taints)不可容忍
- Pod 的 nodeSelector / nodeAffinity 是否匹配
- 卷(volume)是否存在冲突
- 节点是否处于压力状态(memory、PID、disk)
- 调度器会依次调用多个 Filter 插件(如
NodeResourcesFit,TaintToleration,NodeAffinity等),最终输出一组符合条件的候选节点 - 这部分对应源码中的
framework.RunFilterPlugins()
3.优选阶段(Scoring,也叫 Priorities)- 如果预选阶段得到多个候选节点,那么调度器会继续对这些节点打分排序,从中选出“最合适”的节点
- 常见的 Scoring 策略包括:
- LeastRequestedPriority:倾向于资源使用较少的节点
- BalancedResourceAllocation:倾向于 CPU 和内存使用均衡的节点
- SelectorSpreadPriority / EvenPodsSpread:实现 Pod 分散策略,提升可用性
- NodeAffinityPriority:支持软约束 node affinity
- TaintTolerationPriority:偏向污点少、能被容忍的节点
- ImageLocalityPriority:偏向已有镜像缓存的节点,提升调度速度
- 每个 Score 插件会返回一个 0~100 的分数,最后 scheduler 会根据加权得分选出最高的那个节点作为调度目标
- 源码关键路径
framework.RunScorePlugins()
4.绑定阶段(Bind)- 选中节点后,调度器会通过 API 调用把 Pod 的
spec.nodeName设置为目标 Node,并记录调度结果 - 这个阶段还会触发
PreBind/Bind插件,例如支持做 volume 的绑定 - 对应函数为:
framework.RunPreBindPlugins()binder.Bind()
- 选中节点后,调度器会通过 API 调用把 Pod 的
5.容错机制- 如果在预选阶段没有一个节点满足条件,调度器不会直接失败,而是会将该 Pod 保持在 Pending 状态,并在后续节点状态变更时重试调度
6.调度器的可扩展性- Kubernetes 的调度器基于 Scheduler Framework 插件机制,支持开发自定义的 Filter / Score / Bind 插件,也可以通过 extender 机制接入外部调度逻辑
- 另外,我们也可以使用
schedulerName字段定义自定义调度器,比如运行多个 scheduler 实例来调度不同业务 Pod
所以总结来说,kube-scheduler 的核心逻辑是“先过滤不合适节点,再对剩下的节点打分选择最优”
整个流程基于插件框架实现,既保障了调度的通用性,也具备很强的可扩展性
我平时在阅读 scheduler 代码时主要看了 pkg/scheduler/scheduler.go 中的 scheduleOne() 函数
它是整个调度循环的核心入口
预选和优选通过 framework 的插件链实现,我也实现过自定义的 Score 插件,支持根据 GPU 占用率打分,接入我们内部的资源预测平台
2
3
4
5
# 3、kubelet 管理 Pod
Kubelet的核心职责
是运行在每个Node上的代理,负责确保Pod中的容器按预期运行
直接与容器运行时(如Docker、containerd)交互,同时与API Server通信
# 1)Pod生命周期管理
Pod生命周期管理 kubelet通过以下机制管理Pod的完整生命周期
1.Pod来源
API Server:监听分配给当前Node的Pod(通过Watch机制)
静态Pod:直接管理
/etc/kubernetes/manifests目录下的Pod定义文件(如kube-apiserver自身)
2.Pod创建流程
获取Pod配置:从API Server或本地文件加载Pod定义(YAML/JSON)
依赖检查:确保Node满足Pod需求(资源、端口、Volume等)
拉取镜像:通过容器运行时从镜像仓库拉取所需镜像(支持私有仓库鉴权)
创建容器:调用CRI(Container Runtime Interface)创建容器,按定义顺序启动(若有
initContainer则先执行)状态上报:持续向API Server汇报Pod状态(如
Pending、Running、Failed)
3.Pod终止流程
优雅终止:
- 收到删除请求后,kubelet发送
SIGTERM到容器 - 等待
terminationGracePeriodSeconds(默认30秒),超时后强制终止(SIGKILL)
- 收到删除请求后,kubelet发送
清理资源:删除容器、释放Volume、网络等资源
4.健康检查
Liveness Probe:失败时重启容器
Readiness Probe:失败时从Service端点移除Pod
Startup Probe:确保慢启动容器在初始化期间不被kill
# 2)Pod资源分配
资源管理 kubelet通过以下机制确保Pod资源合理分配
1.资源分配
Requests/Limits:根据Pod定义的
requests和limits分配CPU、内存等资源Ephemeral Storage:临时存储(日志、emptyDir)的请求和限制
2.资源隔离
使用Linux内核特性(如cgroups、namespaces)隔离容器资源
支持
QoS分级:Guaranteed(两者均设且相等) >Burstable(部分设置) >BestEffort(未设置)
4.资源回收
内存压力:按QoS优先级逐级驱逐Pod(
BestEffort最先被驱逐)磁盘压力:清理未使用的镜像、死容器、临时文件等
④ 关键组件协作CRI:通过标准化接口操作容器运行时(如containerd)
CNI:配置Pod网络(如Calico、Flannel)
CSI:管理持久化存储卷(如AWS EBS)
⑤ 故障处理与监控日志收集:通过
kubectl logs或日志代理(如Fluentd)获取容器日志事件上报:记录关键事件(如
FailedScheduling、Unhealthy)到API ServerMetrics:暴露资源使用指标(如CPU、内存)供Prometheus采集
# 4、核心组件
# 1)Controller Manager
- Controller Manager —— 资源控制与状态修复引擎
一、核心职责
- 维护k8s 系统中各种资源的
期望状态(Spec)与实际状态(Status)一致 - 每种控制逻辑封装成一个独立的 controller 模块
- ReplicaSetController:确保
副本数量一致 - NodeController:
处理节点失联、心跳异常 - DeploymentController:
管理滚动更新 - Job / DaemonSet / StatefulSetController:
处理有状态/批量任务
- ReplicaSetController:确保
二、工作机制
- 基于 Informer 机制,监听资源(如 Pod、Node、ReplicaSet、Deployment 等)的变更事件
- 检查当前状态是否偏离期望状态(如副本数不一致、Pod 不在预期 Node 上)
- 若不一致,调用 API Server 发起修复操作,如创建/删除 Pod、调整副本、驱逐节点等
# 2)kube-scheduler(Scheduler)
kube-scheduler 负责将
Pending 状态的 Pod 分配到合适的 Node工作流程分两步:
预选(Predicates):过滤不合适的节点,如资源不足、Label 不匹配、Taints 不容忍优选(Priorities):对剩余节点打分排序,如资源富余、Pod 亲和性、镜像本地化等
调度完成后通过
bind操作把 Pod 分配给目标 Node,等待 kubelet 接收调度结果
# 3)Informer
- Informer
不是一个独立的服务,也不是每个 Node 上都有的组件- 通常被集成在
k8s 控制器(controller)、调度器(scheduler)、Operator 或其他控制面组件中运行- ⚠️ 注意:Informer 是监听 API Server 的变化,不是直接监听 etcd
什么是 Informer?
- Informer 是 Kubernetes 中一种
高效监听资源变化的机制 - 监听某类资源(比如 Pod、Node、Deployment)的
创建、更新、删除事件 - 将这些事件
异步处理,驱动 controller 或其他逻辑工作 缓存对象数据,减少 API Server 压力,提高处理性能
- Informer 是 Kubernetes 中一种
Informer 的工作原理(简单理解)
Informer 启动时,先向 API Server 请求一次全量数据(比如所有 Pod),用于初始化本地缓存
然后,Informer 会通过 API Server 的 Watch 接口建立长连接,实时接收资源的变化事件(Add/Update/Delete)
变更事件存入本地队列(WorkQueue)供 controller 或 handler 异步处理
优势
- 高性能(相比轮询)
- 实时性强
- 内置缓存(可降低 API Server 压力)
总结一句话:
controller-manager负责资源状态控制;scheduler负责 Pod 到节点的调度决策;Informer是三者协同的基石,用于实时监听资源变更并触发对应逻辑
# 5、定制调度器
如何定制调度器(自研调度器、自定义调度策略、自定义 kubelet)?
# 1)自研调度器(Custom Scheduler)
Kubernetes 支持并行多个调度器
使用方式:
Pod 通过
spec.schedulerName字段指定调度器名自定义调度器可以监听未绑定的 Pod,进行绑定
实现步骤:
监听
API Server上状态为Pending且schedulerName=xxx的 Pod实现预选/优选逻辑(可定制打分算法)
使用
client-go发起bind请求将 Pod 绑定到目标 Node
典型场景:
金融/安全行业对资源隔离或节点特殊性有强需求
实现 GPU-aware、NUMA-aware 等调度
# 2)自定义调度策略(扩展 kube-scheduler)
Kubernetes 支持通过插件机制扩展原生调度器逻辑
插件类型:
Filter Plugin(替代 Predicates)
Score Plugin(替代 Priorities)
Bind Plugin(自定义绑定逻辑)
Reserve/PreScore/Permit 等插件
实现方式:
编写 Go 插件实现对应接口(如
framework.ScorePlugin)在
kube-scheduler配置文件中注册插件编译并部署带插件的
kube-scheduler
优点:
- 保留原生调度器所有能力,只扩展你的需求